
В эпоху, когда крупные модели ИИ становятся «чёрными ящиками», проект LLMs-from-scratch от Себастьяна Раски даёт нам редкий шанс взглянуть под капот. В свежем разделе появилась чистая реализация Gemma 3 270M на PyTorch — без сторонних библиотек, без скрытых оптимизаций, полностью открытый код.
🔧 Что в этом особенного
- 🐍 Чистый PyTorch: никакого Triton, FlashAttention или Hugging Face Transformers. Это значит, что каждый слой, от эмбеддингов до self-attention, написан вручную.
- 📦 Лёгкая модель: 270M параметров, всего ~2 ГБ памяти для запуска — доступно даже на ноутбуке.
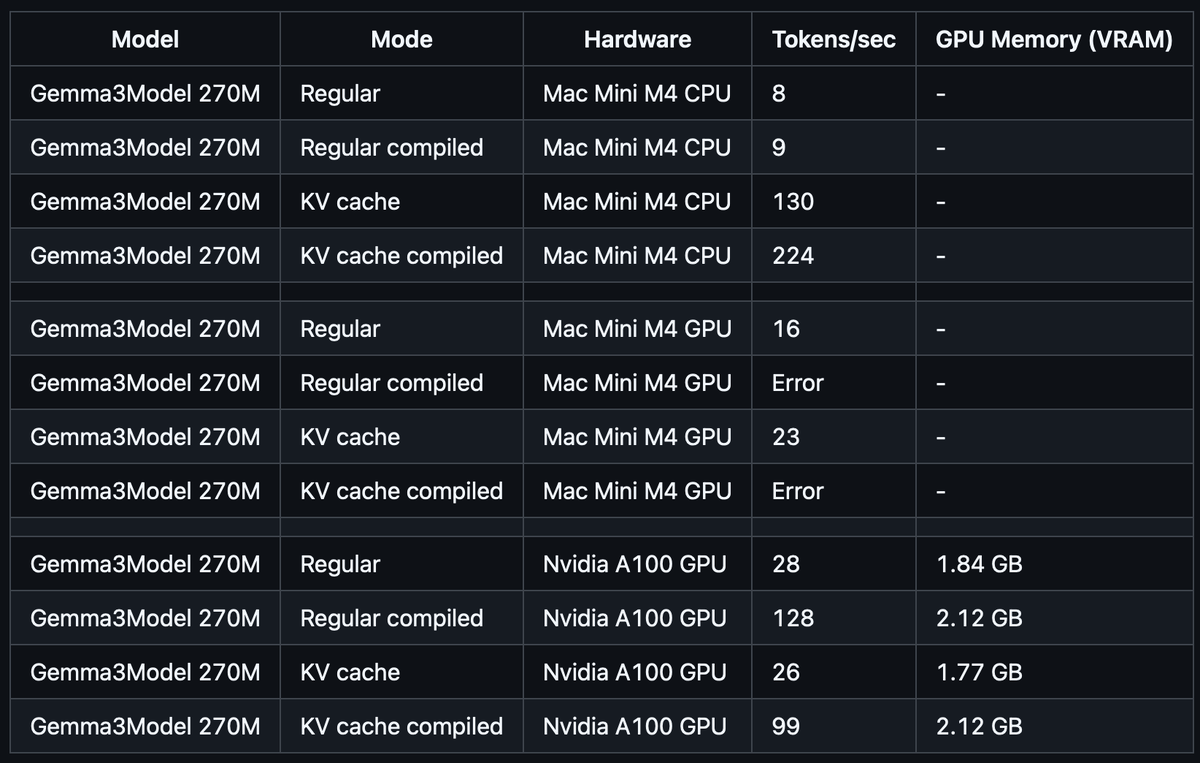
- ⚡ Поддержка KV-кэша: отдельный ноутбук реализует кеширование ключей/значений, что ускоряет генерацию в десятки раз (на Mac Mini с M4 CPU — с 8 до 130 токенов/сек).
- 🎛️ Сравнительные тесты: приведены цифры для CPU, GPU (A100) и Apple Silicon — отличный материал для тех, кто хочет понять, где именно «просаживается» производительность.
🧠 Почему это важно
Большинство разработчиков знакомы с LLM только через высокоуровневые API. Но такие проекты позволяют:
- 🔍 изучить архитектуру на уровне кода, а не диаграмм;
- 🧑💻 экспериментировать с изменениями (например, добавить свою нормализацию или поиграть с attention-механикой);
- 📚 использовать как учебное пособие — от студентов до инженеров в продакшне.
🤔 Моё мнение
Я считаю такие реализации ключевыми для будущего индустрии. Огромные закрытые модели — это здорово для бизнеса, но прозрачность и доступность экспериментов определяют, появятся ли новые идеи в архитектуре. KV-кэш, который здесь реализован вручную, — отличный пример: когда понимаешь механику, начинаешь иначе смотреть и на оптимизацию, и на компромиссы в дизайне LLM.
Это напоминает историю Linux: когда-то «игрушечная ОС» для студентов стала ядром мировой инфраструктуры. Кто знает, может именно такие «from scratch»-проекты сегодня закладывают основу будущего поколений ИИ.
🔗 Источник: Gemma 3 270M re-implemented in pure PyTorch
📚 Дополнительно: KV Cache в LLMs from Scratch, The Big LLM Architecture Comparison