
Каждое новое поколение графических процессоров (GPU) от Nvidia — это событие. И презентация архитектуры Blackwell не стала исключением. Эта архитектура оказалась настолько амбициозной, что вызывает вопрос: не достигла ли компания предела своих возможностей? Давайте разберёмся, почему новый GPU Blackwell — это не просто очередное обновление, а настоящий технологический скачок.
🧠 Чем так интересен Blackwell?
GPU Blackwell (чип GB202) от Nvidia — это гигант площадью 750 мм² с невероятными 92,2 миллиарда транзисторов. Это не просто цифры, это вызов физическим пределам современных технологий.
Blackwell продолжает путь, начатый предшествующими архитектурами (Ampere, Ada Lovelace), но вводит важные новшества, которые делают GPU по-настоящему революционным:
- 🎛️ Улучшенная система распределения задач
- ⚙️ Оптимизированная обработка инструкций
- 📈 Гигантская пропускная способность памяти
- 🌐 Повышенная эффективность в задачах AI и графики
🛠️ Технические новинки и их влияние на производительность
🔀 Система распределения нагрузки: почему это важно?
Новый Blackwell оптимизирует структуру работы с потоками задач. Nvidia теперь использует соотношение 1 GPC (Graphics Processing Cluster) на 16 SM (Streaming Multiprocessors), что позволяет увеличить количество вычислительных ядер (SM) без сильного увеличения дополнительных аппаратных расходов.
Сравните:
- 🔷 Nvidia Blackwell: 1 GPC → 16 SM
- 🔶 AMD RDNA4: 1 SE (Shader Engine) → 8 WGP (аналог SM)
Это решение Nvidia позволяет существенно повысить вычислительную мощь при минимальном увеличении сложности устройства.
💡 Улучшенный фронтенд SM и подсистема инструкций
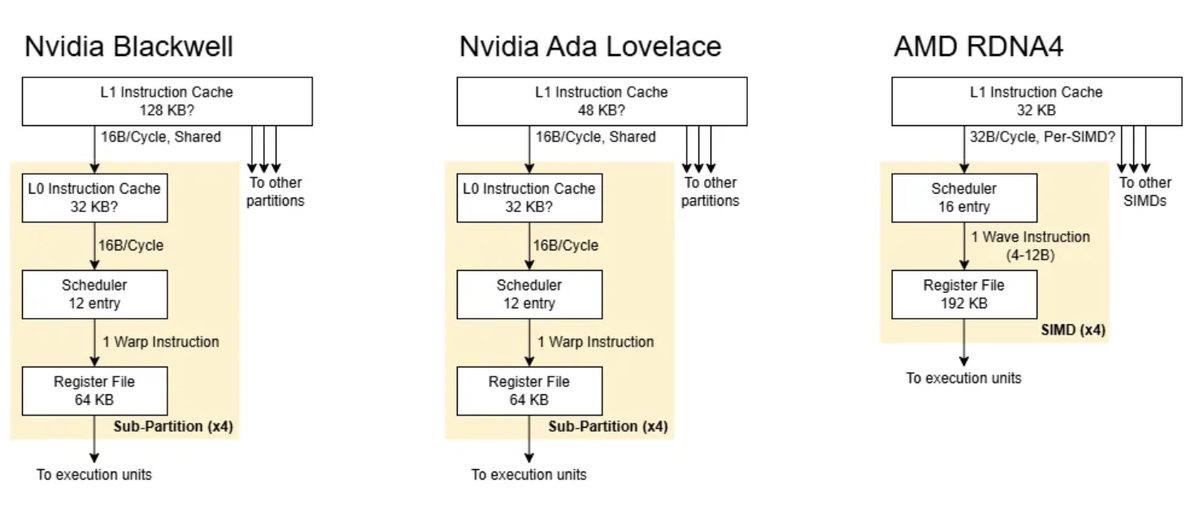
Nvidia сделала шаг вперёд в области обработки инструкций. Теперь каждый SM (аналог ядра GPU) имеет двухуровневый кэш инструкций:
- 🗂️ 128 КБ L1i кэш — обеспечивает быстрый доступ к инструкциям
- 📦 32 КБ L0i кэш в каждой из четырёх частей SM
Такое решение позволяет эффективно обрабатывать большие наборы инструкций без частых обращений к более медленному L2 кэшу, сохраняя производительность на пике.
Интересный факт:
AMD использует переменную длину инструкций (от 4 до 12 байт), тогда как Nvidia фиксирует длину инструкций в 16 байт. Это увеличивает требования к пропускной способности, но делает выполнение команд предсказуемым и быстрым.
⚡️ Мощные вычислительные блоки и новый подход к обработке данных
Каждый SM теперь поддерживает до 12 одновременно активных волн (waves), хотя это немного меньше, чем у AMD (16). При этом Nvidia увеличила производительность, объединив INT32 и FP32 вычисления в один блок размером 32-lane, избавившись от потенциальных задержек.
Интересная деталь:
Nvidia сохранила способность выполнять 16 умножений INT32 за такт, что превышает возможности многих других архитектур, включая Pascal и даже RDNA4.
📀 Память: игра на опережение
Новый Blackwell оснащён:
- 🛡️ 128 КБ гибкой общей памяти на SM (Shared Memory), используемой как для локальных задач, так и для кеша первого уровня.
- 💾 Увеличенный кэш второго уровня (L2) до нескольких десятков мегабайт, что снижает нагрузку на VRAM и значительно ускоряет работу с большими объёмами данных.
⚔️ Nvidia vs AMD: гигант против специалиста
В то время как Nvidia делает ставку на гигантские размеры и массовую параллельность, AMD предпочитает подход меньшего количества ядер, но с большей индивидуальной мощностью и более развитой внутренней памятью.
🟢 Плюсы подхода Nvidia:
- Гораздо большее общее число ядер, что позволяет эффективно масштабировать задачи AI и тяжёлой графики.
- Высокая общая пропускная способность памяти благодаря большой ширине шины и технологии GDDR7.
🟠 Плюсы подхода AMD:
- Более высокая производительность каждого отдельного ядра (WGP), подходящая для менее параллельных задач.
- Меньшие требования к энергии и охлаждению, подходящие для компактных систем.
Однако в сегменте топовых решений именно Blackwell безоговорочно лидирует — по сути, из-за своей способности задействовать огромные масштабы параллелизма и пропускной способности памяти.
📌 Мнение автора статьи: почему Blackwell — важный этап развития GPU?
Архитектура Blackwell показывает, что Nvidia решила одновременно использовать все возможные пути для увеличения производительности. Она не выбирала между большим кешем и высокой пропускной способностью VRAM — она взяла и то, и другое.
Однако такое решение имеет свои последствия:
- 🌡️ Высокое энергопотребление (600 Вт для топовой конфигурации RTX PRO 6000)
- 📐 Сложность производства гигантских чипов (750 мм² — это огромный размер, приближающийся к технологическим пределам).
Тем не менее, Nvidia сумела преодолеть эти проблемы и представила GPU, который станет стандартом производительности на годы вперёд. Сейчас, в 2025 году, Nvidia практически не имеет конкурентов на топовом рынке GPU для персональных компьютеров, и Blackwell — яркое тому подтверждение.
🌟 Выводы и ожидания
На мой взгляд, выход GPU Nvidia Blackwell — это одновременно вызов и стимул для всей индустрии. Конкурентам вроде AMD и Intel придётся догонять, чтобы предложить альтернативу в высокопроизводительном сегменте.
Однако, как потребители, мы получаем от этого только пользу:
- 🚀 Более высокую производительность для AI и 3D-графики;
- 🌍 Ускорение развития всей индустрии GPU;
- 🔬 Новые прорывные решения в вычислительной технике.
Blackwell доказывает: в погоне за лидерством Nvidia не боится сталкиваться с технологическими ограничениями. Именно такие амбициозные решения двигают всю индустрию вперёд.
📚 Источники и ссылки: