📑 Chunkr — это открытое решение для обработки сложных документов.
Предназначено для извлечения структурированных данных из PDF, PowerPoint, Word-документов и изображений, подготавливая их для использования в системах Retrieval-Augmented Generation (RAG) и больших языковых моделях (LLM).
Основные возможности:
🔵Анализ структуры документа: Выделение заголовков, таблиц, формул, подписей и других элементов с помощью анализа макета и OCR.
🔵Гибкая настройка обработки: Возможность выбора стратегии обработки для разных сегментов документа, включая использование Vision Language Models (VLM) для сложных элементов.
🔵Поддержка различных форматов: Обработка PDF, PPT, Word и изображений.
🔵Генерация структурированных данных: Вывод в форматах HTML, Markdown и JSON, готовых для интеграции с LLM.
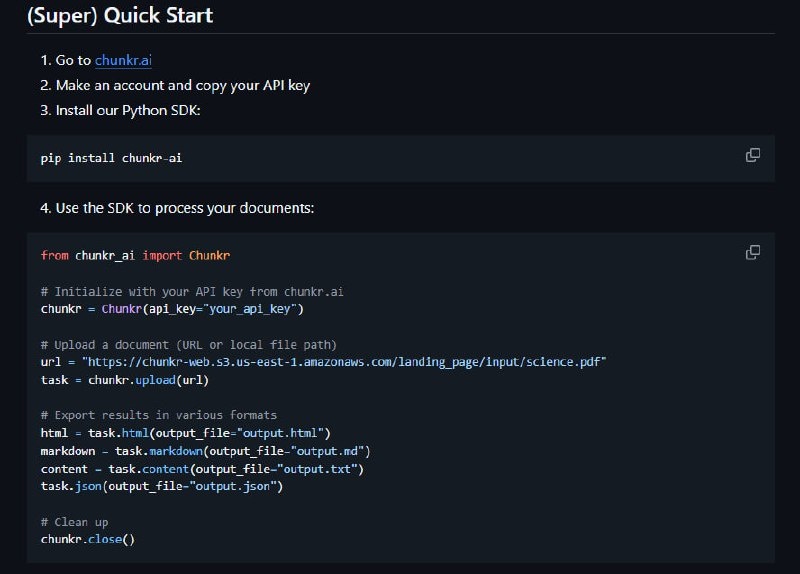
🔵API и SDK: Предоставление Python SDK для удобного взаимодействия с сервисом.
🔵Самостоятельный хостинг: Возможность развертывания на собственных серверах с использованием Docker Compose или Kubernetes
➡️Установка: pip install chunkr-ai
⚙️ Документация
➡️Справочник Программиста. Подписаться