Современные большие языковые модели (LLM), такие как GPT-4, DeepSeek или Gemini, сегодня активно внедряются в самые разные области, от помощи в написании кода до решения задач автоматизированного рассуждения. Однако при всей их впечатляющей продуктивности остаётся фундаментальный вопрос: насколько можно доверять результатам, выдаваемым такими моделями, если от решений требуется абсолютная точность и детерминированность?
📌 Проблема неопределённости в больших языковых моделях
Несмотря на то, что LLM могут генерировать сложные формальные спецификации и даже формальные доказательства, они остаются по своей природе вероятностными. В отличие от формальных методов, которые обеспечивают строгие математические гарантии точности и надежности, LLM строят ответы на основе вероятностных распределений. Таким образом, формальный вывод с использованием LLM неизбежно сталкивается с проблемами неопределённости.
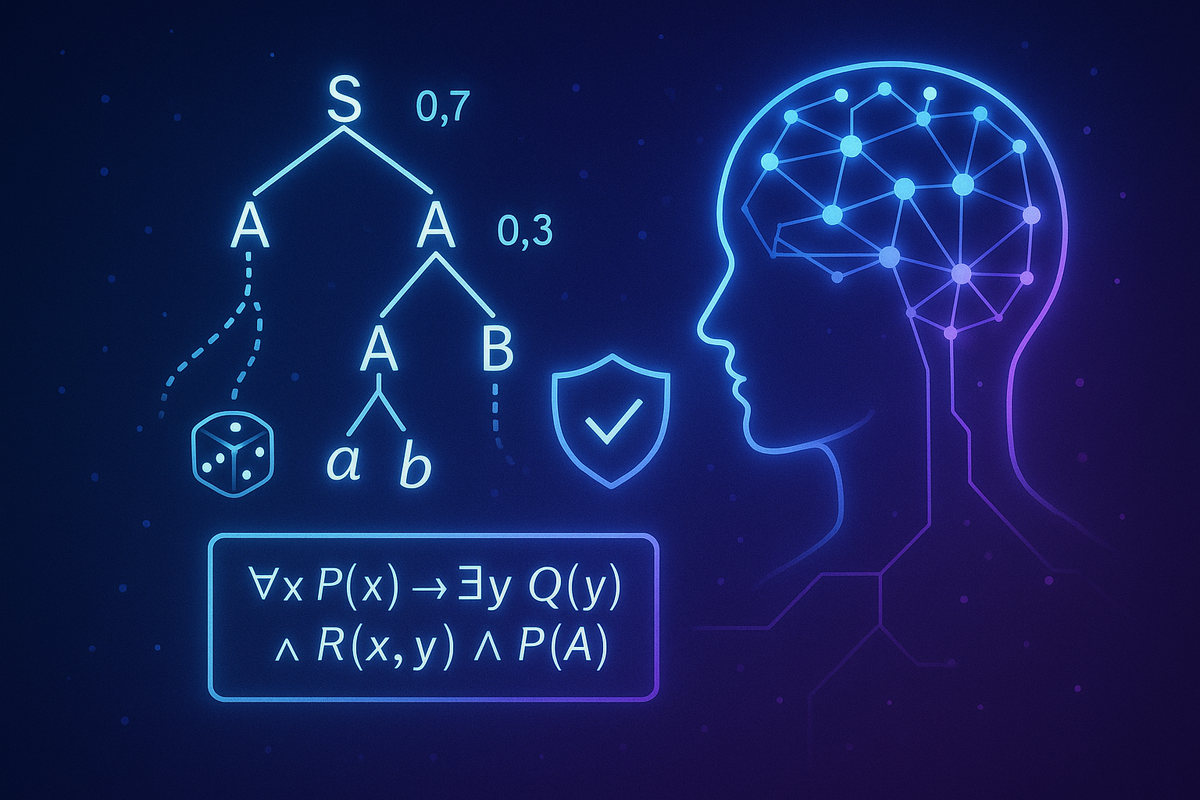
Исследователи из Case Western Reserve University и Microsoft предложили новый подход к анализу неопределённости — грамматики формальной неопределённости, основанные на вероятностных контекстно-свободных грамматиках (PCFG). Они утверждают, что вместо того, чтобы считать неопределённость недостатком, её следует использовать для лучшего понимания и контроля над процессом формализации с помощью LLM.
📌 Что такое грамматики формальной неопределённости (PCFG)?
Вероятностные контекстно-свободные грамматики (PCFG) — это расширение обычных контекстно-свободных грамматик, в которых правилам вывода приписываются вероятности. Исследователи используют эти грамматики для моделирования неопределённости в формальных спецификациях, сгенерированных LLM.
Используя PCFG, исследователи выявили несколько категорий неопределённости:
- 🔍 Эпистемическая неопределённость знаний (незнание фактов).
- 🔄 Эпистемическая неопределённость процедур (ошибки в логике вывода).
- 📐 Рекурсивная сложность (чрезмерное усложнение структуры вывода).
- 📉 Ограничения ёмкости (неспособность модели чётко формулировать спецификации при больших объёмах информации).
Эти категории дают значительно более тонкое понимание того, почему LLM допускают ошибки при формализации.
📌 Как измерить неопределённость?
Для количественной оценки неопределённости исследователи предложили набор специальных метрик, основанных на анализе грамматик, таких как:
- 📊 Энтропия грамматики — показывает, насколько неопределённым является выбор правил вывода.
- 📈 Перплексия — оценивает, как грамматика предсказывает дальнейшие шаги формализации.
- 📏 Спектральный радиус — отражает сложность рекурсивной структуры.
Эти метрики доказали свою эффективность в обнаружении ошибок и неопределённостей, позволяя проводить выборочную формальную верификацию только тех выводов, которые содержат признаки повышенного риска ошибок.
📌 Эффективность нового подхода
Использование PCFG и связанных с ними метрик существенно повысило надёжность формализации, выполняемой языковыми моделями:
- ✅ Снижение ошибок от 14% до 100% при минимальном отказе от проверок.
- ✅ Высокая точность идентификации ошибок на логических задачах (например, AUROC более 0.93 для энтропии грамматики).
Это открывает возможности для создания новых, более надёжных и понятных нейросимвольных систем, которые могут быть внедрены в ответственные области — от программной инженерии до автоматизированного доказательства теорем.
📌 Взгляд автора: будущее LLM и формальных методов
На мой взгляд, предложенный подход радикально меняет представление о неопределённости в работе LLM. Вместо того чтобы считать её критическим недостатком, мы теперь можем воспринимать её как ценный ресурс для оценки надёжности модели. Этот подход может стать важным шагом на пути к более широкой интеграции LLM в критические сферы, где требуется высокая степень уверенности и надёжности — такие как медицина, автоматизированная верификация программного обеспечения и безопасность.
Однако стоит помнить, что никакие метрики не заменят полностью человеческий контроль. Грамматики формальной неопределённости являются мощным дополнением к уже существующим средствам контроля, но не их заменой.
Таким образом, в ближайшие годы мы, вероятно, увидим дальнейшее развитие подобных методик, интегрирующих вероятностные методы с традиционной формальной логикой, создавая прочную основу для по-настоящему надёжных интеллектуальных систем.