
В эпоху цифровой трансформации системы, обрабатывающие миллионы запросов в секунду и анализирующие терабайты данных в режиме реального времени, стали стандартом для технологических гигантов (Uber, Netflix, Airbnb). Python, благодаря простоте и богатой экосистеме, позволяет строить такие системы, сочетая производительность с быстротой разработки. Рассмотрим ключевые аспекты их создания.
1. Ключевые требования к высоконагруженным системам
- Производительность: <100 мс задержки для 99% запросов (P99).
- Масштабируемость: Горизонтаное расширение под нагрузкой.
- Отказоустойчивость: Минимальное время восстановления (MTTR < 1 мин).
- Консистентность: Баланс между согласованностью данных и доступностью (CAP-теорема).
2. Архитектурные паттерны
а) Микросервисы
Разделение системы на независимые компоненты (API-шлюз, сервис аутентификации, обработчик данных), общающиеся через брокеры сообщений.
б) CQRS (Command Query Responsibility Segregation)
- Команды: Запись данных через Kafka/Flink.
- Запросы: Чтение из оптимизированных хранилищ (Elasticsearch, Cassandra).
в) Event Sourcing
Хранение всех изменений состояния системы как последовательности событий.
3. Стек технологий Python
Категория Инструменты
API-фреймворки FastAPI (ASGI + async), Tornado, Sanic
Стриминг данных Apache Kafka, Faust, Flink Python API
Базы данных Cassandra, ScyllaDB, Redis, TimescaleDB
Кэширование Redis, Memcached
Оркестрация Kubernetes, Docker Swarm
4. Оптимизация API: FastAPI в действии
Пример высокопроизводительного эндпоинта:
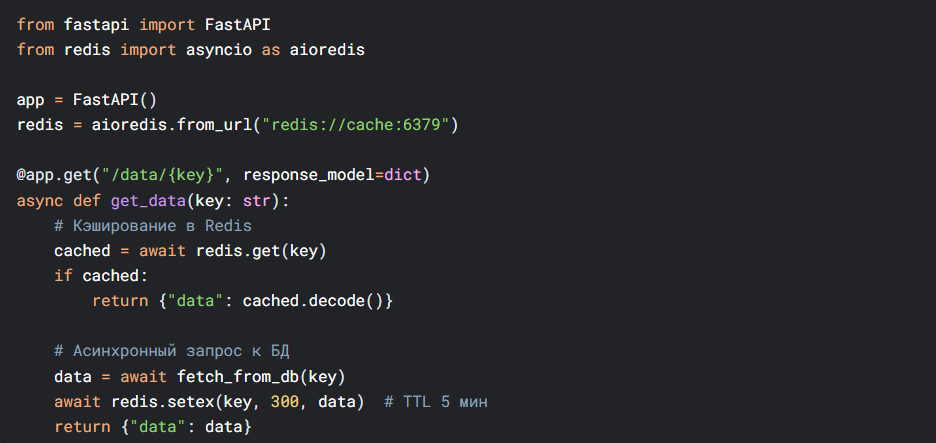
Оптимизации:
- Асинхронность: Использование async/await для неблокирующих операций.
- Кэширование: Redis для снижения нагрузки на БД.
- Сжатие: GZIP-мидлварь для уменьшения трафика.
- Rate Limiting: Ограничение запросов в секунду.
5. Обработка данных в реальном времени: Kafka + Faust
Архитектура пайплайна:
Датчики → Kafka → Faust (Stream Processing) → InfluxDB → Grafana (Dashboard)
Пример обработчика на Faust:
Ключевые операции:
- Оконные агрегации: Сумма/среднее за временные интервалы.
- Обогащение данных: Добавление геоданных из Redis.
- Аномалии: Обнаружение отклонений через ML-модели scikit-learn.
6. Горизонтальное масштабирование
- API-уровень:
Kubernetes Load Balancer + Pod Autoscaler (HPA) на основе CPU/RPS.
- Очереди Kafka:
Партиционирование топиков + увеличение числа консьюмеров.
- Базы данных:
Шардирование Cassandra по ключам устройств.
7. Мониторинг и диагностика
- Метрики: Prometheus + Grafana (RPS, задержки, ошибки).
- Трассировка: Jaeger/Zipkin для отслеживания запросов в микросервисах.
- Логи: ELK-стек (Elasticsearch, Logstash, Kibana).
Alerting-правило Prometheus:
8. Безопасность
- API: OAuth2/JWT через FastAPI Security.
- Данные: Шифрование TLS 1.3 + at-rest шифрование в S3.
- Инфраструктура: Изоляция сети через Kubernetes Network Policies.
9. Антипаттерны: чего избегать
- Блокирующие вызовы: Синхронные операции в основном потоке.
- Over-fetching: Выгрузка избыточных данных из БД.
- Холодный кэш: Старт системы без предзагрузки кэша.
- Гонки данных: Отсутствие идемпотентности в обработчиках событий.
10. Реальные кейсы
- Uber:
- Python + Go: Геоаналитика на Python, микросервисы на Go.
- Kafka: >100 млрд сообщений/день.
- Spotify:
- Faust: Обработка стриминговых событий для рекомендаций.
Заключение
Построение высоконагруженных систем на Python требует:
1. Правильного выбора архитектуры (микросервисы, CQRS).
2. Использования асинхронных фреймворков (FastAPI) и стриминг-платформ (Kafka/Faust).
3. Инфраструктурной зрелости: Kubernetes, Service Mesh.
4. Постоянного мониторинга и оптимизации.
Инструменты для старта:
- Локальное тестирование: k6 (нагрузочное тестирование).
- Шаблон проекта: cookiecutter-fastapi + docker-compose с Kafka.
Python продолжает эволюционировать в высоконагруженных сценариях, предлагая баланс между скоростью разработки и производительностью, особенно с новыми инструментами (Pydantic V2, uvloop) и практиками (компиляция через Cython/Numba).
Подписывайтесь:
Телеграм https://t.me/lets_go_code
Канал "Просто о программировании" https://dzen.ru/lets_go_code