🧠 Теперь можно вычислять LLM, которые «накрутили» баллы на бенчмарказ по математике, но не умеют больше ничего.
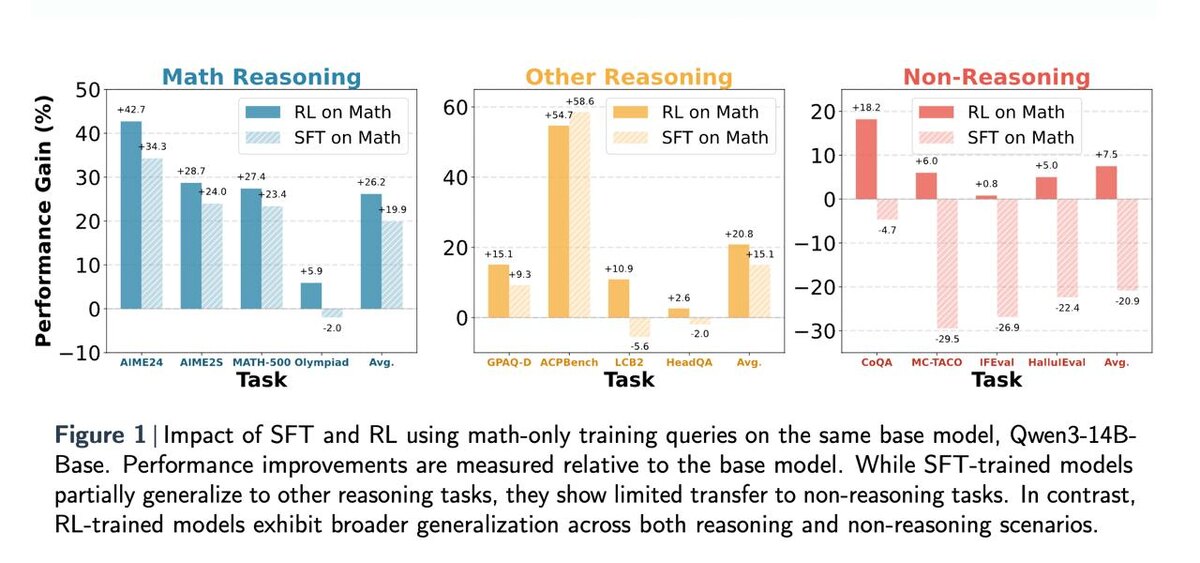
В свежем исследовании *“Does Math Reasoning Improve General LLM Capabilities?”* показано, что модели, обученные на математике с помощью SFT, часто не улучшаются вне математики — а иногда даже деградируют.
📊 Что выяснили:
• SFT на математике → ухудшение на нематематических задачах
• RL на математике → перенос улучшений в другие домены
• SFT вызывает сильное смещение представлений и токен-дистрибуций
• RL наоборот — сохраняет топологию модели и двигает только логические оси
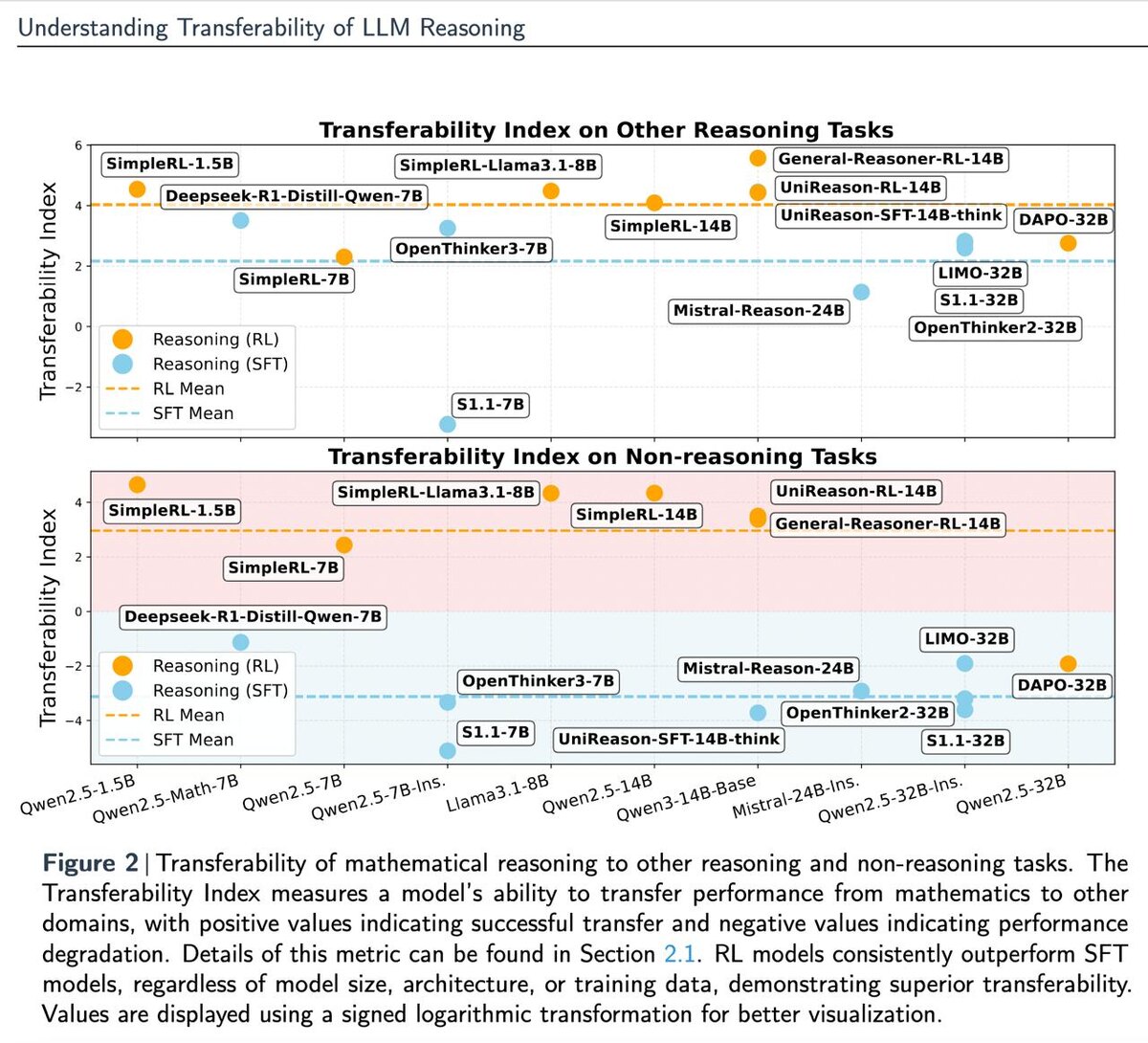
🧪 Авторами разработан новый инструмент — Transferability Index:
Это простое соотношение между улучшением на математике и изменением на сбалансированном наборе задач. Помогает понять:
✔️ где модель реально умнее
❌ а где — просто бенчмарк‑максинг
📌 Вывод: RL-постобучение лучше предотвращает «забвение» и делает LLM более универсальными.
SFT — может казаться эффективным, но часто ухудшает общие способности модели.