В 2025 году новейшие модели искусственного интеллекта начали проходить новый тест, который призван показать, насколько широки возможности ИИ во всех областях человеческой экспертизы. В настоящее время с тестом не смогла справиться на 100% ни одна модель. «РБК Тренды» рассказывают, кто придумал этот тест, как он устроен и из каких вопросов состоит.
Содержание:
- Что такое «Последний экзамен человечества»
- Как создавали тест
- Какие результаты в тесте показали модели ИИ
- Перспективы тестирования ИИ
Что такое «Последний экзамен человечества»
«Последний экзамен человечества» (Humanity’s Last Exam) — это тест для больших языковых моделей, разработанный в 2025 году компанией Scale AI и Центром безопасности ИИ (CAIS). Он включает 2500 вопросов по более чем 100 дисциплинам, в том числе по математике, физике, биологии, социальным наукам и другим, а также более сложные задания на интерпретацию графиков и изображений. 24% вопросов предполагают множественный выбор, а остальные — однозначный ответ.
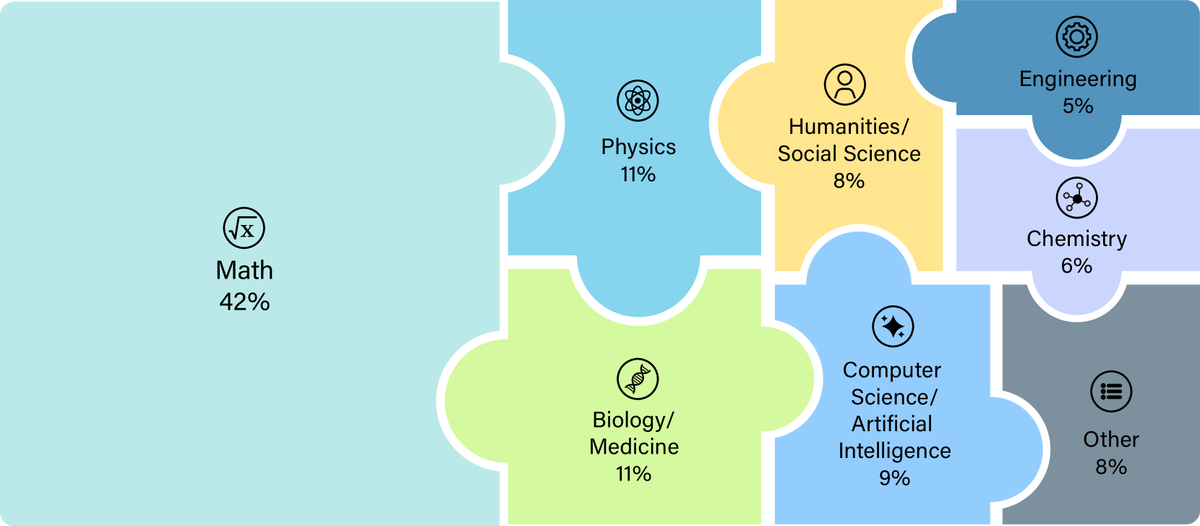
Отличительной чертой HLE является его ориентация на вопросы, находящиеся на периферии человеческих знаний. Они намеренно выходят за рамки стандартных академических тестов, попадая в область, где даже узкоспециализированные специалисты могут столкнуться с трудностями. Один из вопросов теста звучит так:
«Колибри, относящиеся к отряду Apodiformes, отличаются наличием парной овальной кости, расположенной с обеих сторон, — или сесамовидной кости, расположенной в каудолатеральной части расширенного крестообразного апоневроза места прикрепления m. depressor caudae. Сколько парных сухожилий поддерживает эта сесамовидная кость? Укажите число».
Этот вопрос требует глубоких знаний анатомии, что делает его непростым даже для специалистов.
Идея создания Humanity’s Last Exam принадлежит исследователю в области машинного обучения и директору Центра безопасности ИИ Дэну Хендриксу. Ранее эксперт уже выступил соавтором двух тестов систем ИИ, одна из которых проверяет их знания на уровне бакалавриата по таким темам, как история США, а другая — способность моделей рассуждать на уровне участника олимпиады по математике.
Хендрикс отметил, что задумался о тесте после разговора с Илоном Маском, который называл существующие системы, включая математический тест MMLU, слишком простыми. После этого он начал сотрудничать со Scale AI для поиска и составления вопросов. В итоге их готовили более тысячи экспертов из 50 стран, включая профессоров, исследователей и обладателей ученых степеней.
Идею Хендрикса поддержали и другие разработчики. По их словам, когда модель GPT-4 набрала более 90% в математическом тесте MMLU (Massive Multitask Language Understanding), бенчмарк фактически утратил способность выявлять значимые улучшения в новых моделях и критические различия между наиболее эффективными из них. В итоге ИИ-разработчики столкнулись с фундаментальными проблемами:
- ограниченность измерений — когда модели достигают максимальных показателей, точно измерить их улучшение становится невозможно;
- нереалистичные ожидания относительно возможностей ИИ;
- скрытые недостатки ИИ, когда критические пробелы в знаниях остаются незамеченными, несмотря на высокие показатели в тестах.
В ежегодном отчете Стэнфордского университета «Индекс ИИ за 2025 год» «Последний экзамен человечества» назван одним из «самых сложных тестов», разработанных в ответ на «насыщение» рынка популярными системами тестирования. Изначально тест хотели назвать «Последний рубеж человечества», но позднее разработчики отклонили эту идею из-за чрезмерного драматизма названия.
Как создавали тест
Для отбора вопросов разработчики использовали многоэтапный процесс проверки. Сначала вопросы были отфильтрованы ведущими моделями ИИ; если те не смогли ответить или показали результаты хуже случайного угадывания, то задачи отбирались для теста. В общей сложности на первом этапе отобрали более 70 тыс. вопросов, из которых около 13 тыс. поставили модели ИИ в тупик. Затем отобранные вопросы проходили двухэтапную процедуру проверки: раунд обратной связи с несколькими рецензентами уровня выпускников и ревизию организатора и эксперта-рецензента.
Авторы самых удачных вопросов получили по $5 тыс. за каждый из 50 лучших вопросов и по $500 за следующие 500 вопросов. После релиза разработчики запустили программу вознаграждения за обнаружение багов с целью «выявить и устранить серьезные ошибки в наборе данных». К марту 2025 года список вопросов теста утвердили окончательно.
Какие результаты в тесте показали модели ИИ
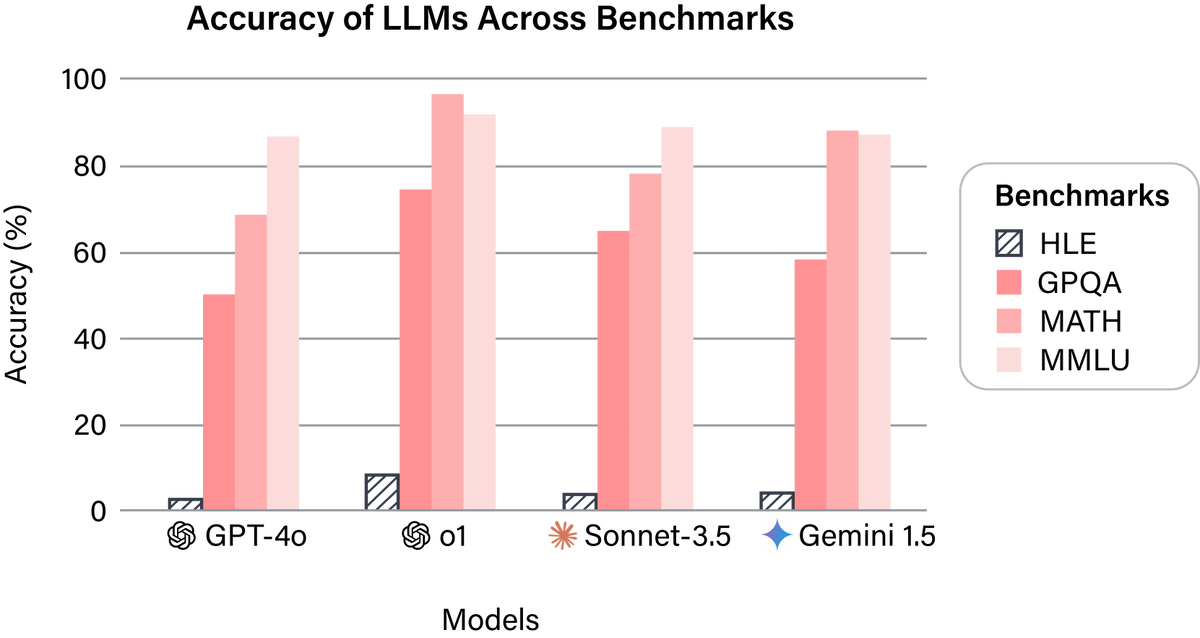
После того как тест представили в начале 2025 года, исследователи устроили «Последний экзамен человечества» шести ведущим моделям ИИ, включая Gemini 1.5 Pro от Google и Claude 3.5 Sonnet от Anthropic. Результаты оказались скромными: модель GPT-4o набрала 3,3%, Grok-2 — 3,8%, а наивысший результат оказался у DeepSeek-R1 — 9,4%.
Однако со временем результаты моделей улучшаются. В рейтинге Scale AI за июнь 2025 года первое место занимала Gemini 2.5 Pro Preview от Google, набравшая 21,64%, а далее следуют o3 (high) от OpenAI (20,32%) и Claude Opus 4 (Thinking) от Anthropic (10,72%).
Компания xAI Илона Маска, которая в начале июля представила свою новую модель Grok 4, заявила, что ее результат в Humanity’s Last Exam достиг рекордных 25,4%.
Этот показатель увеличился до 44,4% с версией Grok 4 Heavy, которая использует несколько ИИ-агентов для решения задач. Следующими по эффективности моделями ИИ в Humanity’s Last Exam стали Gemini-Pro от Google (26,9% с использованием дополнительных инструментов или системных подсказок) и o3 от OpenAI (24,9%, также с инструментами).
Перспективы тестирования ИИ
Хендрикс ожидает быстрого роста показателей ИИ-моделей в «Последнем экзамене человечества» уже в 2025 году. По его словам, к концу года они могут превысить 50%. К этому моменту, говорит Хендрикс, системы ИИ можно будет считать «оракулами мирового класса», способными отвечать на вопросы по любой теме точнее, чем эксперты-люди. Исследователь допускает, что после этого ИИ-сообществу придется искать другие способы тестирования ИИ.
«Можно представить себе улучшенную версию теста, где мы можем задавать вопросы, на которые пока не знаем ответов, и проверять, способна ли модель помочь нам решить эти задачи», — отметила соавтор теста, директор по исследованиям Scale AI Саммер Юэ.
Автор некоторых вопросов «Последнего экзамена человечества», исследователь в области теоретической физики элементарных частиц Кевин Чжоу, не считает, что способность моделей ИИ правильно отвечать на сложные вопросы свидетельствует об «умном» ИИ. «Существует огромная пропасть между тем, что значит сдать экзамен, и тем, что значит быть практикующим физиком и исследователем. Даже ИИ, способный ответить на эти вопросы, может быть не готов помочь в исследовании, которое по своей сути менее структурировано», — пояснил он.
Таким образом, Humanity’s Last Exam может быть последним академическим экзаменом, который нужно сдавать моделям, но это далеко не последний тест для проверки способностей ИИ, заключили авторы разработки.
➤ Подписывайтесь на телеграм-канал «РБК Трендов» — будьте в курсе последних тенденций в науке, бизнесе, обществе и технологиях.