🚀 NVIDIA ускорила LLM в 53 раза 🤯
Представь: твой бюджет на инференс снижается на 98%, а точность остаётся на уровне лучших моделей.
📌 Как это работает:
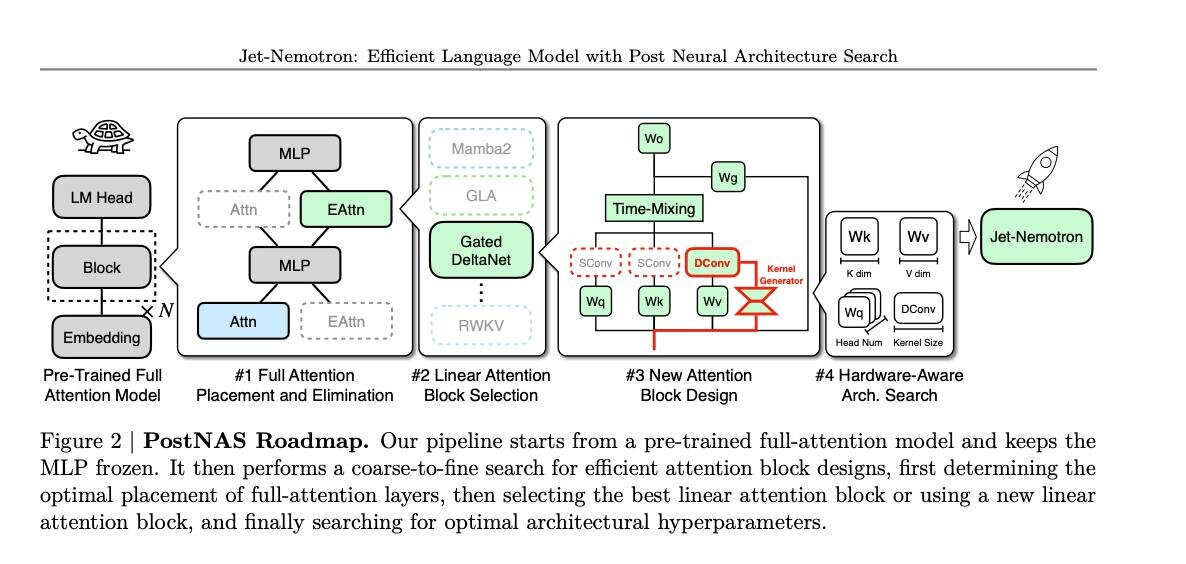
Метод называется Post Neural Architecture Search (PostNAS) — революционный подход к «апгрейду» уже обученных моделей.
Freeze the Knowledge — берём мощную модель (например, Qwen2.5) и «замораживаем» её MLP-слои, сохраняя интеллект.
Surgical Replacement — заменяем большую часть медленных O(n²) attention-слоёв на новый супер-эффективный дизайн JetBlock с линейным вниманием.
Hybrid Power — оставляем несколько full-attention слоёв в критичных точках, чтобы не потерять способность к сложным рассуждениям.
⚡ Результат - Jet-Nemotron:
- 2 885 токенов/с ⚡
- 47× меньше KV-кеша (всего 154 MB)
- Топовая точность при космической скорости
🔑 Почему это важно:
Для бизнеса: 53× ускорение = 98% экономии на масштабном развёртывании. ROI проектов с ИИ меняется радикально.
Для инженеров: теперь SOTA-уровень доступен даже на устройствах с ограниченной памятью.
Для исследователей: вместо миллионов на пре-трейнинг — можно создавать новые эффективные модели через архитектурные модификации.