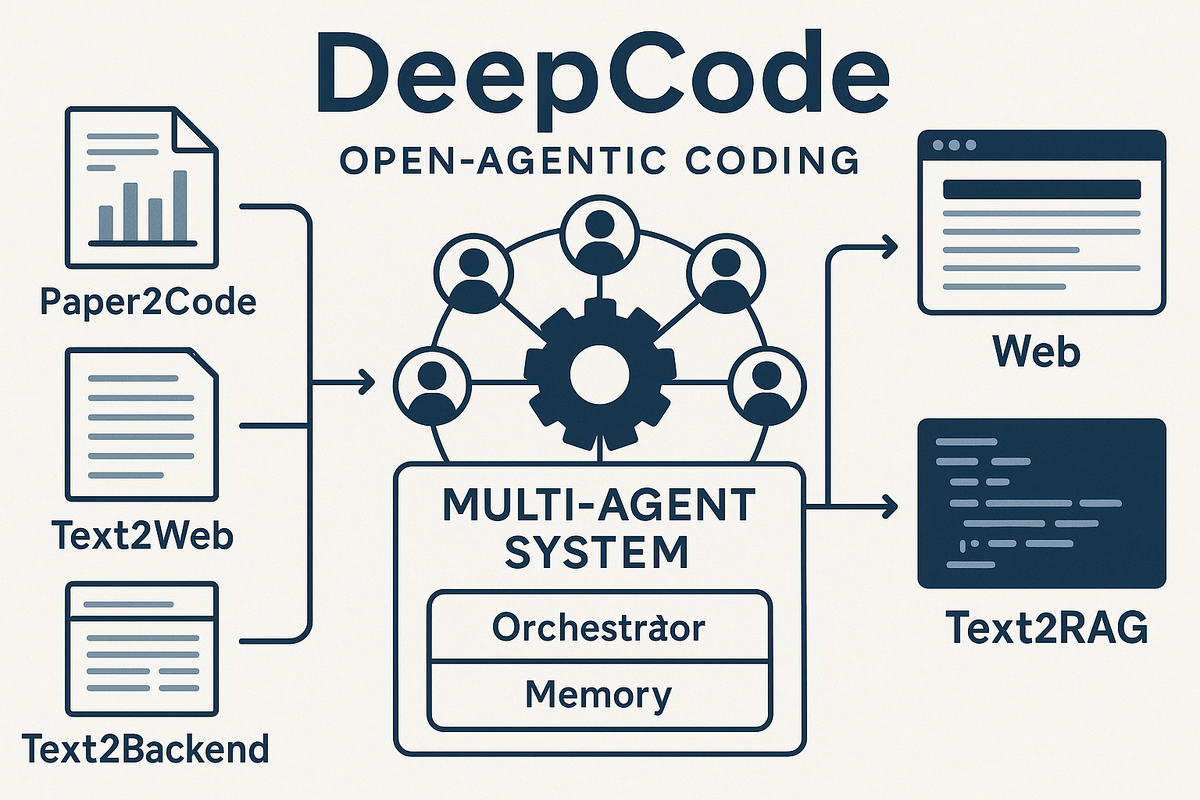
За последние годы мы привыкли к LLM, которые умеют дописывать функции и помогать в рефакторинге. Но проект DeepCode из Гонконгского университета пошёл дальше: он предлагает полноценную мультиагентную платформу, превращающую научные статьи и текстовые описания в production-ready код.
Звучит как фантастика, но архитектура DeepCode действительно впечатляет.
🧠 В чём суть
DeepCode реализует три ключевых сценария:
- 📑 Paper2Code — извлечение алгоритмов из PDF статей и их автоматическая реализация в коде.
- 🌐 Text2Web — генерация фронтенда по текстовому описанию интерфейса.
- ⚙️ Text2Backend — генерация бэкенда (эндпоинты, базы данных, бизнес-логика) из требований.
В отличие от привычных «кодовых ассистентов», здесь работает оркестратор, который распределяет задачи между агентами:
- один агент парсит документы,
- другой извлекает требования,
- третий строит архитектуру,
- четвёртый ищет код-референсы в GitHub,
- пятый синтезирует итоговую реализацию.
Получается система с распределённым интеллектом, где каждый агент узко специализирован, но вместе они закрывают весь цикл от идеи до работающего прототипа.
⚡ Технические фишки, которые впечатляют
- 🧬 CodeRAG — Retrieval-Augmented Generation для кода: поиск и интеграция готовых решений из больших репозиториев.
- 💾 Иерархическая память — умное хранение и сжатие контекста, что позволяет работать с крупными кодовыми базами без «забывания».
- 🔍 Граф зависимостей — индексация и понимание архитектурных паттернов в больших проектах.
- 🛡️ Автоматическое тестирование — система сразу генерирует юнит-тесты и документацию.
Это выглядит как попытка совместить идеи Data Mesh, LLM-оркестрации и инфраструктуры для reproducible science.
🧐 Моё видение
Мне особенно интересно, что DeepCode решает проблему разрыва между научными публикациями и реальным продакшеном. Обычно новый алгоритм проходит долгий путь: от PDF → до кода на GitHub → до библиотеки → до внедрения в продукты. DeepCode сокращает этот цикл до часов.
Проблема, конечно, остаётся — валидация качества кода. Автоматически сгенерированный код может быть синтаксически верным, но при этом неэффективным или небезопасным. Здесь важен баланс: агенты берут на себя «рутинную черновую работу», а человек остаётся архитектором и аудитором.
Если платформа дорастёт до массового использования, мы получим новый уровень автоматизации R&D: исследователь будет тратить время не на «переписывание формул в Python», а на проверку гипотез и улучшение идей.
🔮 Куда это может привести
- 🧑🔬 Учёные будут быстрее воспроизводить результаты друг друга.
- 🏗️ Стартапы смогут за дни собирать MVP на основе описания идеи.
- 🛡️ Появится больше инструментов для автоматической проверки качества кода.
- 🌍 Возможно, возникнет новый стандарт: «исследование → код» как единый пакет, без промежуточных ручных шагов.
📌 Источник:
- Репозиторий проекта: DeepCode на GitHub