Автор — Алиса Годованец
Вы когда-нибудь замечали, что уже через несколько секунд после начала выступления понимаете, будет ли оно интересным? Оказывается, это не просто субъективное ощущение, а научно подтверждённый феномен. Исследование Schmaelzle et al. (2025) из Мичиганского университета показывает: даже крошечные фрагменты научных презентаций — всего 1-5% от общей длительности — позволяют точно предсказать качество всего выступления. И что особенно интересно — эту оценку теперь могут проводить не только люди, но и языковые модели искусственного интеллекта.
Концепция "тонких срезов" (thin slices) в социальной психологии существует уже несколько десятилетий, но до сих пор она редко применялась к анализу публичных выступлений, особенно научных. А ведь именно в науке эффективная коммуникация критически важна — от неё зависит, дойдут ли важные открытия до коллег, получит ли исследователь грант или работу мечты. Давайте разберёмся, как искусственный интеллект помогает понять магию первого впечатления и почему первые слова решают всё.
Теория тонких срезов: когда мгновения решают всё
История изучения "тонких срезов" началась с классических работ Ambady и Rosenthal (1992, 1993). В своём знаменитом исследовании 1993 года они обнаружили поразительный факт: наблюдатели могли предсказать итоговые оценки преподавателей в конце семестра, посмотрев всего 30 секунд беззвучного видео с их занятий. Никакого звука, никаких слов — только невербальное поведение. И этого оказалось достаточно!
С тех пор исследователи обнаружили, что "тонкие срезы" работают в самых разных областях: мы можем оценить компетентность врача, теплоту в отношениях, личностные характеристики и даже исход судебных процессов по минимальным фрагментам поведения. Мета-анализы подтверждают: через различные социальные домены тонкие срезы предсказывают важные выводы с удивительной точностью.
Кстати, если вас заинтересовала эта тема, очень рекомендую книгу Малкольма Гладуэлла "Сила мгновенных решений" (Blink). Я упоминала её в одном из наших подкастов — это блестящее популярное изложение научных исследований о том, как наш мозг принимает молниеносные решения на основе минимальной информации. Гладуэлл рассказывает увлекательные истории: от эксперта, который за секунды определил подделку древнегреческой статуи, до психологов, предсказывающих развод пары по нескольким минутам разговора. Книга прекрасно дополняет академические исследования живыми примерами из реальной жизни.
Но вернёмся к науке. Большинство исследований фокусировалось на невербальном поведении. А как насчёт самого содержания речи? Ведь в научных презентациях именно контент играет ключевую роль. И здесь на сцену выходят большие языковые модели.
Методология: как ИИ учится оценивать выступления
Исследователи собрали уникальный корпус из 160 научных презентаций. Это были реальные выступления учёных (аспирантов и преподавателей), которые представляли свои исследования перед аудиторией в виртуальной реальности. Каждая презентация длилась 8-12 минут — типичный формат для научной конференции.
После фильтрации по качеству записи осталось 128 презентаций — это более 100 000 секунд и почти четверть миллиона произнесённых слов. Целый день конференции! Все выступления были транскрибированы с помощью OpenAI Whisper и вручную проверены на ошибки.
Затем исследователи нарезали каждую транскрипцию на "срезы" разного объёма: 1%, 5%, 10%, 20%, 30%, 40%, 50%, 75% и 100% от полного текста. Для презентации средней длины 1% — это всего 15 слов, а 5% — около 60 слов. При типичной скорости речи 100-150 слов в минуту это соответствует знаменитому "правилу семи секунд" из популярной литературы о публичных выступлениях.
Для оценки использовались две продвинутые языковые модели: GPT-4o-mini и Gemini Flash 1.5. Каждая модель оценивала все 128 презентаций во всех срезах, используя пять разных формулировок промптов. В общей сложности было получено 11 520 оценок — и весь процесс занял около часа.
Валидация: а судьи кто?
Конечно, возникает вопрос: насколько оценки ИИ соответствуют человеческому восприятию? Для проверки исследователи провели эксперимент с 60 людьми-оценщиками (средний возраст 38,2 года). Каждый участник читал и оценивал качество 20%-ных фрагментов презентаций — это примерно полстраницы текста, что посильно для внимательного прочтения.
Результаты впечатляют: согласованность между оценщиками-людьми была очень высокой (ICC = 0,92 и 0,86 для двух групп). Это означает, что люди демонстрируют высокий уровень согласия относительно того, какие выступления хорошие, а какие — не очень.
Но самое главное — корреляция между усреднёнными человеческими оценками и оценками ИИ составила r = 0,69 (p < 0,0001). Это довольно сильная связь, которая показывает: ИИ и люди оценивают качество презентаций весьма похоже.
Результаты: магия первых слов
Центральный вопрос исследования звучал так: может ли небольшой фрагмент презентации предсказать её общее качество? Ответ — решительное "да".
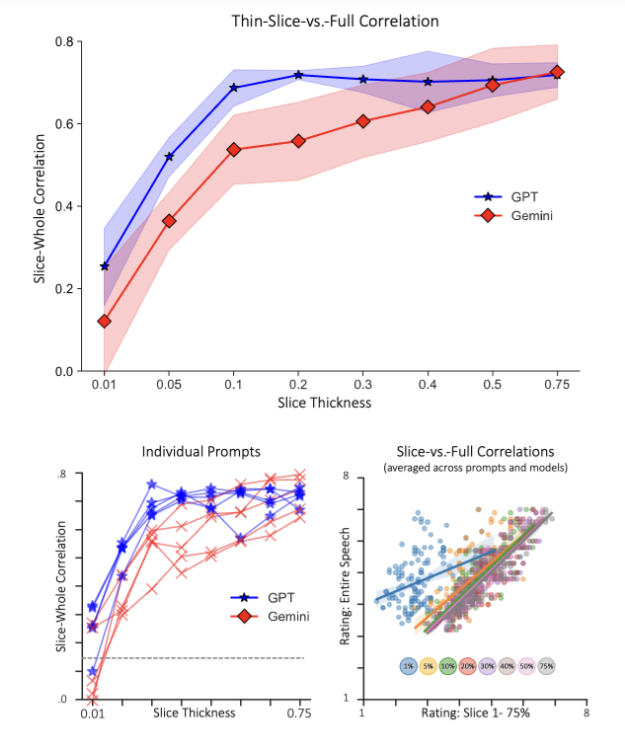
График корреляций между оценками фрагментов и полных презентаций показывает удивительную картину:
- Уже при 1% текста (15 слов!) корреляция положительная
- При 5% (60 слов) корреляция становится статистически значимой для всех моделей и промптов
- При 10% достигается плато — корреляция выходит на уровень 0,6-0,7
- Дальнейшее увеличение объёма практически не улучшает предсказание
Это означает, что уже после первых 10% презентации (примерно 1-2 минуты) формируется устойчивое впечатление о её качестве, которое дальше почти не меняется. Вся релевантная информация о качестве выступления передаётся в самом начале!
Результаты оказались удивительно стабильными: они воспроизводились для обеих языковых моделей (GPT и Gemini) и всех пяти вариантов промптов. Это говорит о том, что обнаруженный эффект — не артефакт конкретной модели или формулировки задания, а фундаментальное свойство того, как информация о качестве презентации кодируется в тексте.
Теоретические выводы: от неопределённости к впечатлению
Полученные результаты прекрасно согласуются с теорией снижения неопределённости (Uncertainty Reduction Theory) в коммуникативистике. В начале выступления аудитория испытывает максимальную неопределённость: о чём будет речь? Компетентен ли докладчик? Стоит ли слушать внимательно?
Первые минуты презентации стремительно снижают эту неопределённость. Слушатели используют ограниченную, но яркую информацию для быстрых суждений, которые затем направляют их дальнейшее восприятие. И как показывает исследование, эти суждения оказываются удивительно точными.
Интересная параллель обнаруживается с классическими исследованиями читательского поведения в журналистике. Ещё в 1947 году Шрамм показал, что большинство читателей газетных статей прекращают чтение на ранних этапах, как будто теряют внимание или находят текст слишком длинным и скучным. Современные форматы контента — от интернет-СМИ до TikTok — эволюционировали с учётом этой особенности человеческого внимания.
Практическое применение: ИИ-коуч для докладчиков
Но исследование ценно не только теоретическими выводами. Оно открывает путь к созданию автоматизированных инструментов для улучшения навыков публичных выступлений.
Сравните эффективность методов:
- Человеческая оценка: 60 оценщиков, $150, оценили только 24 презентации по одному фрагменту
- ИИ-оценка: 2 модели, 5 промптов, $5, час времени, оценены все 128 презентаций по 9 фрагментам
Разница в масштабируемости очевидна. Это не означает, что человеческая оценка больше не нужна — она остаётся золотым стандартом для валидации. Но после установления соответствия между человеческими и ИИ-оценками можно использовать последние для массового анализа.
Представьте систему, которая в реальном времени анализирует вашу презентацию и предупреждает: "Внимание! Первые две минуты звучат недостаточно убедительно. Попробуйте начать с более яркого примера или чёткой формулировки проблемы". Это может кардинально изменить подготовку к выступлениям.
Ограничения и будущие направления
Конечно, у исследования есть ограничения. Оно фокусировалось только на текстовых транскрипциях, игнорируя невербальные сигналы — жесты, интонацию, визуальный контакт. А ведь классические исследования thin-slicing показывают важность именно невербального поведения.
Кроме того, корпус состоял из довольно однородных научных презентаций людей из академии. Будут ли результаты воспроизводиться для других типов выступлений — бизнес-презентаций, политических речей, образовательных лекций? Это вопрос для будущих исследований.
Интересно также изучить культурные различия. Возможно, в разных культурах "правильное" начало презентации выглядит по-разному? И как языковые модели, обученные преимущественно на англоязычных текстах, справляются с оценкой презентаций на других языках?
Заключение: у вас не будет второго шанса
Исследование Schmaelzle et al. подтверждает народную мудрость: у вас никогда не будет второго шанса произвести первое впечатление. Но теперь мы знаем это не просто из анекдотов коучей по публичным выступлениям, а из строгого научного исследования с применением передовых технологий ИИ.
Так что в следующий раз, готовя презентацию, помните: ваши первые 60 слов могут определить, будут ли следующие 6000 слов вообще услышаны. Технологии искусственного интеллекта теперь позволяют не только измерить этот эффект с беспрецедентной точностью, но и помочь сделать эти первые слова максимально эффективными.
Статья в открытом доступе на arXiv