
Ещё недавно считалось, что мощность и интеллект языковой модели напрямую зависят от количества её параметров: больше параметров — выше качество. Но технологический мир быстро меняется, и сегодня на первый план выходит баланс между вычислительными затратами, скоростью работы и качеством результата. Именно такой баланс удалось достичь Hugging Face с новой моделью SmolLM3, которая ломает стереотипы и демонстрирует поразительные возможности при всего лишь 3 миллиардах параметров.
📌 Что такое SmolLM3?
SmolLM3 — это компактная (3 млрд параметров) языковая модель от компании Hugging Face, разработанная специально для эффективного решения сложных задач в математике, программировании и аналитическом мышлении. Главные достоинства этой модели можно выразить коротко:
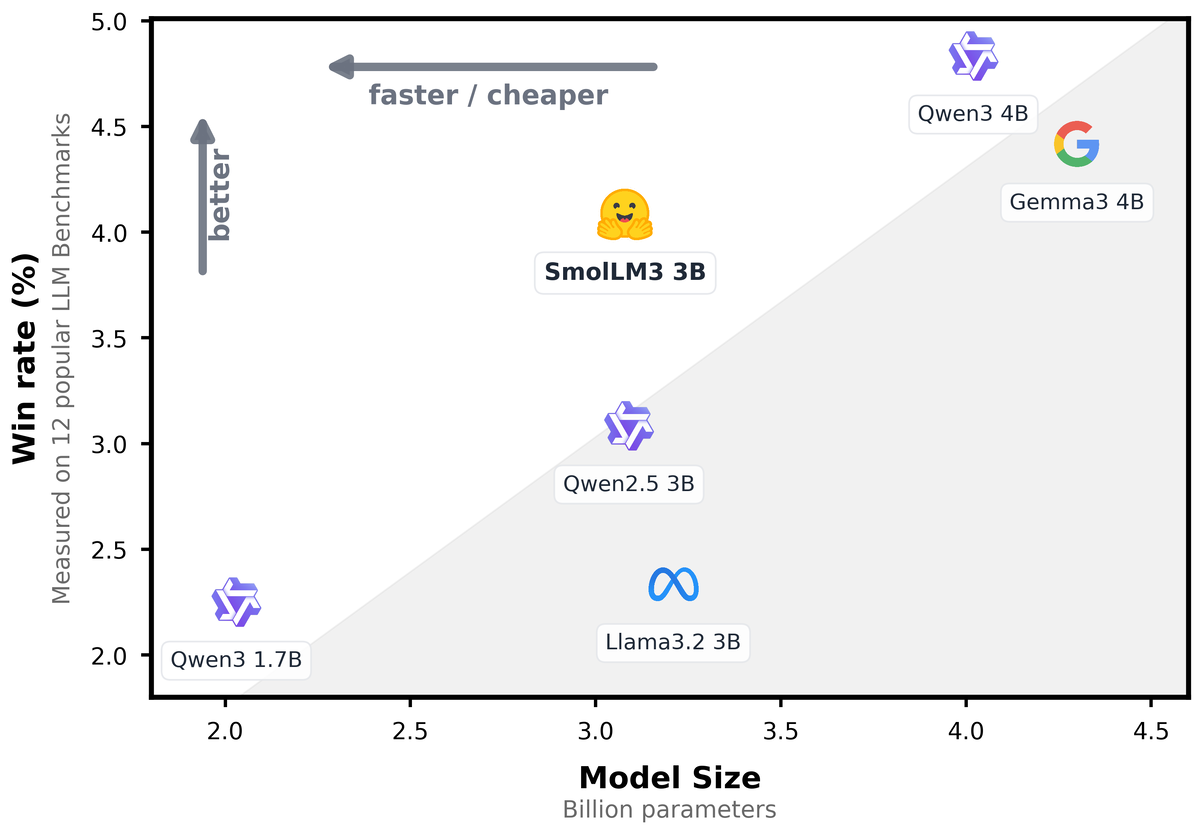
- 🎯 Компактность: превосходит аналоги своего класса (Llama-3.2-3B и Qwen2.5-3B) и успешно конкурирует с более крупными моделями на 4 млрд параметров.
- 🌍 Многоязычность: модель свободно поддерживает 6 языков: английский, французский, испанский, немецкий, итальянский и португальский.
- 🔄 Двурежимная работа: модель умеет переключаться между режимами с рассуждениями (/think) и без (/no_think), адаптируясь к задачам различной сложности.
- 📖 Длинный контекст: поддержка рекордных 128 тысяч токенов благодаря передовым технологиям NoPE и YaRN.
🔧 Как именно работает SmolLM3?
Технические новшества SmolLM3 заслуживают особого внимания, так как именно они обеспечили выдающуюся производительность:
🛠️ Архитектурные инновации
- Grouped Query Attention (GQA):
Вместо стандартного механизма внимания (multi-head attention) модель использует GQA с четырьмя группами запросов, благодаря чему значительно уменьшается память, требуемая при инференсе. - NoPE (No Rotary Positional Embeddings):
Внедрение технологии NoPE позволяет модели эффективно работать с длинными текстами без потери качества при коротких последовательностях. - Intra-Document Masking:
Для улучшения обучения на длинных последовательностях применяется маскирование, которое предотвращает взаимодействие токенов из разных документов, обеспечивая стабильность обучения.
📊 Этапы обучения и дата-миксы
Модель прошла три основные фазы обучения:
- 🚀 Начальный этап (до 8 трлн токенов):
Фундаментальный набор веб-данных (85%), код (12%) и математика (3%). - 🚦 Стабильный этап (8-10 трлн токенов):
Увеличение доли математики (до 10%) и кода (до 15%). - 🏁 Финальный этап (10-11 трлн токенов):
Дополнительное увеличение математики (13%) и кода (24%), а также добавление инструкционных наборов данных.
После основного обучения модель дополнительно тренировали в промежуточных фазах для улучшения работы с длинным контекстом и рассуждениями.
🧪 Специальный этап «mid-training»
- 🔍 Long Context Extension:
Плавно увеличивали контекст модели от 4k до 64k токенов, а с помощью технологии YaRN расширили до 128k токенов. - 💡 Reasoning Mid-training:
Отдельное обучение рассуждениям без привязки к конкретным задачам, что существенно улучшило способности модели к логическим выводам и сложным вычислениям.
🧑💻 Post-training и модель рассуждений
Для финальной настройки модели был использован метод Anchored Preference Optimization (APO), который позволил точно сбалансировать поведение модели между режимами рассуждений и прямых ответов. Также применялось слияние моделей (Model Merging) для улучшения производительности на длинных последовательностях.
📈 Чем модель лучше аналогов?
- 🏅 Высокая эффективность:
SmolLM3 занимает лидирующие позиции в сравнении с другими компактными моделями, показывая высокие результаты в задачах на знание, рассуждение, математику и программирование. - 🌎 Отличная мультиязычность:
Модель стабильно работает на пяти европейских языках, показывая высокие показатели по точности перевода и понимания текста. - ⚖️ Оптимальное соотношение цена-качество:
Модель демонстрирует результаты, близкие к более крупным и дорогим конкурентам, при гораздо меньших затратах ресурсов.
🚩 Личное мнение автора статьи
SmolLM3 — это яркий пример того, как эволюция языковых моделей движется к эффективности и доступности. Я считаю, что будущее за подобными компактными, но мощными системами, которые не требуют огромных вычислительных мощностей, но способны решать практические задачи не хуже гигантских моделей. Особенно ценно, что Hugging Face открывает доступ ко всему рецепту обучения и архитектуре модели, что способствует развитию всего AI-сообщества.
Лично меня впечатляет возможность модели легко переключаться между режимами рассуждения и простых ответов, что делает её очень универсальным инструментом как для бизнеса, так и для исследователей.
📥 Как использовать модель?
Для работы с моделью потребуется установить последнюю версию библиотеки Transformers:
pip install -U transformers
Пример использования:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cuda" # для использования GPU
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
prompt = "Объясни кратко и просто, что такое гравитация."
messages = [
{"role": "system", "content": "/no_think"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
🔗 Полезные ссылки:
SmolLM3 — это шаг в будущее, где большие идеи помещаются в небольшие модели! 🌟