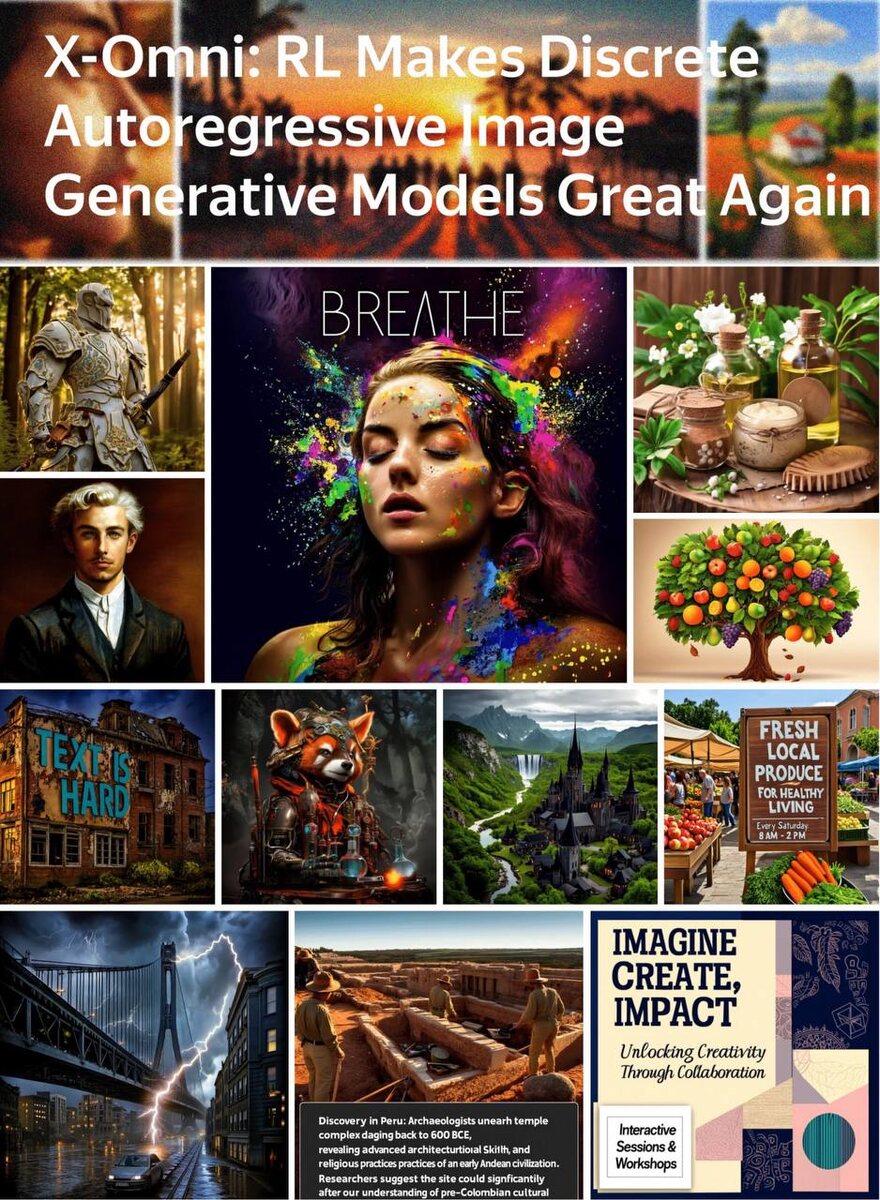
🎨 X-Omni от Tencent — прорыв в генерации изображений по тексту Новая модель X-Omni показала, как reinforcement learning может вывести text-to-image технологии на новый уровень. 💡 В основе: — SigLIP-VQ — токенизация изображений — Qwen2.5-7B — обработка мультимодальных данных — FLUX.1-dev — диффузионный декодер для финального рендера 📌 Фишки X-Omni: — Идеально рендерит надписи (особенно на китайском) — Оценивает результат по эстетике, смыслу и читаемости — Работает стабильно без CFG — редкость для подобных моделей — Уже обгоняет GPT-4o в тестах на текстовых изображениях 🔗 Подробнее: x-omni-team.github.io 👉 Больше новинок из мира ИИ — в моём канале: https://dzen.ru/id/670c7fe545d6d72caa724e37
🎨 X-Omni от Tencent — прорыв в генерации изображений по тексту
Новая модель X-Omni показала, как reinforcement learning может вывести text-to-image технологии на новый уровень.
💡 В основе:
— SigLIP-VQ — токенизация изображений
— Qwen2.5-7B — обработка мультимодальных данных
— FLUX.1-dev — диффузионный декодер для финального рендера
📌 Фишки X-Omni:
— Идеально рендерит надписи (особенно на китайском)
— Оценивает результат по эстетике, смыслу и читаемости
— Работает стабильно без CFG — редкость для подобных моделей
— Уже обгоняет GPT-4o в тестах на текстовых изображениях
🔗 Подробнее: x-omni-team.github.io
👉 Больше новинок из мира ИИ — в моём канале: https://dzen.ru/id/670c7fe545d6d72caa724e37