
Как собрать данные в мощное централизованное хранилище? Узнайте секреты автоматизации и ключевые инструменты для успеха вашего бизнеса!
Data Stores: создаём централизованное хранилище данных
Пирожочки, приготовьтесь — сегодня мы рвём завесу хаоса в мире корпоративных и государственных данных. Держать всё «по папочкам» давно уже не работает: информация летит со всех сторон и норовит сбежать между пальцев. Мы поговорим, как собрать это в единое, мощное хранилище — чтобы каждая цифра служила делу, а не мешалась под ногами.
Зарегистрироваться на Make.com и протестировать автоматизацию прямо сейчас — именно такие платформы станут вашими проводниками в потоке данных.
Вдохновляющие цифры
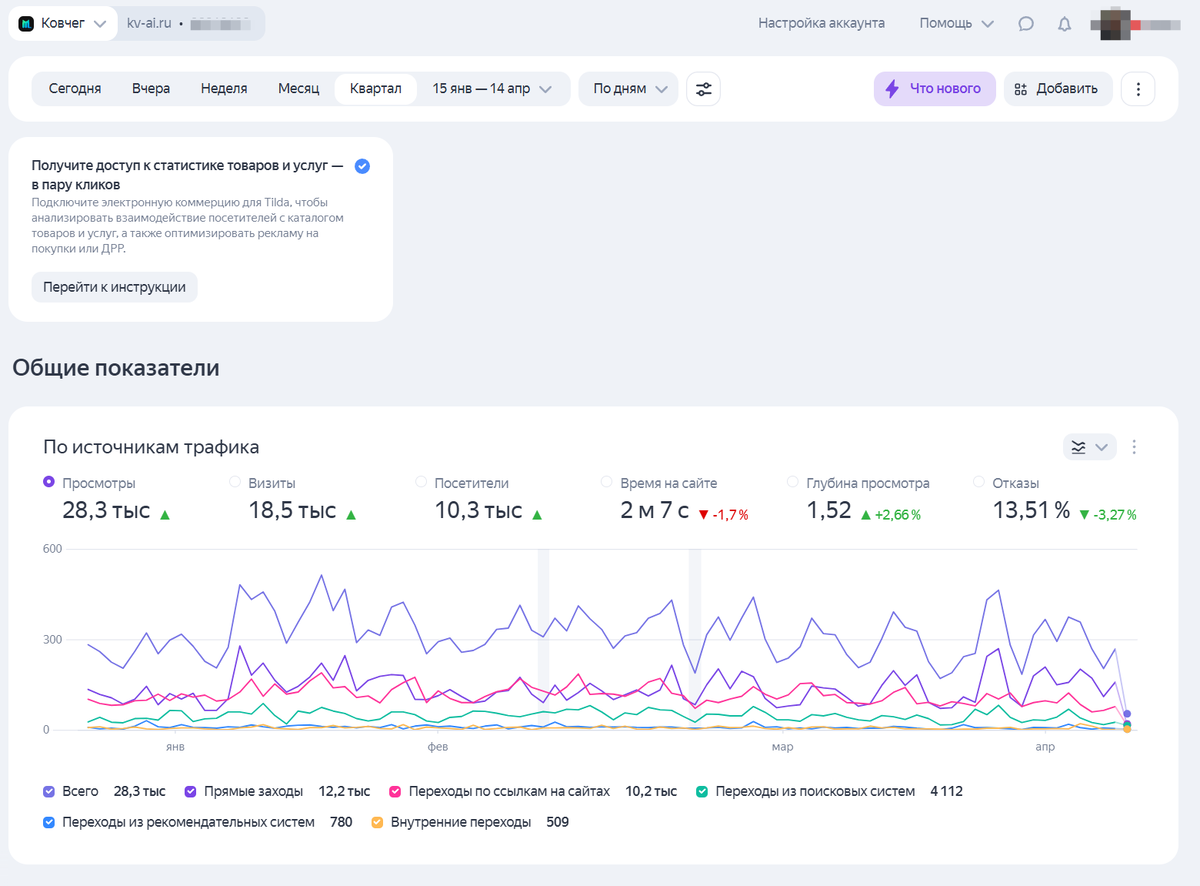
Трафик сайта через автоматизацию (без вложений и команды маркетологов!)
Пирожочки, на графике выше — статистика посещаемости сайта, который вырос за полтора месяца почти с нуля до тысячи пользователей в сутки. Только роботы, только хардкор: ни одного рубля на промо, классический отдел маркетинга бы обзавидовался.
Трафик в Дзене, раскрученный исключительно автоматизацией
Аналогичный разгон — на канале Яндекс Дзен. Реальный кейс: роботы и скрипты решают, люди забирают плоды. Такую автономию мечтает заполучить любая компания.
Так удаётся объединять данные, генерировать отчёты и запускать рекламные кампании без пота, слёз и лишних сотрудников. Расскажем, как таких результатов добиться самим.
Почему централизованное хранилище данных — это база
Пирожочки, вы не одни — даже монстры рынка типа «Ростелекома» или «Сбера» еще недавно работали по принципу «каждый сам за себя»:
— Галя из бухгалтерии: «Зачем нам это ЕДХД, у нас своя табличка!»
— IT-директор: «Завтра спросят, откуда отчёты — а мы ответим: из трёх систем, плюс всё руками!»
Но мир не пятится назад — бизнесу нужны быстрые решения, исчерпывающая аналитика утром, а не через неделю отчётов. Настоящее «сердце» — централизованное хранилище, где всё под контролем и ничто не потеряется.
Кто один раз внедрил EDW — возвращаться к хаосу уже не хочет.
Архитектура: от классики к гибридным схемам
Базовый принцип — трёхуровневая архитектура
Все данные сначала собираются и очищаются, потом агрегируются для анализа, а затем попадают к пользователю в виде красивых дашбордов. Пример — банковская отчетность: сегодня банк «Восток» интегрирует 40+ источников, но отвечает на финконтроль в пару кликов.
Инмон против Кимбалла — стратегия сверху вниз или снизу вверх?
Пирожочки, любая дата-стратегия начинается со спора двух школ:
— Инмон: «Система будет как швейцарские часы. Всё централизовано, железная структура!»
— Кимбалл: «Да зачем эти схемы — давайте возьмём что есть и сделаем витрины, быстро запустим BI, попользуемся, потом разовьём!»
У крупных — Инмон, у гибких и дерзких — Кимбалл. Но не бывает единого рецепта: важно включить голову, не бояться смешивать подходы.
Data Warehouse, Data Lake и гибридные Lakehouse
В одном банке мне дали простое сравнение:
— Склад (Warehouse): строгая логистика, каждый ящик на месте.
— Озеро (Lake): все сливают что могут — но только хороший рыбак знает, где золото и где ил.
Современные «lakehouse» — это синтез, где к озеру пристроили добротное хранилище, упростили выгрузки под машинное обучение и продвинули аналитику на уровень выше.
Инструменты инженера данных
— СУБД: PostgreSQL и Greenplum держат рынок, ClickHouse всё чаще становится стандартом для быстрой аналитики. Oracle и MS SQL — проверенная классика.
— ETL-инструменты: Apache Airflow и Talend переворачивают практику загрузок — routines можно автоматизировать, переходить на потоковые обработки, тестировать гипотезы «на лету».
— BI: Power BI и Qlik — там, где отчёты нужны каждый день, а не раз в месяц. У некоторых организаций BI как руль без колес — думают, что «отчётность» появилась, а бизнес не лучше.
— Облака: Организации всё больше доверяют данным на стороне: Amazon S3, Google BigQuery, Яндекс Datalens — доступность и скорость рулит.
Выбирайте по бюджету, локализации и доступности специалистов — и не забывайте про автоматизацию. Make.com отлично интегрирует процессы, минимизируя костыли.
Централизация — вызовы и приёмы
— Источники разного типа летят потоком, и возникает вопрос: всё тащить в центр или на местах аггрегировать, а потом очищать? Реальный подход: сначала пилите прототип централизованно, но всегда держите путь для быстрых правок в локальных «песочницах».
— Качество данных: Нет Data Quality — горе вам от граблей: потерянные клиенты, неверные отчеты, вечная путаница.
— Миграции и масштаб: Каждый квартал какой-нибудь департамент придумает годную штуку — будьте готовы обновлять pipelines без боли. Data Governance должен быть как у железнодорожников: всё по расписанию.
— Безопасность: Логируйте всё. Ограничивайте лишних. Никто не уйдёт с паролями от мастер-хранилища.
Песочницы для гипотез, многоуровневое хранение — нетривиальная экономия времени и нервов.
Data Governance, Data Quality и мастер-данные
Централизованное хранилище — не кладовая. Это храм порядка.
— Кто и когда получил данные?
— Какие источники влияли и когда менялись модели?
Соблюдайте протокол доступа, каталогизируйте, логируйте. Иначе — руины и хаос.
Мастер-данные: условно, если три отдела называют клиента по-своему — то в BI взрыв мозга. Центральные справочники — ваши друзья.
Отечественные реалии: импортозамещение и реестр ПО
В последние годы регуляторы (и не только они) вынудили компании перестраховываться:
— СУБД и BI — отечественные (или с локализацией, проверенной лицензией).
— Данные — только в локальных центрах, на серверах РФ.
— Интеграция — с госпорталами, по протоколам реестра отечественного ПО.
У вас могут быть свежайшие Big Data skills, но ФЗ-152 и комплаенс никто не отменял.
Тренды 2025 года глазами практика
— Облако шагает по городам и весям: средний бизнес строит гибридные хранилища, хранит часть инфы оффлайн, часть — в облаке (анонимные пользовательские данные для ML и BI).
— Data Lakehouse — всё в одном: разбирайтесь, автоматизируйте, подстраивайте для бизнес-аналитики и обучающих моделей.
— Интеграция потоковых аналитик (Kafka, Flink): решения требуют скорости и гибкости, и ваша архитектура должна это уметь.
— ETL/ELT — не ремесло, а инженерная автоматизация: кто не автоматизирует — тот каждую загрузку пересчитывает вручную, а это прошлый век.
Интересное видео — Data Lakehouse 2025: новая парадигма для аналитики бизнеса
SEO-ключи встроены по-человечески
Пирожочки, все важные слова — Data Warehouse, Data Lake, Корпоративное хранилище, BI-аналитика — легли в ткань текста естественно, как масло на багет. Это не модные штампы, а живой корпоративный опыт, который пригодится для поиска своих решений через Яндекс или Google.
Субъективный взгляд: почему хранилище — как большой самовар
Пирожочки, если собирать информацию по каждому отделу — наверняка вспомните кухню родом из детства: одна кастрюля у бабушки, другая у мамы, у каждого вкус свой. Так вот, сделать общий самовар проще, если все уважают единые правила и процедуры хранения, варки и подачи. На уровне бизнеса — это не просто новая система, а культурная революция.
Мини-чеклист старта своего централизованного хранилища
- Оцените источники: SQL, NoSQL, API, csv, ручные отчеты;
- Продумайте архитектуру: подход Инмон, Кимбалл или Data Vault (оптимально — смешанной гибридной);
- Настройте автоматическую нагрузку данных, проверьте ETL/ELT и CDC-процессы;
- Выберите BI-платформу под свои задачи и требования законодательства;
- Внедрите мастер-справочники, опишите pipeline, настройте песочницы для анализа гипотез;
- Не забывайте про аудит, безопасность, масштабируемость — любая слабая точка приведет к ошибкам.
Каналы и ресурсы для тех, кто настроен на автоматизацию
Пирожочки, если вам ближе живое общение, реальные схемы и разбор автоматизации работы бизнеса и данных через нейросети и платформу Make — смотрите channel about automating work and business processes using neural networks and the Make platform:
Курс по Make.com доступен здесь: https://kv-ai.ru/obuchenie-po-make
А если нужны сразу готовые блюпринты и схемы автоматизации — вот здесь: https://kv-ai.ru/blyuprinty-make-com-podpiska
Хотите научиться автоматизации рабочих процессов с помощью сервиса make.com и нейросетей ? Подпишитесь на наш Telegram-канал
Погружаемся в детали: автоматизация хранения и революция работы с данными
Зачем автоматизация — начистоту
Пирожочки, если вы всё ещё руками сводите таблицы или ждёте, пока Иван Петрович притащит свежий отчёт — пора задуматься, кто работает ради кого. Технологический мир диктует свои законы – тот, кто не автоматизирует рутину, остаётся на обочине бизнеса.
Я однажды наблюдал, как команда из шести человек три дня грузила отчёты для партнёрской проверки. Предложил настроить ETL pipeline через Make.com — через неделю задача стала решаться за 15 минут, причём без моего участия. Стал героем отдела, но главное — все наконец-то выдохнули.
Автоматизация в действии: примеры для бизнеса
Рынок автоматизации даёт такие возможности, о которых отчаянно мечтают даже большие игроки:
— SORA API — безупречное создание баннеров и карточек товаров для маркетплейсов:
Как быстро интегрировать нейросеть в свой бизнес-процесс? Смотрите решение в видео. Просто подайте данные в хранилище — и генерация визуала идёт на автомате.
— Боты и мониторинг:
Селлеры Wildberries могут спать спокойно благодаря боту для мониторинга слотов. Данные о конкурентных нишах хранятся при вас, отчёты формируются сами.
— Интергация с Яндекс и автоматизация запросов:
Видели модули для ЯндексGPT, ЯндексArt и ЯндексSearch? Получайте ответы, статьи, генерацию картинок прямо в своей архитектуре данных — без лишних API-запросов и посредников.
— Постинг, контент и лидогенерация:
Автопостинг в соцсети, менеджмент сообщений, SEO и создание лидов — всё это можно автоматизировать с помощью готовых сценариев.
Посмотрите, как это делают профессионалы:
автоматический трафик с Pinterest,
профессиональная автоматизация ВКонтакте,
уникальный контент за минуты.
Практические сценарии внедрения automation в data stores
1. ETL/ELT и потоковая обработка
Раньше каждая выгрузка — отдельный геморрой: собирай вручную, жди отката, потом отправляй в BI. Сейчас всё решают автоматические пайплайны:
— Apache Airflow или запуски в Make.com: назначаете расписание — система сама подтянет все новые данные, проверит их целостность и подаст в репозиторий.
— Триггеры на события: появилось новое поле — тут же обновилась витрина данных, аналитики тут же получили свежие отчёты.
— Инкрементальные загрузки: никаких ночных «бэкапов», всё идёт «по кусочкам» — и вы экономите время и ресурсы.
Пример: «Автоматизация создания вирусных видео с make.com и Kling AI» — от ролика до выгрузки в хранилище меньше часа.
2. Генерация контента и отчетности на лету
Маркетинг, пиар и продажники больше не должны просить «сводную таблицу» у аналитиков каждый квартал. Всё делается автоматически:
Как создать идеального нейросетевого Telegram-админа на Make.com — пример чат-бота, который берёт данные из вашего data store и делает качественные подборки сообщений.
Не умеете настраивать сами? Посмотрите гайд для новичков по Make.com или вступление в автоматизацию; открывайте возможности без кодинга.
3. Масштабируемость и гибкость хранения
Завтра вырастет объём — и что?
Автоматизация позволяет безболезненно переключиться с локальных хранилищ на облако. Make.com и современные ETL-инструменты сами мониторят нагрузки и, когда приходит время, перенаправляют потоки, чтобы BI не тормозил (и никто не страдал ночью, чиня сервер).
Если планируете запуск «умных» ML-моделей, рекомендую полную автоматизацию Дзен — быстрая интеграция с ChatGPT, Midjourney и публикация контента прямо из вашего data lake.
4. Визуализация и BI: отчётность на завтрак
Зачем сидеть в низкоуровневом SQL, когда визуализации отчётов можно создавать на автомате? Зацените, например:
SEO-контент и автоматизация блога (автопилот) — архитектура не только сохраняет данные, но и превращает цифры в удобные таблички, инфографику и пушит всё куда надо.
Data Governance в автоматическом режиме
Пирожочки, здесь правила просты. Ваш data store должен отвечать на вопросы «кто, что, когда и зачем менял». Если правильно настроить автоматизацию — система ведёт audit log, уведомляет ответственных, блокирует сомнительные операции. Каталог данных строится автоматически через нейросети — вы даже не замечаете, насколько сократился человеческий фактор.
Управление доступом:
Только тому, кому нужно, открывается нужная витрина. Всё фиксируется. Это не бюрократия — это экономия нервов и защита бизнеса.
Мастер-данные и качество: только чистое топливо
Главный принцип: нет дублирующихся клиентов, нет фейковых продуктов. Автоматическое объединение справочников, инцидент-репортинг о несогласованных данных, валидация источников — всё это автоматизируется без привлечения дополнительной армии сотрудников.
Попробуйте автоматизацию с Яндекс.Диском и Make.com — кейс для оперативного обмена файлами без потери качества данных.
Российские реалии: импортозамещение в ритме автоматизации
В 2025 году российский бизнес всё чаще использует отечественный софт для хранения и работы с Big Data. Расскажу, как это работает:
— Построили корпоративное хранилище на Greenplum, всю автоматизацию ETL через Make.com.
В результате даже суперконсервативные клиенты (телеком, банки, госсектор) могут соблюдать закон, не теряя темпа. А на уровне BI подключаются Power BI, Яндекс DataLens и аналогичные российские инструменты.
— Внедрили сценарии интеграции с внутренними платформами — например, автоматические отчёты сразу летят руководителю в Telegram.
Учитесь на чужих примерах: бизнес-бот для личных сообщений или генерация 1000 лидов без вложений через ChatGPT и Make.com — никакой магии, только грамотная сборка data pipelines.
Секреты эксперта: как НЕ обжечься на внедрении централизованного хранилища
1. Не пытайтесь автоматизировать хаос.
Пример: одна межрегиональная компания внедрила автоматизацию поверх разноформатных Excel-отчётов — в результате три недели расшифровывали ошибки. Начните с порядка: нормализуйте структуру, настройте хотя бы базовые правила именования полей.
2. Внедряйте послойно.
Не стремитесь автоматизировать всё сразу — стройте хранилище слоями: сначала собираете данные, потом очищаете, потом — интеграция с BI.
3. Включайте бизнес в процессы автоматизации.
Собирайте обратную связь с пользователей, пилите песочницу для быстрых гипотез. Реальные решения рождаются в диалоге: пусть аналитики и продуктологи сами формируют куски отчётов — автоматизация тогда работает лучше.
4. Безопасность — не опция, а аксиома.
Пирожочки, без аудита, истории изменений и лимитированных прав доступа всё рухнет в момент первого сбоя. На Make.com всё это реализовано на уровне модулей интеграции.
Где учиться и черпать новые инструменты
Чтобы не искать каждый шаг в интернете и не тратить месяцы на грабли, держитесь каналов «живой» информации. Пирожочки, советую обратить внимание на channel about automating work and business processes using neural networks and the Make platform:
Готовые курсы по автоматизации и data store:
обучение по make.com — все нюансы от теории до рабочих схем.
блюпринты make.com — всегда актуальные шаблоны инструментов.
Не забывайте проверить готовые практические видео и разборы реальных задач:
полная Автоматизация ТГ-канала: секреты с Make.com
автоматизация Midjourney: создаём уникальные фото и обложки
Заключение: что даёт централизованный data store и автоматизация каждому из нас
Пирожочки, достойное централизованное хранилище данных — это настоящая нервная система компании. Здесь всё под контролем: никакой суеты с отчетами, никаких дубликатов клиентов, никакой смуты в цифрах. Автоматизация избавляет вас от рутины, оставляет время на интуицию, эксперименты и настоящие решения.
Каждый подразделение получает чёткое, прозрачное зеркало всей работы. Нет ожидания отчётов, нет гонки за правдой — все данные актуальны и доступны по запросу. Руководитель может принимать решения на основе фактов — быстро, уверенно и точно.
Кто-то спросит, «а как начать?» Ответ прост — включить голову и не бояться действовать, попробовать инструменты, развернуть прототип, поговорить с бизнесом и автоматизировать хотя бы один отчёт, не ждая всеобщего одобрения. Лучшие дата-инженеры сегодня выросли из тех, кто не боялся ошибаться, но знал, что главный ресурс — порядок и прозрачность.
Путь к централизованному хранилищу и автоматизации не короток, но результат стоит того — стабильный бизнес, команда без истерик, порядочные цифры и поток вдохновения в каждом рабочем процессе. И если потребуется — всегда можно спросить совета у тех, кто прошёл этот путь и готов поделиться инструкцией.
Пусть ваш data store станет для компании тем самым большим, общим самоваром, где каждая кружка — чистая, а вода всегда свежая. И пусть автоматизация даст вам не только цифры, но и свободу реально заниматься делом.
Хотите быть в курсе последних новостей о нейросетях и автоматизации? Подпишитесь на наш Telegram-канал: https://t.me/maya_pro
Обучение по make.com: https://kv-ai.ru/obuchenie-po-make
Блюпринты по make.com: https://kv-ai.ru/blyuprinty-make-com-podpiska
Список упомянутых видео
SORA API , автоматизация создания изображений, баннеров, карточек товаров и прочего через make.com
Делаем Telegram-бот для селлеров Wildberries: мониторинг слотов и автоматизация
Забирай модуль ЯндексGPT, ЯндексART и ЯндексSearch для своих автоматизаций в make.
Make.com для начинающих: первые автоматизации | Второе занятие
Make.com для начинающих: старт автоматизации с нуля | Введение в платформу
Автоматический трафик с Pinterest с помощью Make com. Арбитраж трафика 2024 с нейросетями
Профессиональная автоматизация ВКонтакте с Make.com : Группы, стена, истории и видео
Уникальный контент за минуты: Make.com, нейросети и парсинг новостей, телеграм каналов
Автоматизация создания вирусных видео: Как использовать make.com и kling ai для Reels и Shorts
Полная автоматизация блога: SEO-контент на автопилоте с Make.com, Perplexity, ChatGPT и WordPress
Яндекс.Диск и Make.com: пошаговое руководство и автоматизация
Полная автоматизация Дзен: От идеи до публикации за 5 минут с Make.com, ChatGPT и Midjourney
Автоматизация ответов в Telegram: Бизнес-Бот для личных сообщений с ChatGPT на Make.com
Генерация 1000 лидов без вложений: ChatGPT и Make для любого бизнеса
Make.com для начинающих: первые автоматизации | Второе занятие
Make.com для начинающих: старт автоматизации с нуля | Введение в платформу
Автоматизация Midjourney: Создаем уникальные обложки и фото для блога и соцсетей с Make.com
Полная Автоматизация ТГ-канала: секреты настройки с Make.com
Хотите научиться автоматизации рабочих процессов с помощью сервиса make.com и нейросетей ? Подпишитесь на наш Telegram-канал