Представьте ситуацию: ваш близкий человек внезапно теряет сознание дома. Что вы сделаете первым делом? Конечно, вызовете скорую. Но что если поблизости никого нет, и вы решаете быстро спросить совет у… чат-бота? Сегодня это уже не выглядит странно. Однако сможете ли вы доверить своё здоровье искусственному интеллекту? И как понять, способен ли он действительно помочь?
Компания OpenAI решила ответить на эти вопросы радикально — создав новый эталон оценки медицинского искусственного интеллекта под названием HealthBench. В чём его уникальность, и почему этот проект может стать переломным моментом для всей отрасли?
🎯 Почему возникла необходимость в HealthBench?
Искусственный интеллект стремительно проникает в здравоохранение. Но существует серьёзная проблема: модели ИИ часто проверяются на упрощённых тестах, оторванных от реальной медицинской практики. В итоге пациентам предоставляется ненадёжная информация, которая может привести к серьёзным последствиям.
HealthBench создан именно для того, чтобы устранить этот пробел, и даёт возможность оценивать ИИ в условиях максимально приближенных к реальности:
- 🗣 Реалистичные диалоги: В HealthBench входит 5000 медицинских сценариев, каждый из которых — это реальный диалог пациента или врача с моделью ИИ.
- 🌍 Глобальный охват: 262 врача из 60 стран мира приняли участие в создании этих диалогов и критериев оценки, гарантируя учёт глобального разнообразия медицинских практик.
- 📊 Подробные критерии: Каждый ответ модели оценивается по специальной врачебной шкале, учитывающей точность, полноту, понимание контекста и качество коммуникации.
⚙️ Как работает HealthBench: заглянем под капот
HealthBench — это не просто набор вопросов и ответов. Он представляет собой комплексную систему оценки, включающую:
- 📖 48 562 уникальных критерия, разработанных врачами специально под каждый сценарий. Например, модель оценивают за чёткие указания вызвать скорую помощь при симптомах инсульта или за способность избегать излишне сложных медицинских терминов.
- 🤖 Автоматическая оценка: ИИ-система (например, GPT-4.1) проверяет ответы других моделей по заданным критериям. Это существенно ускоряет процесс проверки и позволяет быстро улучшать качество AI.
- 🔄 Диалоги на нескольких языках: Сценарии охватывают множество языков (английский, испанский, русский и другие), что повышает полезность HealthBench на глобальном уровне.
🛡 Три принципа, на которых базируется HealthBench:
OpenAI подчёркивает, что их подход строится на трёх важных принципах:
- 📌 Значимость: Оценки должны отражать реальное влияние на здоровье людей и работу врачей, а не просто правильность ответов на экзамене.
- 🔍 Доверие: HealthBench базируется исключительно на мнениях врачей и их клинической практике. Результаты отражают реальные медицинские стандарты.
- 🚀 Перспектива роста: Benchmarks («эталоны») должны оставлять место для совершенствования, стимулируя постоянное развитие AI-моделей.
📈 Что уже показали тесты?
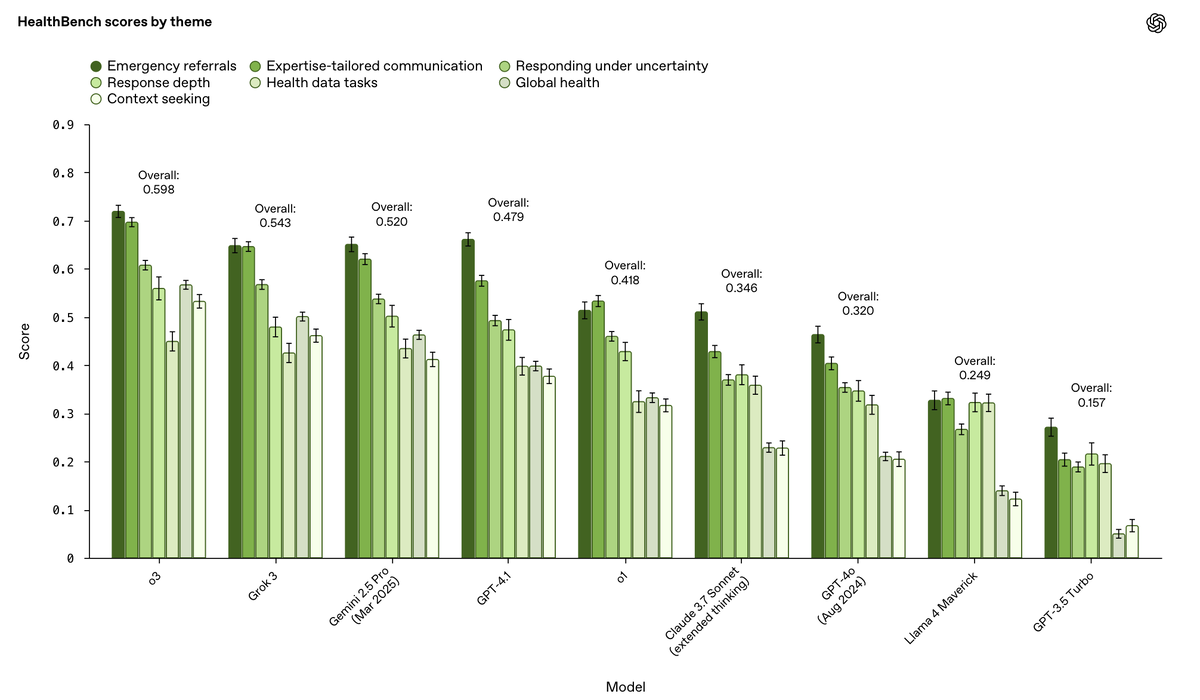
Уже сейчас OpenAI протестировала несколько своих моделей (например, GPT-4.1, GPT-4o, о3) на HealthBench и получила интересные результаты:
- 🥇 Модели нового поколения значительно опережают своих предшественников в точности и полноте ответов.
- 📉 Самые сложные сценарии (HealthBench Hard) по-прежнему остаются вызовом даже для лучших ИИ-систем, стимулируя дальнейшие исследования и улучшения.
🌐 Важность HealthBench для глобального здравоохранения
Важнейший аспект HealthBench — его потенциальная полезность в странах с ограниченными медицинскими ресурсами. Искусственный интеллект может стать спасательным кругом для регионов, где врачи недоступны, а медицинские услуги дороги и редки. Однако для этого необходимо, чтобы модели были безопасны, точны и доступны по цене. Именно в этих направлениях и движется разработка HealthBench.
🙋♂️ Личное мнение автора
С моей точки зрения, создание HealthBench — это не просто очередной шаг OpenAI, а действительно революция в подходе к оценке медицинских ИИ-систем. Внедрение такого стандарта поможет избежать ситуаций, когда пациенты получают неточную или даже опасную информацию от ИИ.
Тем не менее, остаются открытыми вопросы этики и ответственности. Кто несёт ответственность за ошибки ИИ в здравоохранении? Как обеспечить полное понимание пациентами того, что их консультирует машина, а не человек? Эти вопросы пока остаются за рамками HealthBench, однако уже сейчас ясно: без надёжной системы оценки никакие ИИ-технологии не смогут заслужить полного доверия пациентов и врачей.
🔗 Полезные ссылки и материалы:
HealthBench — это не просто инструмент оценки, это шаг к будущему, где искусственный интеллект станет надёжным союзником в борьбе за человеческое здоровье. Путь предстоит ещё долгий, но направление, без сомнения, верное.