
Каждый, кто хоть раз пытался извлечь полезную информацию из PDF-файлов, знает: традиционный подход через OCR и текстовый парсинг иногда напоминает игру в испорченный телефон. Информация теряется, таблицы превращаются в хаос, а диаграммы лишаются смысла. Недавно компания Morphik предложила принципиально иной подход к поиску и анализу документов: смотреть на них глазами искусственного интеллекта, буквально как на картинки. Почему это важно и как это работает на самом деле?
🎯 В чём проблема традиционного подхода?
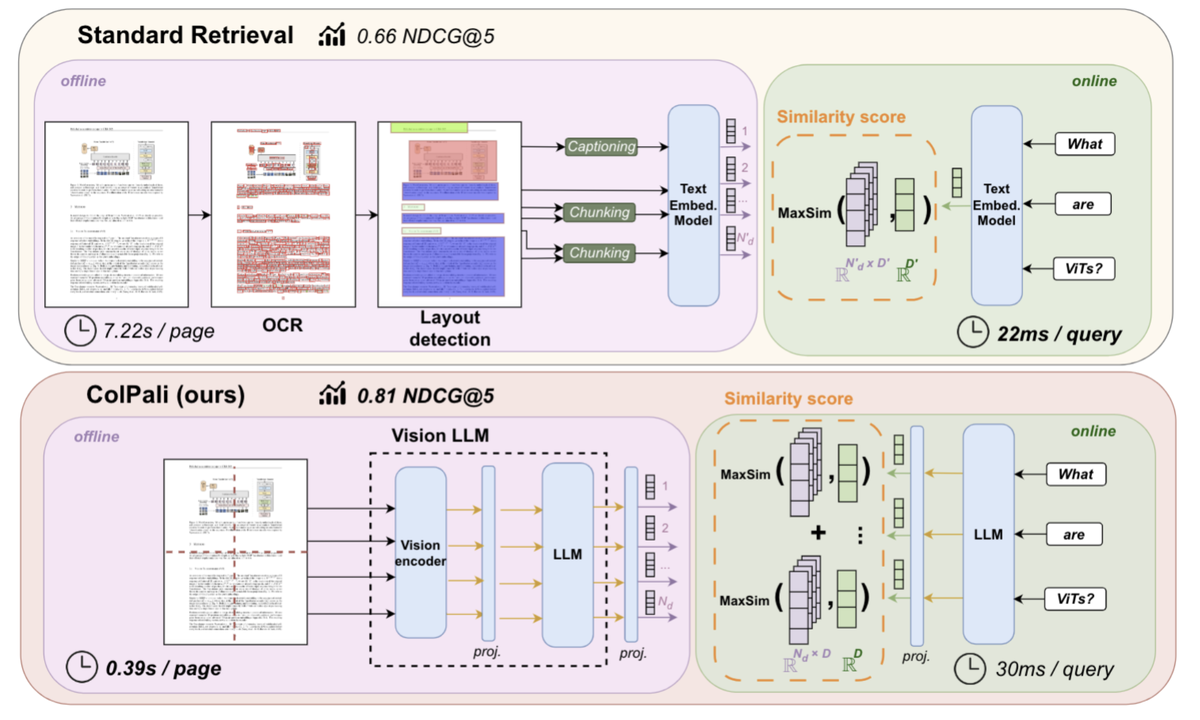
Традиционные системы поиска и анализа документов состоят из множества этапов, каждый из которых способен исказить смысл информации:
- 🌀 OCR: часто путает буквы и цифры, особенно в сложных таблицах и мелких шрифтах.
- 📐 Определение структуры и чтения: таблицы и списки нередко смешиваются, нарушается порядок восприятия информации.
- 📑 Разделение на части («чанкинг»): важные детали отрываются от контекста, из-за чего теряется смысл.
- 🧩 Генерация эмбеддингов и поиск: упрощённые представления документов не учитывают визуальные и пространственные связи.
Результат: при запросах вы получаете искажённые ответы, которые «выглядят» правдоподобно, но далеки от истины.
💡 Как родилась революционная идея?
Идея Morphik возникла из простого вопроса:
«Почему мы разбираем документы на кусочки, чтобы затем заново собрать их смысл?»
Эту мысль озвучил один из основателей компании, Арнав. Он предложил революционный шаг: вместо сложного парсинга рассматривать документ как единую визуальную картинку, так, как это делает человек.
🖼️ Новый подход: Документ = Изображение
Реализация подхода основана на новейших достижениях в области Vision-Language моделей (моделей, понимающих как изображения, так и текст одновременно):
- 📸 Каждая страница документа преобразуется в изображение (высококачественный скриншот).
- 🔳 Изображение разбивается на небольшие участки («патчи»), которые несут как визуальный, так и текстовый контекст.
- 🧠 Vision Transformer-модель (SigLIP-So400m) генерирует «умные» эмбеддинги, которые объединяют визуальную информацию и текст в единый смысловой слой.
- 📚 Языковая модель (PaliGemma-3B) интерпретирует пространственные и логические связи этих патчей, восстанавливая полноценный контекст.
При запросах система применяет «позднее взаимодействие»: она не просто ищет текст, но сопоставляет визуальные и смысловые элементы (например, может определить, какая часть диаграммы относится к «итогам за 3 квартал»).
⚙️ Техническая магия: «Позднее взаимодействие» и MUVERA
Одной из главных технических проблем было ускорение поиска по эмбеддингам изображений. Решение пришло с реализацией подхода MUVERA:
- ⚡ MUVERA сокращает сложный поиск множественных эмбеддингов до быстрого одномерного представления.
- 🚀 Это позволило Morphik сократить задержку при поиске с 3-4 секунд до 30 миллисекунд.
Это достижение перевело технологию из разряда экспериментов в промышленный стандарт, способный справляться с миллионами документов практически мгновенно.
📊 Результаты впечатляют
Независимое исследование и тестирование системы Morphik по сравнению с конкурентами показали фантастические результаты:
- 🎯 Точность Morphik достигла 95.56%, тогда как стандартные решения, основанные на классическом парсинге, показывают лишь 67-72%.
- 🕒 Скорость поиска сократилась в десятки раз, делая систему реально применимой в бизнесе.
📌 Практическое применение: не просто поиск, а понимание
Новый подход особенно эффективен там, где важен визуальный контекст:
- 💹 Финансовые документы (отчёты с графиками и таблицами)
- 🔧 Технические руководства (с детальными схемами и иллюстрациями)
- 📋 Инвойсы и накладные (с позиционными данными и таблицами)
- 🔬 Научные статьи (где ключевые выводы нередко представлены диаграммами и графиками)
- 🩺 Медицинские отчёты (где критично понимать расположение и соотношение элементов)
🔮 Будущее: от поиска к интеллектуальным агентам
Morphik не останавливается на достигнутом. В ближайших планах компании:
- 🌐 Мультидокументный анализ, выявляющий связи между разными документами и источниками.
- 🤖 Агентские системы, способные выполнять сложные цепочки рассуждений и автоматические проверки на согласованность информации.
- 🔗 Интеграция в корпоративные процессы, где система сама сможет выявлять и исправлять противоречия.
💬 Авторское мнение: почему это важный прорыв
Технология Morphik выглядит не просто очередной технической новинкой — это шаг к тому, как действительно должна работать интеллектуальная обработка документов. Люди воспринимают информацию целостно, и попытки разбивать её на кусочки неизбежно приводят к ошибкам. Теперь же впервые машина может «увидеть» документ так же, как человек, сохранив не просто буквы и цифры, а полную картину смысла.
Подход, предложенный Morphik, выглядит логичным продолжением идеи о том, что искусственный интеллект должен становиться ближе к естественным способам мышления и восприятия человека.
Если Morphik удастся реализовать свои планы по развитию интеллектуального анализа, это может коренным образом изменить подход к обработке информации и аналитике документов в целом.
🔗 Оригинальная статья на сайте Morphik
🔗 Описание модели ColPali
🔗 Описание подхода MUVERA
🔗 Технические детали реализации на Morphik