
Представьте себе ситуацию: вы попросили голосового помощника выполнить задачу, но сформулировали её не сразу, а постепенно, уточняя свои пожелания на протяжении разговора. В теории современные большие языковые модели (LLM) должны легко справляться с таким сценарием, но практика показывает, что именно в таких ситуациях они начинают «теряться».
Недавнее исследование, проведённое совместными усилиями учёных из Microsoft Research и Salesforce Research, показало, что крупные языковые модели демонстрируют серьёзные проблемы при ведении многоходовых диалогов, особенно когда пользователь уточняет или дополняет свои первоначальные запросы постепенно, а не даёт всю информацию сразу.
🔎 Суть проблемы
Исследователи провели масштабный эксперимент, сравнивая производительность языковых моделей в двух режимах:
- 🔹 Одноходовый диалог: когда вся информация о задаче полностью сформулирована сразу.
- 🔸 Многоходовый диалог: когда информация предоставляется постепенно, с каждым последующим запросом дополняя или уточняя предыдущий.
Выяснилось, что производительность языковых моделей в многоходовых диалогах снижается в среднем на 39% по сравнению с одноходовыми диалогами. Что же происходит?
🌀 Причины потери ориентации в диалогах
Авторы статьи выделяют несколько ключевых причин того, почему LLM начинают путаться:
- 🚩 Поспешные предположения: модели слишком рано пытаются дать финальный ответ, основываясь на неполной информации.
- 🛑 Переоценка своих прежних ответов: если модель один раз ошиблась, она слишком сильно опирается на свои предыдущие, неправильные выводы.
- 🗣️ Потеря информации по ходу диалога: модели плохо запоминают детали, озвученные в середине разговора, ориентируясь больше на первую и последнюю реплики.
- 📖 Избыточная многословность: LLM генерируют слишком длинные ответы, что увеличивает вероятность ошибочных предположений и отвлекает от ключевых деталей диалога.
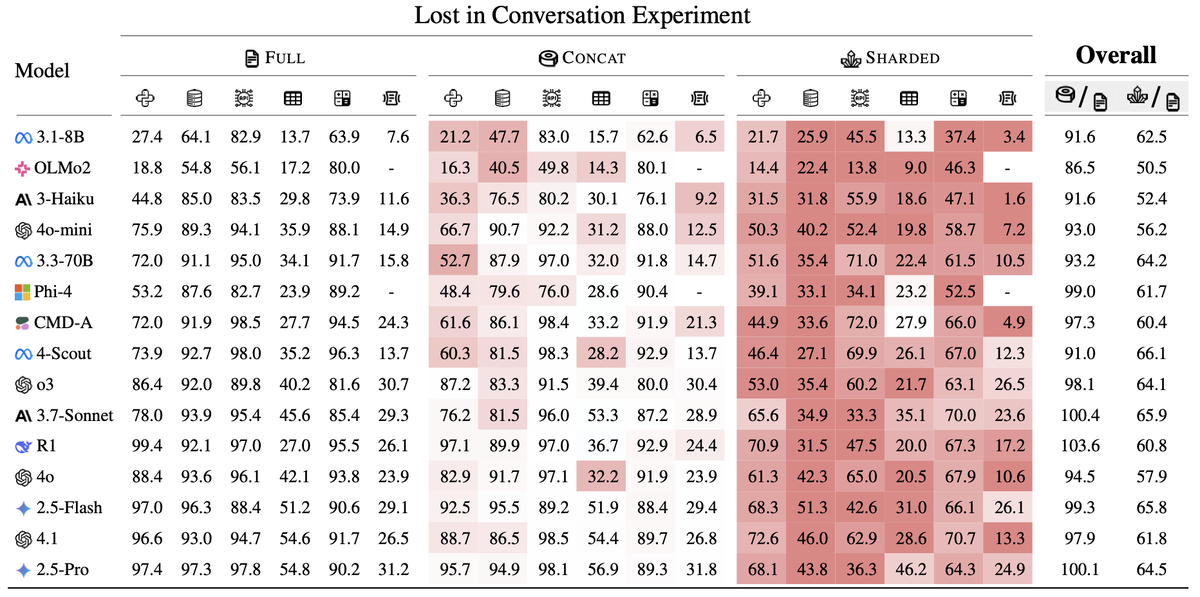
📊 Детали эксперимента
Эксперимент охватил более 200,000 симулированных диалогов, проверив 15 крупнейших моделей, среди которых были как небольшие (например, Llama3.1-8B), так и мощнейшие (например, Gemini 2.5 Pro и GPT-4.1). Результаты показали, что:
- ✅ При идеальных условиях (одноходовый диалог) лучшие модели показывают результат выше 90%.
- ❌ В многоходовых диалогах производительность падает в среднем до 65%.
🛠️ Что с этим делать? Советы и рекомендации
Авторы статьи предлагают несколько путей решения проблемы, среди которых:
- 🔄 Использовать при построении диалоговых систем принципы повторения и краткого пересказа («snowballing»), чтобы модель лучше удерживала в памяти уже озвученные детали.
- 🎚️ Варьировать «температуру» генерации текста, однако даже это решение даёт лишь ограниченный эффект.
- 📌 Разработчикам языковых моделей следует уделять повышенное внимание не только способности моделей выполнять сложные задачи (aptitude), но и стабильности их работы (reliability) в реальных условиях многоходовых диалогов.
🧠 Личное мнение автора статьи
Ситуация, описанная в исследовании, подчёркивает важность того, чтобы подходить к разработке и использованию LLM не только с позиции демонстрации теоретических возможностей, но и с точки зрения реальных сценариев взаимодействия с пользователями. Несмотря на впечатляющие достижения языковых моделей последних лет, проблема многоходового диалога остаётся ключевым ограничением их практического применения. Особенно остро это будет ощущаться в реальных приложениях, где люди склонны выражать свои пожелания не одним разом, а постепенно — например, в помощниках по программированию, решению сложных задач, планированию и других приложениях.
Возможно, будущее за теми моделями, которые не просто генерируют качественные ответы, а активно взаимодействуют с пользователем, уточняя и переспрашивая, пока не достигнут полной ясности в постановке задачи.