...и как не попасть впросак, думая, что биты — это просто нолики и единички.
Когда вы пишете x << 1 в Python, всё вроде бы просто — будто приумножаете x на два и всё.
Но под капотом Python исполняет тонны магии, которой не было бы в C или Java.
Давайте разбираться, как Python работает с битами, почему -1 >> 1 не то же самое, что в C, и почему "двоичная арифметика" не всегда бинарная.
🧠 Что такое двоичная арифметика?
Это арифметика, где все числа представлены в бинарном (двоичном) виде — только 0 и 1. Все операции производятся на уровне битов.
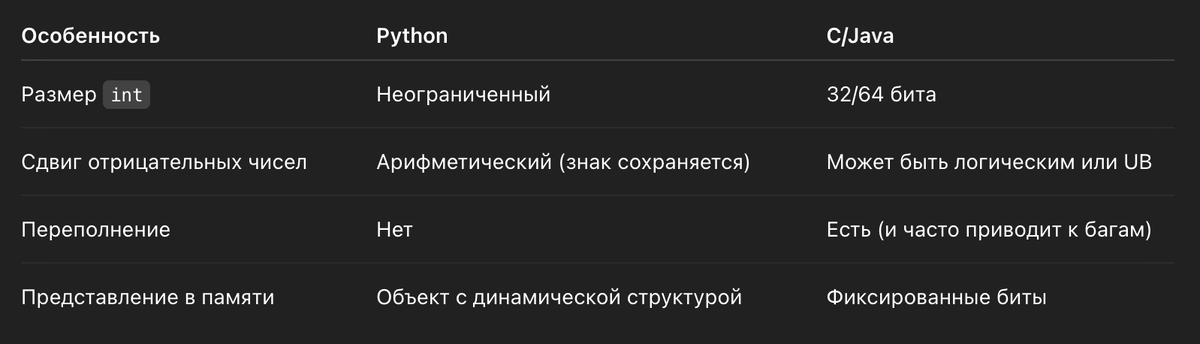
В низкоуровневых языках (например, C) тип int обычно фиксированного размера — например, 32 бита со знаком.
В Python такого ограничения нет: int может быть сколь угодно большим, потому что он — объект, а не просто набор битов.
🔁 Пример 1: Как работает << и >>
x = 5 # в двоичном: 0b0101
y = x << 1 # сдвиг влево на 1 бит
print(bin(y)) # 0b1010 (10 в десятичной системе)
Что произошло:
- 5 в битах: 0101
- << 1 — значит "умножь на 2": 1010 = 10
⚠️ В C int ограничен, и если бит «вылезет» — он отрежется. В Python он не отрежется никогда. Хотите 1000 битов? Пожалуйста.
🔄 Пример 2: Что делает >>
x = 20 # 0b10100
y = x >> 2 # сдвиг вправо на 2 бита
print(y) # 5
- 20 = 10100
- >> 2 удаляет 2 младших бита → 101 = 5
Внизкоуровневых языках >> бывает знаковым (arithmetical shift) или логическим (logical shift).
В Python — всегда арифметический сдвиг, и знак сохраняется для отрицательных чисел.
😈 Пример 3: Сдвиги и отрицательные числа
x = -8
print(bin(x)) # -0b1000 — но это не вся история!
print(bin(x >> 1)) # -0b100
Под капотом:
Python использует знаковое представление: дополнительный код (two's complement), бесконечно расширяя его до нужной длины.
То есть -8 на 32 битах в C = 0b11111111111111111111111111111000
В Python — это бесконечная последовательность единиц, заканчивающаяся 1000.
Сдвигая -8 >> 1, Python сохраняет знак и даёт -4, а не что-то странное вроде 2147483644, как может быть в C без правильной маскировки.
🧪 Пример 4: Проверка, чётное ли число (и почему тут важны биты)
n = 42
if n & 1 == 0:
print("Число чётное")
- n & 1 проверяет последний бит.
- Если он 0 → число чётное (все чётные заканчиваются на 0 в двоичном виде).
⚡ Это работает быстрее, чем n % 2 == 0 и хорошо показывает, как биты помогают с простыми арифметическими задачами.
🔍 Пример 5: Маскирование и ограничение до 32 бит
Иногда вам нужно получить значение как будто в 32-битной системе.
x = -1
x_32 = x & 0xFFFFFFFF
print(bin(x_32)) # 0b11111111111111111111111111111111
print(x_32) # 4294967295
- -1 в 32-битном представлении — это 32 единицы.
- Маскирование & 0xFFFFFFFF имитирует unsigned int из C.
🔐 Этот приём полезен при работе с бинарными протоколами, криптографией и сериализацией.
💡 Что Python делает не так, как C или Java
🛠 Практика: Задача — подсчитать количество установленных битов (битов, равных 1)
def count_ones(n):
count = 0
while n:
count += n & 1 # если последний бит равен 1, увеличиваем счётчик
n >>= 1 # сдвигаем вправо
return count
print(count_ones(42)) # 3 (101010)
🧪 Это один из классических вопросов на собеседованиях. Можно сделать ещё быстрее с n &= n - 1 (алгоритм Брайана Кернигана), но это уже для профи.
📌 Вывод
Python делает работу с битами удобной и безопасной, но под капотом всё так же сложно, как в C или Assembler. Он:
- защищает от переполнения,
- сохраняет знак при сдвигах,
- позволяет оперировать бесконечно большими числами.
Но! Если вы пишете высокопроизводительный код или работаете с бинарными данными — знание этих низкоуровневых нюансов критично.
🧪 1. Как в Python эмулировать unsigned int
В C у вас есть uint32_t, uint64_t, и т. д. — то есть числа без знака, которые могут переполняться.
В Python все числа со знаком, но можно эмулировать поведение unsigned int при помощи битовой маски.
Пример: имитация uint32_t
def to_uint32(n):
return n & 0xFFFFFFFF
Пример использования:
x = -1
print(to_uint32(x)) # 4294967295
print(bin(to_uint32(x))) # 0b11111111111111111111111111111111
🔍 Это работает, потому что 0xFFFFFFFF — это 32 единицы, и & просто "отрезает" всё лишнее.
📦 2. Мини-библиотека для сериализации бинарных структур
Допустим, у нас есть структура:
- user_id: 32-битный unsigned int
- age: 8-битный unsigned int
- is_active: 1 бит
Используем struct для упаковки:
import struct
def pack_user(user_id, age, is_active):
flags = 0
if is_active:
flags |= 1 # младший бит
return struct.pack("<IB", user_id, age) + bytes([flags])
- <I — 4 байта (uint32)
- B — 1 байт (uint8)
- flags — 1 байт (мы пока используем 1 бит)
Распаковка:
def unpack_user(data):
user_id, age = struct.unpack("<IB", data[:5])
flags = data[5]
is_active = bool(flags & 1)
return {"user_id": user_id, "age": age, "is_active": is_active}
Пример:
data = pack_user(12345, 28, True)
print(data) # Бинарная строка
info = unpack_user(data)
print(info) # {'user_id': 12345, 'age': 28, 'is_active': True}
📦 Эту технику можно расширить под полноценный бинарный протокол — хоть свой сериализатор пиши.
☠️ 3. Почему -128 >> 1 в C — это боль, особенно если не знаешь, знаковый ли сдвиг
В C выражение -128 >> 1 — зависит от реализации.
Почему?
В C (int x = -128;) битовое представление зависит от архитектуры:
- Большинство систем используют дополнительный код (two’s complement): -128 → 10000000 (на 8 битах)
- Сдвиг >> может быть:
Арифметическим: знак сохраняется (старшие биты заполняются единицами)
Логическим: в старшие биты приходит 0
То есть:
int x = -128;
int y = x >> 1;
На одних системах y == -64, на других — y == 64 или вообще UB (undefined behavior).
В Python всё безопасно:
x = -128
print(x >> 1) # -64
✅ Всегда арифметический сдвиг. Python не даст вам сделать логический сдвиг — и это хорошо.
📌 Вывод по бонусам:
- 🧊 Unsigned int легко эмулируется маской & 0xFFFFFFFF
- 📦 Сериализация двоичных структур делается через struct и побитовые флаги
- ☢️ Сдвиг в C может быть опасным, если вы не знаете, знаковый он или нет