
В последнее время крупные языковые модели (LLM) стали основной технологией, меняющей подходы к созданию приложений и сервисов. Однако мало кто задумывается, как именно организована работа таких моделей в реальном времени. Сегодня мы заглянем под капот технологии, на которой базируется популярный движок для работы с LLM — vLLM.
🚀 Почему vLLM так важен?
Современные LLM (например, GPT-4, Llama, Claude и другие) состоят из миллиардов параметров и требуют огромных вычислительных мощностей. Когда пользователь отправляет запрос, модель должна почти мгновенно обработать текст и вернуть результат. На практике это означает, что движок должен работать на пределе возможностей GPU, сохраняя при этом стабильность и масштабируемость.
vLLM — это специализированный движок для обработки запросов к большим языковым моделям, который недавно обновился до версии V1. Его главные задачи:
- 📈 Максимально эффективное использование GPU;
- 🔄 Оптимизация обработки множества одновременных запросов;
- ⚡️ Быстрая потоковая передача результатов обратно пользователю.
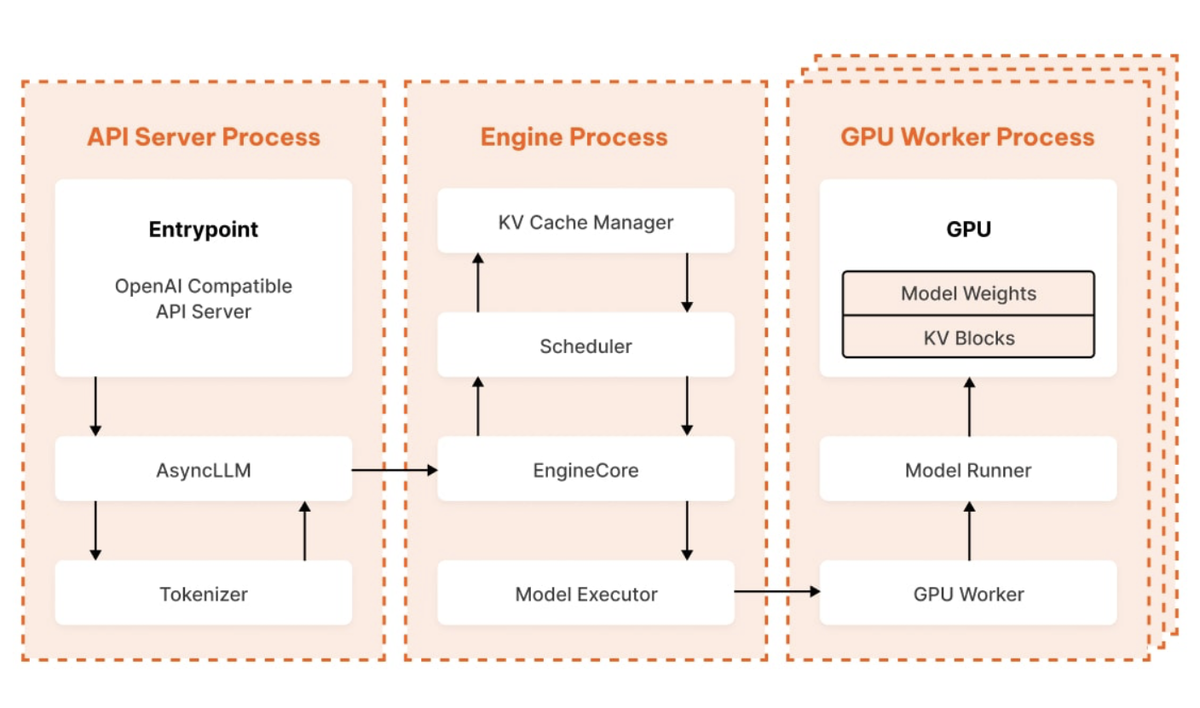
🌐 Путь одного запроса: от HTTP до GPU и обратно
Давайте подробно рассмотрим, как устроена обработка одного запроса в vLLM V1:
1️⃣ Прием и токенизация
Путь начинается с того, что пользователь отправляет HTTP-запрос на сервер API (совместимый с OpenAI API). Сервер выполняет аутентификацию и затем передаёт запрос движку AsyncLLM, который выполняет токенизацию запроса (преобразует текст в числовые токены).
🛠️ Интересный технический нюанс:
Токенизация проходит в отдельном асинхронном процессе, что позволяет обойти GIL (Global Interpreter Lock) Python и параллельно выполнять CPU-интенсивные и GPU-интенсивные задачи.
2️⃣ Асинхронное взаимодействие и планирование
Затем запрос отправляется в EngineCore, сердце движка, через межпроцессное взаимодействие (IPC). Здесь запрос поступает в очередь, и за дело берётся Scheduler.
Scheduler использует продвинутый метод Continuous batching:
- 🎯 Он объединяет разные запросы, чтобы полностью загружать GPU;
- 🔢 Каждый запрос разбивается на части так, чтобы суммарное количество токенов не превышало лимит (например, 10 токенов за один цикл);
- ♻️ Это позволяет одновременно обрабатывать десятки запросов разного размера, не теряя производительность.
Представьте это как тетрис, где Scheduler идеально подбирает запросы по размерам, оптимизируя каждый цикл работы GPU.
3️⃣ Выполнение на GPU и управление памятью
После того как Scheduler выбрал подходящие запросы, наступает этап выполнения. Здесь вступает в игру ModelExecutor:
- 🔥 Модель (например, Llama 4 или GPT) загружается в память GPU, где параллельно обрабатываются все выбранные токены из батча;
- 📚 Ключевую роль играет оптимизация работы с GPU: используются CUDA-ядра, матричные операции SIMD и модуль FlashAttention для сверхбыстрой обработки внимания (attention) между токенами;
- 🗃️ KV Cache хранит промежуточные результаты вычислений для переиспользования в следующих циклах, избегая повторных вычислений и ускоряя генерацию новых токенов.
Факт для любознательных:
FlashAttention-3 — это технология, которая значительно ускоряет вычисления внимания, используя продвинутые алгоритмы обработки данных на GPU.
4️⃣ Потоковая отправка результата обратно
После того как GPU завершает вычисления, токены отправляются обратно через IPC в AsyncLLM, где происходит детокенизация (преобразование чисел обратно в текст). Затем данные сразу же отправляются клиенту в режиме реального времени.
Таким образом, вы видите текст в чате буквально буква за буквой сразу по мере его генерации, без необходимости ждать полной обработки.
🌟 Технологические особенности vLLM V1, которые делают его уникальным:
- 🌀 Асинхронное ядро (AsyncLLM), позволяющее параллельно выполнять задачи на CPU и GPU.
- 🧩 Continuous batching, повышающий загрузку GPU.
- 🚦 Эффективный Scheduler, минимизирующий простои и оптимизирующий производительность.
- 📦 KVCacheManager, управляющий памятью GPU, похожий на систему виртуальной памяти с блоками фиксированного размера.
💡 Авторское мнение: почему это важно для будущего AI?
На мой взгляд, переход на такие архитектуры, как vLLM, — это шаг к появлению более дешёвых, эффективных и масштабируемых AI-сервисов. Такие технологии не просто ускоряют вывод, но и делают использование крупных моделей доступнее для небольших команд и стартапов, снимая необходимость самостоятельно выстраивать сложные инфраструктуры и оптимизации.
Именно благодаря таким подходам, как continuous batching и асинхронное ядро, компании могут предоставлять сервисы уровня ChatGPT Enterprise, сохраняя при этом открытый исходный код и полную прозрачность.
🖇️ Выводы и ссылки для погружения в тему:
Развитие открытых платформ, таких как vLLM, позволяет не просто заглянуть за кулисы того, как работает современный AI, но и активно участвовать в его совершенствовании. Каждый разработчик теперь может настроить и адаптировать инфраструктуру для своих задач, максимально эффективно используя доступные ресурсы.
Тем, кто хочет глубже погрузиться в детали vLLM, рекомендую ознакомиться с:
Эти материалы помогут более глубоко понять и применить технологию vLLM для ваших проектов и задач.