Как менеджменту выстроить внедрение AI поэтапно и не застрять
Когда менеджеры говорят об ИИ, звучат два типа вопросов.
- Технический: Как внедрить нейросети, какие модели использовать?
- Политико-организационный: Кто этим управляет, с чего начать, как не уйти в песочницу?
Но реальный вопрос глубже.
ИИ это не просто технология. Это новый способ думать, решать, взаимодействовать. И, как всё системное, он не развивается линейно.
Большинство компаний представляют внедрение ИИ как лестницу: вот мы начали с ChatGPT, потом сделаем своих агентов, потом обучим нейросеть, и здравствуй, будущее.
Но на практике это не лестница. Это две переплетённые спирали, два потока:
- Технологический, инфраструктурно-данный.
Здесь решаются вопросы: "Где наши данные?", "Как их обрабатывать?", "Где пайплайны и модели?" - Функциональный, агентный.
Здесь создаются ИИ-ассистенты, агенты, интерфейсы, взаимодействия. То, что видит пользователь.
ИИ в компании это не проект, а переход. И он идёт не по лестнице.
Они развиваются параллельно, но с разной скоростью. И если вы слишком сильно уедете по одному потоку, не развивая другой получите либо эффектную витрину без фундамента, либо мощную платформу без пользы и принятия.
В этой статье я раскладываю:
- Что это за два потока?
- Какие этапы проходит каждый?
- Какой чек-лист должен быть у менеджера на каждом уровне?
- Как понять, где вы застряли и что не даёт перейти на следующий уровень?
Если вы руководитель, PM, BA, C-Level, архитектор трансформации или владелец бизнеса, эта карта поможет вам перестать спрашивать “где внедрить ИИ?” и начать управлять его эволюцией.
Две спирали внедрения
ИИ это не “инструмент”. Это экосистема решений, ролей и инфраструктуры. И она развивается по двум параллельным траекториям (я опустил организационную траекторию, т.к. это требует отдельного рассмотрения), которые условно можно назвать:
- Data-поток. Отвечает за то, на чём работает интеллект: данные, пайплайны, модели, вычислительные мощности.
- Agent-поток. Отвечает за то, как интеллект взаимодействует с людьми: агенты, интерфейсы, цифровые роли.
Эти потоки не обязаны идти строго последовательно, но они влияют друг на друга. Агент без данных просто симуляция. Платформа без интерфейса - склад без дверей.
Разберём каждый поток по этапам. Покажем, какие задачи стоят на каждом уровне. И что должен держать в голове менеджер, чтобы не строить ИИ “в стол”.
Спираль Data-потока
ИИ производная от данных, циклов обработки и инфраструктуры. Именно поэтому зрелость по этому потоку критична для масштабирования.
* * *
Этап I. Data Awareness & Availability
Что происходит:
Компания осознаёт, что данные это актив. Начинается картирование: где они лежат, в каком виде, кто отвечает. Появляется желание “сделать ML”.
Ключевые задачи:
- Создать карту данных по функциям и процессам
- Определить приоритетные домены (финансы, продажи, HR)
- Понять правовой статус: кто владеет, как хранятся, где утечки
Чек-лист для менеджмента:
- У вас есть актуальная карта данных?
- Известны бизнес-домены, где ML даст эффект за 3-6 месяцев?
- Понимаете, какие данные нельзя использовать (персональные, чувствительные)?
* * *
Этап 2: DataOps / MLOps
Что происходит:
Переход от “сделать модель” к “управлять жизненным циклом моделей”. Появляются пайплайны, DevOps для AI, мониторинг качества.
Ключевые задачи:
- Внедрить CI/CD для моделей
- Настроить мониторинг: что происходит с моделью после запуска?
- Назначить ответственных: кто “держит в руках” ML-сервис?
Чек-лист:
- У вас есть CI/CD-процессы для ML?
- Кто отвечает за “баги” моделей в продакшене?
- Как вы определяете, что модель устарела?
* * *
Этап 3: Proprietary Models
Что происходит:
Появляется желание (или необходимость) обучить свои модели: либо на своих данных, либо под свои задачи. Часто это fine-tuning LLM.
Ключевые задачи:
- Определить целесообразность: зачем своя модель?
- Выбрать архитектуру: open source, LLM, small models
- Настроить контроль за этикой, безопасностью и качеством
Чек-лист:
- У вас есть обоснование: почему не хватит GPT или Claude?
- Кто будет отвечать за корректность и безопасность модели?
- Есть ли внутренняя команда или партнёр под обучение?
* * *
Этап 4: Orchestration Layer
Что происходит:
AI становится не точкой, а платформой. Модели, данные, процессы объединяются. Возникают правила взаимодействия, API, доступы.
Ключевые задачи:
- Построить единую архитектуру: как модели взаимодействуют с данными и продуктами
- Внедрить слой оркестрации: управление, приоритезация, безопасность
- Создать панель управления для C-Level: видеть, как работает AI-ядро
Чек-лист:
- Есть единая схема архитектуры AI-решений в компании?
- Кто владеет оркестрацией и доступами?
- Есть метрики использования ИИ на уровне компании?
* * *
Спираль Агент-поток
Вторая спираль более заметная и “публичная”. Здесь ИИ взаимодействует с человеком: подсказывает, автоматизирует, принимает решения. Эта линия развивается быстрее, но часто упирается в предел, когда за внешним интерфейсом нет инфраструктурной опоры.
* * *
Этап 1: Consumer AI Adoption
Что происходит:
Сотрудники начинают использовать ChatGPT, Copilot, DeepSeek, Notion AI и другие сервисы. Неофициально или даже вопреки политике компании.
Ключевые задачи:
- Разрешить или ограничить использование: где можно, где нет
- Начать отслеживать сценарии: где AI действительно помогает
- Встроить “AI-гигиену” в культуру: как использовать с умом
Чек-лист:
- У вас есть политика использования публичных ИИ-сервисов?
- Кто отвечает за обучение сотрудников “разумному AI”?
- Какие сценарии уже работают (например: анализ презентаций, помощь в email, резюме задач)?
* * *
Этап 2: AI-Agents / RAG
Что происходит:
Появляются внутренние агенты, специализированные ИИ-интерфейсы для задач: от HR до аналитики. Часто работают на RAG (retrieval-augmented generation).
Ключевые задачи:
- Сформировать пул задач, где агент решает лучше человека
- Построить UX: как с ним работают, как он обучается
- Внедрить метрики: точность, скорость, принятие пользователями
Чек-лист:
- Вы знаете, в каких процессах ИИ уже может заменить 30-50 % труда?
- У вас есть RAG-архитектура хотя бы для одного сценария?
- Как измеряете пользу агента: скорость, качество, снижение нагрузки?
* * *
Этап 3: Multi-Agent Systems
Что происходит:
Агенты становятся командой. Они умеют делегировать друг другу, собирать цепочки решений, выполнять сложные инструкции. Это не один бот — это сеть.
Ключевые задачи:
- Сформировать ролевую модель агентов: кто за что отвечает
- Обеспечить взаимодействие: память, диалог, логика задач
- Защитить от ошибок: проверка результатов, ограничения
Чек-лист:
- У вас есть сценарии, где агенты работают в связке?
- Кто отвечает за координацию действий агентов?
- Есть система логирования и проверки решений агентов?
* * *
Этап 4: Orchestrated Intelligence
Что происходит:
ИИ переходит от роли “помощника” к роли управляемой системы ролей. У каждой своя логика, данные, метрики. Оркестрация становится частью бизнес-архитектуры.
Ключевые задачи:
- Построить “AI-карту ролей” внутри компании
- Управлять взаимодействием агентов с пользователями, системами, друг с другом
- Встроить агента в оргструктуру: у него есть задачи, график, результат
Чек-лист:
- У вас есть архитектура цифровых ролей ИИ в компании?
- Кто координирует работу агентов между собой и с людьми?
- Как вы измеряете эффективность агентной системы как целого?
* * *
Важно:
Многие компании пытаются скакнуть сразу к многоагентности, не пройдя путь от ChatGPT к агенту → от агента к роли → от роли к взаимодействию. В итоге шоу-кейсы без пользы.
Как переплетаются потоки и где застревают компании
Почему нельзя строить агентов без данных, а пайплайны без интерфейсов это пустая архитектура.
В предыдущих двух разделах мы разложили две спирали AI-зрелости:
- Data-поток: отвечает за фундамент: данные, пайплайны, модели, инфраструктуру.
- Agent-поток: отвечает за интерфейс: взаимодействие, автоматизацию, агенты и их роли.
Теперь ключевой вопрос: как эти потоки взаимодействуют? И что происходит, если один из них "опережает" другой?
Двойная спираль: что видит бизнес
Представьте компанию, которая продвинута в Agent-потоке: у неё есть агенты, RAG-сценарии, даже UX красивый. Но внутри нет доступа к данным, модели нестабильны, пайплайны отсутствуют. Что произойдёт?
Агенты будут "болтать", но не решать.
Ответы неполные. Доверие падает. Эффект ноль.
Теперь другой кейс. Компания продвинута в Data-потоке: все пайплайны вылизаны, модели стабильны, всё логируется. Но нет взаимодействия, нет агентов, нет внедрения в процессы.
Модели есть, но никто не знает, как ими пользоваться.
Интеллект не активирован. Пользователи в стороне. Потенциал не реализован.
Модель взаимодействия: как согласовать развитие
Чтобы избежать дисбаланса, нужно смотреть на потоки как на взаимозависимые уровни зрелости. Один без другого бессмысленен. Вот как они сцепляются:
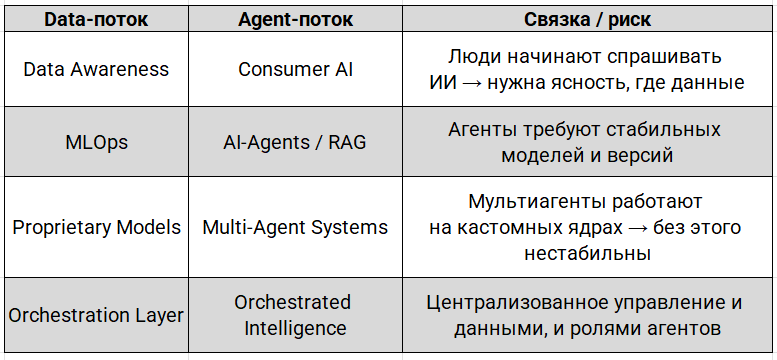
Узкие места: где компании теряют темп
1. “Сделали чат-бота, он тупой”
Причина: нет MLOps, нет данных, бот работает “в вакууме”.
Решение: параллельно развивать пайплайны и агентную архитектуру.
2. “У нас уже всё по данным, но никто не использует”
Причина: нет интерфейсов, нет агентов, AI не встроен в операционку.
Решение: запускать агенты даже на MVP-данных, как “дисплеи интеллекта”.
3. “Модель обучили, но боимся пускать в бизнес”
Причина: нет контроля, нет роли, нет оркестрации.
Решение: ввести уровень ответственности, ограничить зоны принятия решений, включить в ролевую архитектуру.
Как выровнять темпы двух потоков
- Еженедельные синки AI-архитектора и продакт-лидеров.
Один отвечает за модель, другой за то, как она применяется. - Двухосевая карта зрелости.
Вертикаль - Data-инфраструктура,
Горизонталь - Agent-внедрение.
Где перекос туда и внимание. - Параллельные MVP.
Например: один агент → на одних данных → по одному пайплайну.
Быстро. Проверено. Управляемо.
Идея, которую надо усвоить:
ИИ это не функция. Это двуединство: “что он знает” + “как он действует”.
Без архитектуры — хаос. Без интерфейса — тишина.
Как управлять AI-эволюцией в компании
Что должен знать и делать менеджмент на каждом уровне зрелости
ИИ в бизнесе это не “поставить нейросеть”. Это стратегия роста.
А стратегия требует архитектуры, синхронизации и фокуса.
Я показал: внедрение ИИ не линейно. Это двойная спираль, и вы не можете позволить себе роскошь развивать только одну из них.
Основные выводы:
- ИИ развивается по двум путям: инфраструктура и взаимодействие.
Один без другого, либо “слепая мощность”, либо “болтливый бот”. - На каждом этапе должен быть свой чек-лист зрелости.
Уровень “сделали бота” и уровень “ввели orchestration layer” требуют разных решений и команд. - Зрелость нельзя сымитировать.
Нельзя “перепрыгнуть” с Copilot сразу в многоагентную архитектуру, если нет MLOps. - Сильные команды развивают оба потока параллельно — через синхронизированные MVP.
Что делать управленцу уже сейчас:
1. Провести экспресс-аудит по двум спиралям.
Где мы находимся по Data? Где по Agent? Где дисбаланс?
2. Сформировать роли и команды.
- AI-архитектор отвечает за системную зрелость.
- AI-продукт - за интерфейс и внедрение.
- AI-губернатор - за governance и безопасность.
3. Запустить параллельные пилоты.
Например:
- Один агент → на одном пайплайне → по одной роли
- Метрики: точность, принятие, устойчивость
4. Построить дорожную карту развития.
Не “внедрим AI до Q4”, а:
- Q1: DataOps + RAG-агент
- Q2: MLOps + 2‑агентная связка
- Q3: Orchestration layer
- Q4: Мультиагент с управлением
ИИ - не инструмент, а новая операционная система бизнеса.
И управлять ею нужно как архитектор, а не как интегратор.