Июнь в этом году выдался холодным и дождливым, поэтому освободившееся досужее время в промежутке между защитой ВКР и непосредственным получением диплома было решено посвятить прохождению образовательной программы по противодействию кибератакам. В частности, одно из заданий, составляющая практическую часть курса, состояло в анализе логов elasticsearch: всего-то и требовалось, что по известным дате-и-времени (timestamp) начала атаки и "предварительном знании" об использованной "злоумышленником" программе найти требуемые сведения относительно user-agent'a.
Имея определенное представление о том, как выглядит навигация по логам в Kibana, хотелось бы предположить, что с подобным таском способен справиться любой, умеющий подкрутить поисковые фильтры на маркетплейсах и озадачивший себя беглым прочтением теоретического материала.
Однако, не тут-то было.
Первые затруднения
В качестве входных данных было дано следующее:
- timestamp начала атаки,
- известно, что использовалась утилита dirb,
- виртуальная машина с развернутым на ней ELK'om (знакомству с которым была посвящена более ранняя статья), где, собственно, и хранились все записи.
Начать бы здесь следовало с того, что виртуальная машина первоначально оказалась в формате .vmx, предназначенном для VMWare и несовместимом с моим любимым VirtualBox - ну да ничего, OVFTool в помощь, и злополучный .vmx был без особых проблем переконвертирован в .ovf. Более того - о чудо! - в продолжение этой процедуры ничего не поломалось, и распакованная ВМ была успешно запущена в среде виртуализации с первой же попытки.
Ну, а дальше начались сюрпризы.
Во-первых, выдать-то виртуальную машину мне выдали, а вот учетные данные, необходимые для загрузки ОС, сказать забыли - были, правда, логин и пароль от elasticsearch, однако, и они (наряду с тривиальными сценариями вроде admin:admin, root:root, vboxuser:changeme и им подобными) не сработали, поэтому пришлось самой лезть в загрузчик и вручную сбрасывать пароль.
Во-вторых, после перезагрузки и успешного входа в систему оказалось, что графического интерфейса ОС все-таки тоже не завезли: даже после авторизации в системе олдскульная черная консоль оставалась олдскульной черной консолью, начисто лишенной GUI - то есть, проблема состояла не в том, что графическая оболочка почему-то не запустилась, а в том, что она попросту не числилась в списке установленных служб.
А вот это уже, честно говоря, было грустненько, поскольку отсутствие GUI очевидным образом исключало возможность использования Kibana, поэтому было решено попросту установить недостающий GNOME вместе со всем причитающимся набором приложений, необходимых для kibana.
В-третьих, сетевой интерфейс тоже оказался в нерабочем состоянии, в чем было нетрудно убедиться при помощи команды ifconfig:
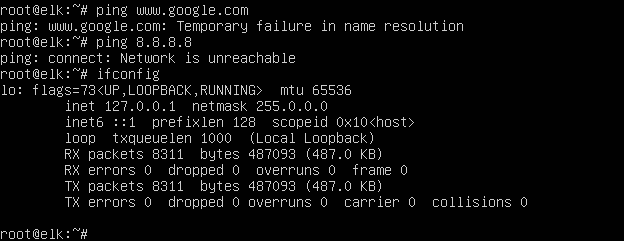
Починить сетевой интерфейс, впрочем, немудрено: при помощи того же ifconfig с параметром -a вывожу список всех доступных сетевых интерфейсов (работающих или нет). Оказалось, что смотрящий "наружу" адаптер зовут (внезапно!) enp0s17, после чего мне оставалось лишь включить его посредством команды
ip link set [имя-интерфейса] up
и присвоить "правильный" (v4) IP-адрес:
dhclient enp0s17
В четвертых, это не помогло. Вернее, помогло лишь в том смысле, что ping 8.8.8.8 выдавал исправный результат, а вот ping www.google.com (равно как и любых других адресов с человеческими именами) возвращал ошибку разрешения имен.
Опять же, пришлось вручную лезть в конфигурационные файлы
nano /etc/resolv.conf
и самостоятельно прописывать
nameserver [IP-адрес-DNS-серверa]
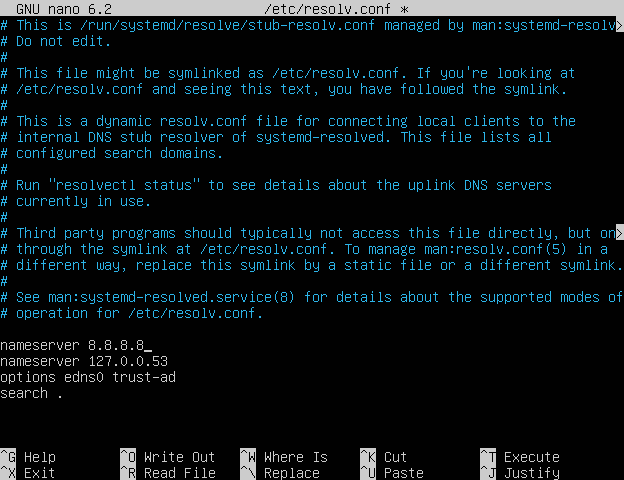
Ура, вроде бы все заработало. Но...
В пятых, устранив проблемы с аутентификацией и сетью (читай: пакетным менеджером), я была вынуждена признать, что GNOME - даже в минимальной комплектации - на эту машину все-таки не лезет. Можно было бы, конечно, дополнительно расширить диск, как это было сделано в одной из предыдущих работ, однако, что-то подсказывало мне, что составители задачки хотели от меня явно не этого, и потому придется как-то обходиться без GUI.
Это присказка, а сказка...
Потратив порядочное количество времени на устранение попутно возникающих проблем, настала пора вспомнить, что пока что я ни на йоту не приблизилась к непосредственному решению поставленной передо мной задачи. Однако, коль скоро к сему моменту у меня уже имелся худо-бедно исправный рабочий стенд, это могло служить отправной точкой.
Первая идея состояла в том, что, коль скоро ELK-сервер был развернут на той же самой ВМ, то и логи должны храниться на ней же - однако, попытка grep'нуть содержимое каталога /var/logs/elasticsearch не привело к успешному результату. Взамен этого, оказалось, что база данных действительно весьма обширна и отчасти хранится в заархивированном виде, а потому искать там что-либо... сами понимаете.
"Непричесанные" логи в elasticsearch, кстати говоря, выглядят примерно вот так - здоровенный такой json, который и на экран-то не вмещается.
Вход в elasticsearch из терминала
Иными словами, стало ясно, что без помощи самого elasticsearch здесь никак не обойтись, а, следовательно, нужно было искать способы взаимодействия с системой, минуя GUI и Kibana. К счастью, к тому моменту я уже имела некоторое представление о том, как аутентифицироваться в elasticsearch из Терминала:
curl -k --user [логин]:'[пароль]' https://localhost:9200
Перевожу на русский язык. Утилита curl совершает запрос веб-страницы, флаги -k --user указывают на то, что будет совершен вход с некими учетными данными, далее следуют логин-пароль (пароль - обязательно в одинарных кавычках!) и URL целевой страницы - elasticsearch, я напоминаю, принимает обращения по 9200-му порту.
Работа с логами elasticsearch из терминала
В систему мы вошли, остается лишь найти способ заставить elasticsearch повращать шестеренками и предоставить доступ к базе данных - а, говоря конкретнее, вполне определенным ее записям, соответствующим критериям поиска.
Хорошая новость состоит в том, что сделать это через "голый" API действительно возможно: отбросив в сторону вопрос о том, сколь много времени у меня ушло на то, чтобы разобраться в мудреном синтаксисе запросов (хороших руководств или референсов на этот счет, увы, нашлось исчезающе мало), скажу, что суть поискового запроса к базе данных elasticsearch состоит в следующем: при помощи того же curl формируется GET-запрос к серверу, который, в случае успеха, возвращет результирующую выборку в формате json... Ну, примерно так:
1. URL
Давайте разбираться, к какому конкретно ресурсу elasticsearch нам требуется обратиться в настоящий момент. Дело в том, что платформа может хранить несколько различных БД (и не только их!), поэтому одного лишь указания на elasticsearch будет недостаточно для доступа к желаемому сервису. Таким образом, url приобретает следующий вид:
"localhost:9200/[индекс]/_search/?pretty"
где:
- localhost:9200 - базовый адрес elasticsearch,
- [индекс] - аналог имени конкретной БД для elasticsearch. В моем случае, он назывался logs* - тут уж, каюсь, без привлечения стороннего OSInt'a не обошлось,
- _search - совершаемое действие, т.е. поиск;
- ?pretty - параметр, позволяющий отображать json в читаемом человеком виде - с разбивом строк, табуляцией и прочими украшениями.
2. Параметры http-запроса
Далее, следует параметр -H 'Content-Type: application/json' - его можно копировать бездумно, т.к. он просто указывает на то, что дальше следует json-запрос.
3. Тело запроса
В простейшем случае, "полезная нагрузка" запроса будет выглядеть вот так:
-d'
{
"query": { "match_all": {} }
}'
Во-первых, обратите внимание - все, что следует после флага -d, берется в одинарные кавычки. Это важно, потому что иначе ничего работать не будет.
Во-вторых, имеет смысл оговорить то, что вообще представляет собой json- формат. В общем виде, его суть и смысл заключается в представлении данных в виде {'ключ': 'значение'} - опять же, обязательно с кавычками.
Всего лишь.
Правда, есть нюанс: такие конструкции бывают вложенными:
{'ключ 1': {'ключ 2': 'значение 2'} }
т.е., "значением 1" в данном случае будет являться пара {'ключ 2': 'значение 2'}.
Возможны перечисления, они берутся в квадратные скобки:
{'ключ 1': [{'ключ 2': 'значение 2'}, {'ключ 3': 'значение 3'}] }
Но давайте посмотрим, как это выглядит на практике:
3.1. Поиск по значению
Предположим, я хочу найти все записи с нужным мне значением timestamp:
{
"query": {
"match": {
"@timestamp": "2023-12-12"
}
}
}
Разбираем по частям. Здесь,
- "query" - универсальный заголовок для поискового запроса,
- "match" - критерий поиска, в данном случае ищем полное или частичное совпадение,
- "@timestamp" и "2023-12-12" - искомые поле и значение соответственно.
3.2. Поиск по полям
В других случаях я не знаю, какое именно значение может принять поле, но догадываюсь, что оно явно должно там быть. В данном случае, я хочу, чтобы запись содержала графу "user-agent.os.full":
{
"query": {
"exists": {
"field": "user-agent.os.full"
}
}
}
Аналогичным образом, в начале идёт query, затем критерий поиска - "exist", и, наконец, самая глубоко вложенная скобка говорит о том, что меня интересует поле (field) с названием user-agent.os.full.
3.3. Поиск с несколькими условиями
В подавляющем большинстве случаев запрос к БД подразумевает сразу несколько критериев поиска. И тут в игру вступает конструкция bool, позволяющая соединять отдельные критерии при помощи логических операторов - в данном случае, подразумевается логическое 'И':
{
"query": {
"bool" : {
"must": {[
{"exists": {"field": "user-agent.os.full"} },
{ "match": {"@timestamp":"2023-12-12"}},
{"match": {"http.responce.status_code": "404"} }
]}
}
}
}
Ух. Понятно, что это далеко не все возможности, предоставляемые API elasticsearch, но для начала хватит.
Единственная проблема состоит в том, что в примитивном черно-белом терминале нет красивых отступов и табуляции, и потому все это выглядит примерно вот так:
Выводы
Так или иначе, а по итогам всех вышеобозначенных изысканий мне удалось найти нужные данные - однако, что бы уж откровенно не "сливать" решение, здесь я не стану доводить его до конца.
В данной статье мы разобрались с тем, как работать c elasticsearch напрямую через API, а именно авторизоваться в системе и совершать запросы к базе данных, а также - что, на мой взгляд, не менее важно - составили некоторое представление о том, во что может вылиться "тривиальная" задача в IT.
От себя же добавлю, что подобные сценарии, когда "ничего не работает" и попутно приходится решать с десяток динамически возникающих проблем являет собой будничную прозу жизни IT-специалиста, в то время как умение бороться с ними "на лету" - неотъемлемым качеством, необходимым для выживания в рамках специальности. Так что решайте сами, нужно оно вам или нет, или же "модный IT" все-таки не про вас.
Оставайтесь на связи.