✔️ Kimi-Researcher: End-to-End RL для агентных возможностей
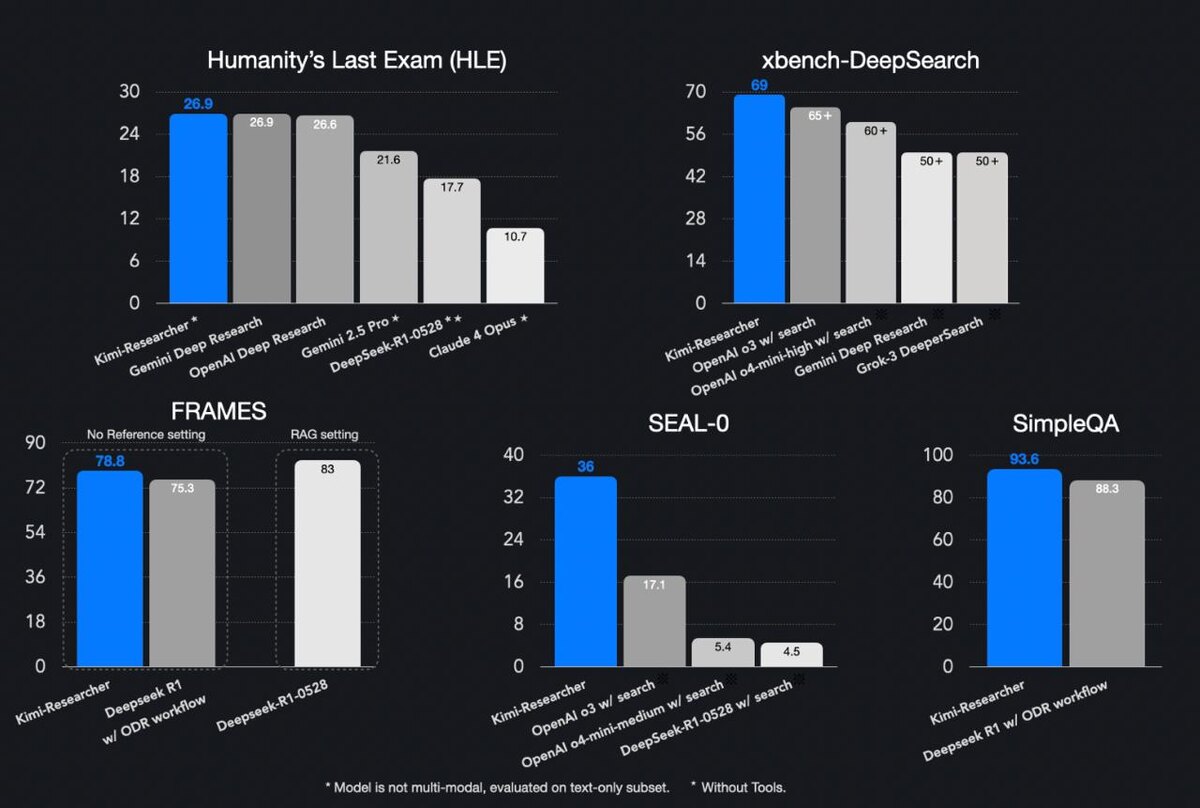
Kimi-Researcher — автономный агент от Moonshot AI, способный решать сложные многоэтапные задачи через поиск и рассуждения. В среднем он выполняет 23 шага рассуждений и анализирует более 200 URL за одну задачу. Построен на внутренней версии модели Kimi k-series и обучен полностью через end-to-end reinforcement learning, достигнув Pass@1 = 26.9 % и Pass@4 = 40.17 % на Humanity’s Last Exam.
Ключевые достижения:
• Pass@1 = 26.9 % и Pass@4 = 40.17 % на Humanity’s Last Exam (тест 17 июня 2025)
• 69 % Pass@1 на xbench-DeepSearch (среднее из 4 прогонов)
• Сильные результаты на FRAMES, Seal-0 и SimpleQA
Архитектура и инструменты:
• Параллельный internal search tool для реального времени
• Текстовый браузер для интерактивных веб-задач
• Кодовый тул для автоматического выполнения и тестирования кода
Преимущества end-to-end agentic RL:
• Обучение единой модели планированию, восприятию и использованию инструментов без ручных шаблонов
• Гибкая адаптация к изменяющимся инструментам и динамическим условиям
• Поддержка длинных траекторий (> 50 итераций) благодаря контекст-менеджеру
Подход к обучению:
1. Синтетические задачи с обязательным вызовом инструментов для надёжного усвоения работы с ними
2. Алгоритм REINFORCE с контролем негативных примеров и γ-декэем для стабильности
3. Контекст-менеджмент: сохранение ключевых документов и отбрасывание «мусора»
4. Асинхронные rollout’ы и Turn-level Partial Rollout для ускорения обучения
Инфраструктура Agent RL:
• Полностью асинхронные rollout’ы с Gym-like интерфейсами
• Turn-level Partial Rollout для задач долгой продолжительности
• Надёжный sandbox на Kubernetes с Model Context Protocol (MCP) для связи агента и инструментов
Emerging agentic capacities:
• Итеративное разрешение противоречий через гипотезы и самопроверку
• Ригорозная перекрёстная верификация фактов перед выдачей ответа
Сценарии применения:
• Академические исследования и юридические обзоры
• Извлечение редкой информации и комплаенс
• Клинические обзоры и финансовый анализ
https://moonshotai.github.io/Kimi-Researcher/
#ai #ml #Agent #rl #Kimi