
Dask — это мощная библиотека Python для параллельных и распределённых вычислений, позволяющая работать с данными, превышающими объём оперативной памяти (RAM), и эффективно использовать многоядерные процессоры или кластеры. Она интегрируется с экосистемой Python (NumPy, Pandas, Scikit-learn), предоставляя знакомые интерфейсы для масштабируемости.
1. Зачем нужен Dask?
- Проблема: Ограничения Pandas/NumPy при работе с данными > 100 ГБ (нехватка RAM, медленные операции).
- Решение Dask:
- Автоматическое разбиение данных на части (chunks).
- Параллельные вычисления через граф задач (task graph).
- Поддержка кластеров (Kubernetes, YARN, облака).
- Ключевые преимущества:
- Отложенные вычисления (ленивые операции).
- Минимальное изменение кода для Pandas/NumPy.
- Динамическая балансировка нагрузки.
2. Основные Компоненты Dask
2.1 Dask Array
Аналог NumPy для работы с большими массивами.
import dask.array as da
# Создание массива 20 000 x 20 000 (разбитого на блоки 1000x1000)
x = da.random.random((20000, 20000), chunks=(1000, 1000))
y = x + x.T # Транспонирование и сложение
result = y.mean().compute() # Запуск вычислений
Особенности:
- Оптимизированные операции: `sum()`, `mean()`, SVD.
- Интеграция с CuPy для GPU.
2.2 Dask DataFrame
Аналог Pandas для табличных данных.
import dask.dataframe as dd
# Чтение 1000 CSV-файлов
df = dd.read_csv("data/*.csv", blocksize=25e6) # 25 MB на блок
result = df.groupby("category").price.mean().compute()
Особенности:
- Поддержка groupby, join, pivot_table.
- Совместимость с Parquet, HDFS, S3.
2.3 Dask Bag
Для обработки полуструктурированных данных (JSON, логов).
import dask.bag as db
# Обработка JSON-файлов
b = db.read_text("logs/*.json").map(json.loads)
filtered = b.filter(lambda x: x["error"]).pluck("message")
result = filtered.take(10) # Получить 10 записей
2.4 Dask Delayed
Параллелизация произвольного кода.
from dask import delayed
@delayed
def process_data(x):
....return x * 2 + 3
results = [process_data(i) for i in range(100)]
total = delayed(sum)(results)
total.compute() # Запуск всех задач
2.5 Dask-ML
Масштабирование Scikit-learn.
from dask_ml.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train) # X_train — Dask Array
predictions = model.predict(X_test)
Поддерживает: KMeans, PCA, GridSearchCV.
3. Установка
pip install "dask[complete]" # Основные компоненты
pip install dask-ml # Для ML
4. Графы Вычислений
Dask строит направленный ациклический граф (DAG) операций.
import dask
x = delayed(process_data)(1)
y = delayed(process_data)(2)
z = delayed(sum)([x, y])
# Визуализация графа
z.visualize(filename="graph.png")
```
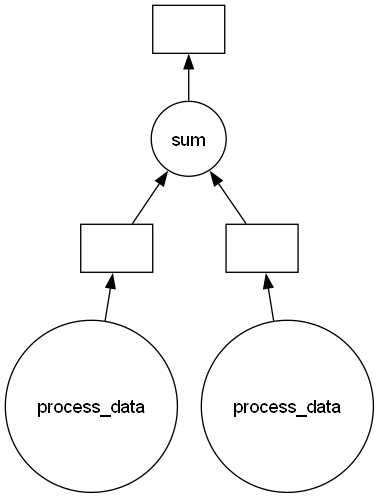
5. Работа с Кластерами (Dask Distributed)
Локальный кластер:
from dask.distributed import Client
client = Client(n_workers=4) # 4 процесса
Запуск в облаке (AWS, GCP):
from dask_cloudprovider import EC2Cluster
cluster = EC2Cluster(n_workers=10)
client = Client(cluster)
6. Оптимизация Производительности
- Выбор размера блока (chunk size):
- Для массивов: chunks="auto".
- Для DataFrame: blocksize=64e6 (64 MB).
- Советы:
- Избегайте .compute() в цикле — собирайте все задачи.
- Используйте persist() для сохранения данных в RAM.
- Оптимизируйте граф с помощью dask.optimize().
7. Ограничения Dask
- Не подходит:
- Для маленьких данных (используйте Pandas/NumPy).
- Для реал-тайм обработки (лучше Spark/Flink).
- Если операции не параллелизуемы.
- Сложности:
- Отладка распределённых задач.
- Настройка кластера.
8. Пример: Анализ 1 ТБ Данных
# Чтение данных из S3
df = dd.read_parquet("s3://bucket/data/year=*/")
# Анализ
result = (
df[df.balance > 1000]
.groupby("user_id")
.agg({"amount": ["sum", "mean"]})
.compute() # Запуск на кластере
)
Заключение
Dask — идеальный инструмент для:
- Масштабирования Pandas/NumPy на большие данные.
- Параллелизации пользовательского кода.
- Интеграции с современным стеком данных (Parquet, S3, Kubernetes).
Ресурсы:
- Dask Tutorial (Jupyter Notebooks)
Используйте Dask, чтобы выйти за пределы одной машины, сохраняя привычный код Python!
Подписывайтесь:
Телеграм https://t.me/lets_go_code
Канал "Просто о программировании" https://dzen.ru/lets_go_code