Google DeepMind расширяет линейку своих моделей Gemma
Представлены две новинки:
✔️ T5Gemma — новая жизнь для классической архитектуры encoder-decoder от Google DeepMind
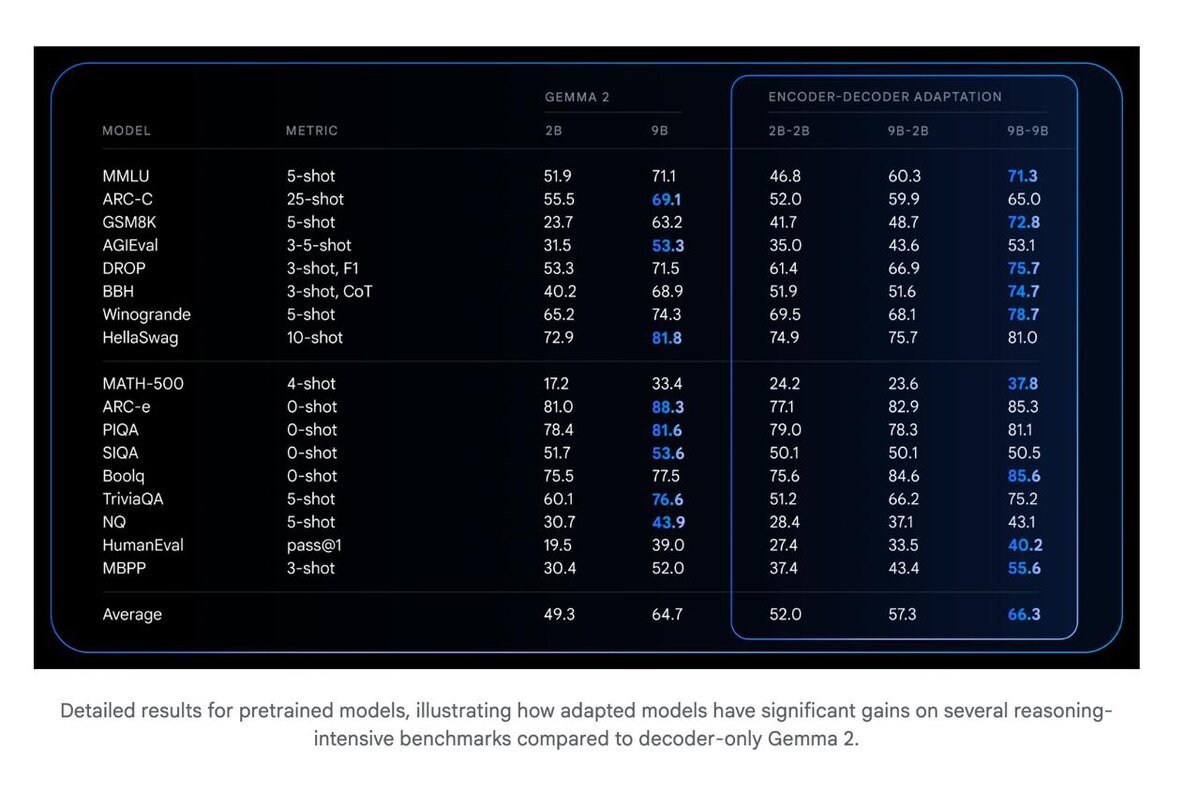
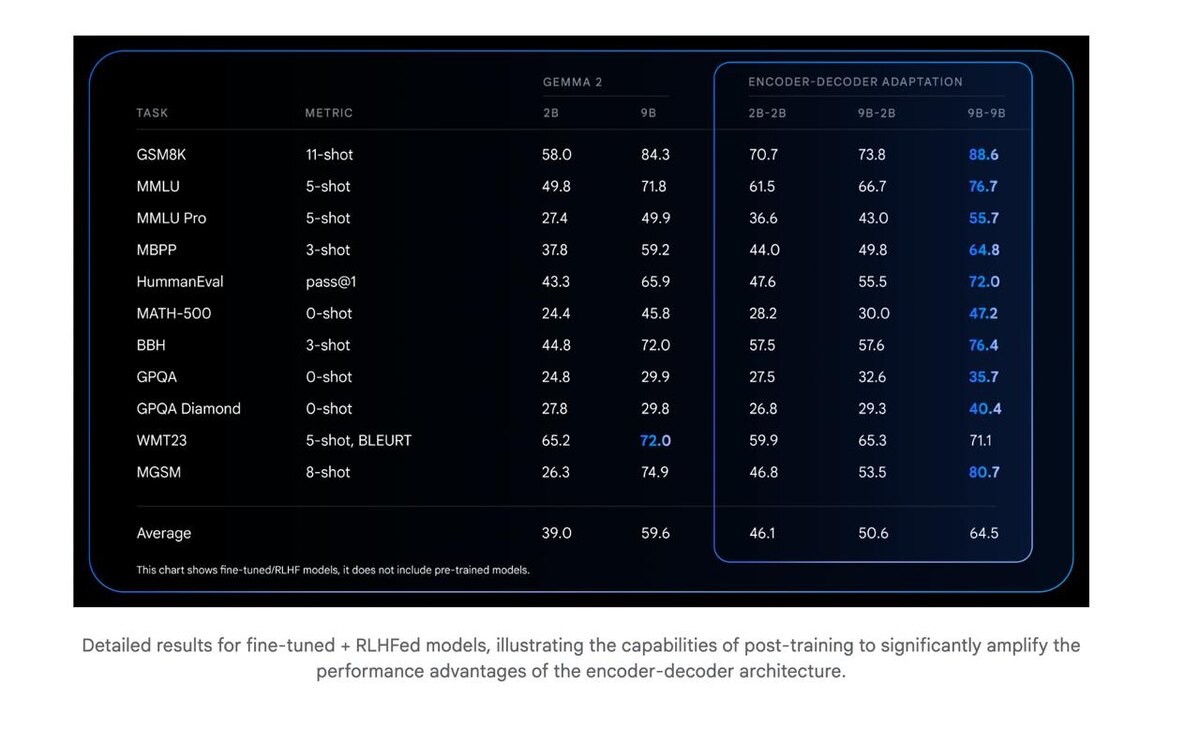
Большинство современных LLM используют архитектуру *decoder-only*, но Google решила напомнить о силе классической схемы *encoder-decoder*, особенно эффективной в задачах вроде перевода, и QA.
Это новая линейка LLM, в которой уже обученные модели Gemma 2 (decoder-only) превращаются в мощные encoder-decoder через метод адаптации. Такой подход даёт сразу два бонуса:
- сохранение знаний из Gemma 2;
- гибкость и эффективность encoder-decoder архитектуры.
Особенности:
- Обновлённая версия Gemma 2 с архитектурой encoder-decoder.
- Отличный баланс между качеством и скоростью инференса (по сравнению с decoder-only).
- Доступны чекпойнты: Small, Base, Large, XL, 2B-2B, 9B-9B, 9B-2B.
- Достигает большей точности, не жертвуя временем инференса.
- Открывает путь к “небалансным” конфигурациям, когда, например, энкодер мощный, а декодер компактный.
✔️ MedGemma — открытые мультимодальные модели для медицины от Google DeepMind
🟡 MedGemma 4B Multimodal
- 64.4% на MedQA — одна из лучших моделей в классе <8B.
- В слепом тесте: 81% отчётов по рентгенам, сгенерированных MedGemma 4B, были признаны квалифицированным рентгенологом достаточно точными для принятия медицинских решений.
- Также показывает SOTA-уровень на задачах медицинской классификации изображений.
🟢 MedGemma 27B (Text + Multimodal)
- 87.7% точности на MedQA — почти как у DeepSeek R1, но в 10 раз дешевле по инференсу.
- Конкурирует с гораздо более крупными моделями на задачах:
- Определение диагноза;
- Интерпретация ЭМК (электронных медкарт);
- Комбинированное понимание текста и изображений.
Открытые модели — можно кастомизировать, дообучать и использовать локально.
🟡T5gemma: https://developers.googleblog.com/en/t5gemma/
🟡MedGemma: https://research.google/blog/medgemma-our-most-capable-open-models-for-health-ai-development/
#GoogleDeepMind #ai #ml #llm #med