Большинство программистов пишут парсеры — часто они оказываются слишком медленными, особенно когда речь идёт о больших данных. Но что, если применить к коду низкоуровневые оптимизации, многопоточность и даже SIMD-инструкции, чтобы добиться выдающихся результатов? В новой статье от Ricardo Pallas демонстрируется именно это: обычный парсер математических выражений, написанный на Rust, ускорили с 43 секунд до менее чем 1 секунды на файле размером 1.5 ГБ! 🔥
📌 С чего всё началось?
Обычный парсер работал медленно и неэффективно. Исходная реализация была стандартной: считывание строки, её разбиение на токены, создание вектора и рекурсивный разбор выражений:
fn tokenize(input: &str) -> Vec<Token> {
input
.split_whitespace()
.map(|s| match s {
"+" => Token::Plus,
"-" => Token::Minus,
"(" => Token::OpeningParenthesis,
")" => Token::ClosingParenthesis,
n => Token::Operand(n.parse().unwrap()),
})
.collect()
}
🕐 Результат: 43 секунды обработки на 1.5 ГБ файле.
🎯 Пять шагов к невероятной оптимизации
Разработчик последовательно внедрил пять мощных оптимизаций:
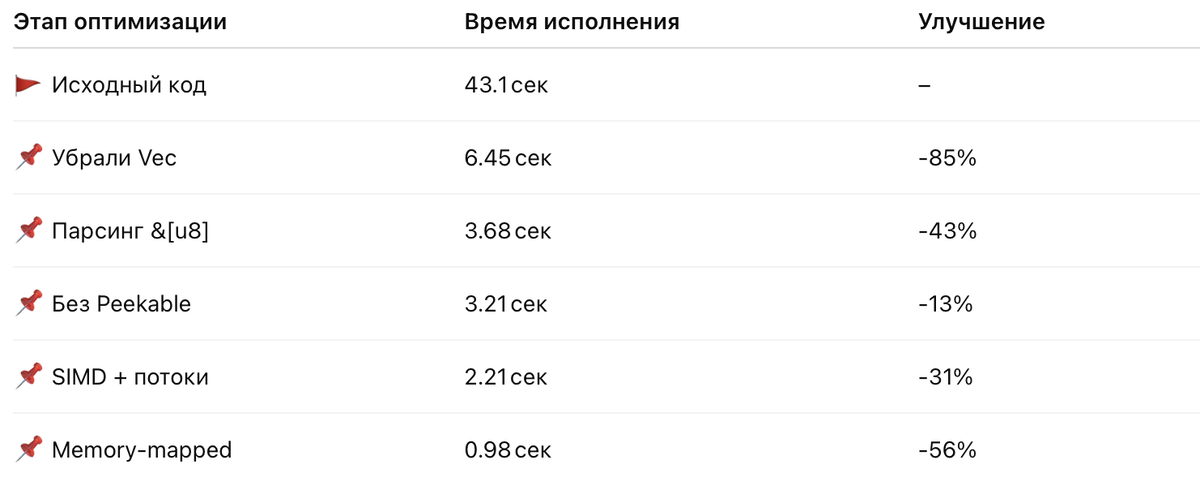
1️⃣ Убрали лишние аллокации (43.1 с → 6.45 с, –85%)
Изначально токены собирались в вектор, что было крайне неэффективно. Перейдя на ленивый итератор, избавились от лишних выделений памяти.
2️⃣ Парсинг напрямую из байтов (6.45 с → 3.68 с, –43%)
Перешли с обработки строк (&str) на обработку сырых байтов (&[u8]). Это избавило от накладных расходов при работе со строками в Rust.
3️⃣ Упростили парсер, убрав Peekable (3.68 с → 3.21 с, –13%)
Отказались от предварительного просмотра токенов через адаптер Peekable, вместо этого сразу обрабатывали токены при поступлении.
4️⃣ Многопоточность и SIMD-инструкции (3.21 с → 2.21 с, –31%)
Использовали библиотеку Rayon для параллельного выполнения и SIMD-инструкции (AVX-512) для поиска оптимальных точек разделения данных. В чём именно суть?
- SIMD-инструкции за одну команду проверяют 64 байта входных данных, обнаруживая позиции символов «+», «(» и «)».
- Это позволило максимально эффективно найти подходящие места разбиения для обработки данных разными потоками.
- В результате парсер разделяет данные безопасно (с учётом скобок и ассоциативности операций) и параллельно обрабатывает чанки.
5️⃣ Использовали memory-mapped файлы (2.21 с → 0.98 с, –56%)
Вместо чтения файла в оперативную память через fs::read применили технику memory mapping (mmap). Это позволяет:
- 📥 Избежать копирования данных из пространства ядра в пользовательское пространство.
- 🧵 Минимизировать негативный эффект false sharing (ложного разделения кэша между потоками).
Теперь ОС сама загружает и эффективно распределяет данные между потоками напрямую из диска.
🧠 Особые технические приёмы:
Помимо общих подходов, важную роль сыграли специальные низкоуровневые техники:
- 🎛️ SIMD (Single Instruction, Multiple Data): одна инструкция процессора работает с большим объёмом данных одновременно. Так вместо последовательного просмотра каждого символа по отдельности можно проверить сразу 64 символа.
- ⚙️ Эффективное разделение: алгоритм не просто дробит входные данные на равные части, а учитывает синтаксические и математические ограничения:
❌ Нельзя разбивать выражения внутри скобок.
❌ Нельзя разбивать выражения на операциях вычитания, т.к. это нарушает ассоциативность.
✅ Разбивать можно только на верхнем уровне, используя операции сложения. - 📁 mmap для I/O: memory-mapped файлы позволяют избегать лишних копий данных и дают значительный прирост производительности, особенно в многопоточных сценариях.
🔥 Итог: от 43 секунд к 0.98 секунды (ускорение в 44 раза!)
После всех оптимизаций парсер буквально преобразился:
В итоге мы получили 44-кратное ускорение и подтвердили, что грамотно спроектированная низкоуровневая оптимизация на Rust — это инструмент, способный решить даже самые ресурсоёмкие задачи с фантастической эффективностью.
💡 Личное мнение автора (и моё тоже):
Разработчики, работающие на высоком уровне, часто забывают, какие потрясающие результаты можно получить, если глубоко погрузиться в детали железа и архитектуры процессора. Rust — язык, который идеально подходит для таких задач, предоставляя мощные инструменты для управления памятью и многопоточностью, сохраняя при этом удобство и безопасность кода. Стоит подчеркнуть, что подобные подходы актуальны не только для парсеров, но и в других высоконагруженных задачах.
Так что в следующий раз, когда ваш код работает слишком медленно, вспомните про этот пример и задайте себе вопрос: «Может быть, пора попробовать что-то подобное?»
🔗 Полезные ссылки и источники:
Теперь вы знаете, как вывести производительность вашего парсера на совершенно новый уровень! 🚀✨