
Пока большие языковые модели (LLM) становятся привычной частью жизни разработчиков и энтузиастов, у владельцев Mac с процессорами Apple Silicon всегда оставался один болезненный вопрос: как уместить модели с большим контекстом в ограниченную оперативную память? Ответ недавно дал проект KVSplit, который обещает революционизировать использование нейросетей на MacBook и Mac Mini.
🚩 В чём суть проблемы?
Запуск больших моделей, таких как LLaMA, Gemini, Mistral, Qwen, требует огромного количества памяти. Основной пожиратель ресурсов здесь — KV cache, хранящий промежуточные состояния вычислений для механизма внимания. Чем длиннее контекст модели (количество токенов, которое модель способна обрабатывать одновременно), тем больше требуется памяти.
На типичном Mac с процессором M1 или M2 стандартная 16 ГБ RAM быстро заканчивается при попытке обработки больших контекстов. Здесь и вступает в игру KVSplit — проект, позволяющий существенно снизить потребление памяти.
🎯 Как это реализовано технически?
KVSplit применяет так называемую дифференцированную квантизацию (Differentiated KV Cache Quantization). Простыми словами — авторы KVSplit обнаружили, что в KV-кэше ключи (Keys) и значения (Values) не равнозначны по чувствительности к снижению точности хранения:
- 🔑 Ключи (Keys) гораздо сильнее влияют на качество модели. Их лучше хранить в более высокой точности.
- 📥 Значения (Values) менее чувствительны и могут храниться в существенно меньшей точности без значительной потери качества.
Таким образом, вместо стандартного хранения всего в FP16 (16-битные числа с плавающей точкой), авторы предложили использовать асимметричную модель хранения, например K8V4 (8-битные ключи, 4-битные значения). Это позволяет драматически снизить объём занимаемой памяти без значительного ущерба точности.
📉 Что даёт KVSplit на практике?
Результаты, полученные командой проекта, впечатляют:
- 🗄️ Экономия памяти до 72% (при максимальной компрессии K4V4)
- 🚀 Увеличение длины контекста в 2-3 раза на тех же ресурсах
- ⚡️ Ускорение вывода на 5-15% за счёт лучшего использования памяти и оптимизации Metal для Apple Silicon
Вот простая иллюстрация на примере модели с контекстом в 8 тысяч токенов:
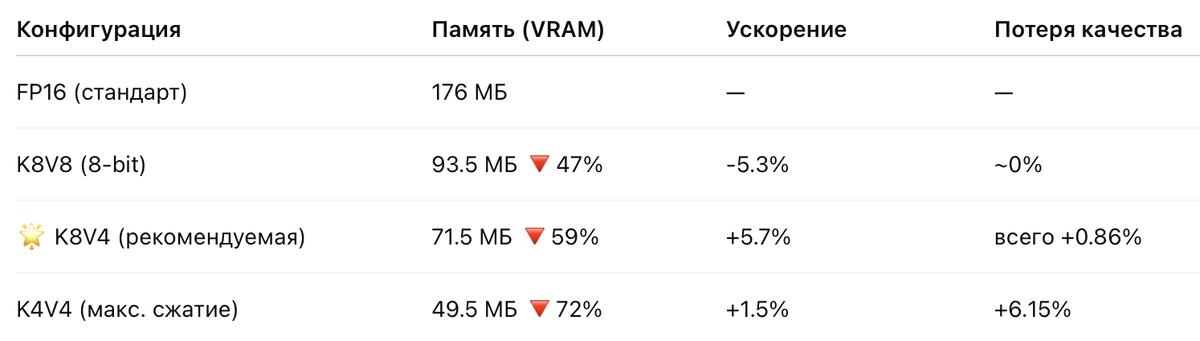
KVSplit особенно эффективен для работы с очень большими контекстами — например, для обработки текстов в десятки тысяч токенов (до 32K токенов). То, что раньше требовало гигабайты памяти, теперь помещается в несколько сотен мегабайт!
🛠️ Как использовать KVSplit?
Установить и попробовать KVSplit очень просто:
# 🖥️ Скачиваем репозиторий
git clone https://github.com/dipampaul17/KVSplit.git
cd KVSplit
# 🚧 Запускаем установочный скрипт
chmod +x scripts/install_kvsplit.sh
./scripts/install_kvsplit.sh
Далее запускаем быструю проверку с вашей моделью:
python scripts/quick_compare.py --model models/ваша-модель.gguf
Вы сразу увидите наглядные результаты по скорости и экономии памяти.
📚 Полезные советы по выбору конфигурации:
- 🌟 K8V4 — оптимальный баланс качества и экономии памяти (рекомендуется)
- 📦 K4V4 — максимальная экономия памяти при допустимом снижении качества (для менее чувствительных задач)
🧪 Технические детали и инсайты:
Технологически KVSplit опирается на доработанный вариант популярного движка llama.cpp, адаптированный специально под Apple Silicon и оптимизированный под графический API Metal.
Также разработчиками были представлены наглядные инструменты визуализации результатов, позволяющие детально исследовать влияние каждой конфигурации на производительность и качество модели.
📊 Например, вот как выглядит типовая команда запуска модели с оптимальной конфигурацией:
./llama.cpp/build/bin/llama-cli -m models/ваша-модель.gguf \
-c 32768 -n 4096 -t 8 --flash-attn --kvq 8 -f длинный-текст.txt
Это позволит обработать огромный текст (32 тысячи токенов) на MacBook Air без существенных ограничений памяти.
💡 Личное мнение автора статьи
KVSplit — это не просто «ещё один эксперимент». На мой взгляд, этот проект может стать настоящим спасением для тысяч разработчиков и исследователей, использующих Apple Silicon. Это тот случай, когда технологическое новшество напрямую улучшает реальную жизнь пользователей, позволяя запускать сложные модели без компромиссов в качестве и удобстве работы.
Более того, эта идея асимметричной квантизации, вероятно, распространится дальше, не только на Mac, но и на другие платформы и устройства, задав новый стандарт оптимизации работы нейросетей в будущем.
🔮 Будущее KVSplit
Разработчики KVSplit уже планируют интересные улучшения:
- 🔄 Адаптивная точность: модель сама будет менять точность квантизации в зависимости от важности токенов
- 📱 Поддержка мобильных устройств (iOS/iPadOS)
- 🌐 Web-демо для интерактивных тестов
Если вы давно ждали прорыва в запуске мощных моделей на Mac, KVSplit — это именно то, на что стоит обратить внимание прямо сейчас.
🔗 Источник и репозиторий KVSplit: KVSplit на GitHub
🔗 llama.cpp (основа реализации): llama.cpp
🔗 Исследования, вдохновившие KVSplit: