
На фоне бурного роста размеров больших языковых моделей (LLM), таких как Llama, Qwen и Gemma, на первый план выходит задача эффективного размещения их на оборудовании, особенно в условиях ограниченных ресурсов. И хотя подходы к квантованию давно используются, они сопровождаются потерей точности и ухудшением качества. Недавнее исследование специалистов из Rice University и компании xMAD.ai предлагает инновационное решение, позволяющее сократить размер модели без потери даже одного бита точности.
🔍 В чём суть нового подхода?
Разработчики предлагают новый формат хранения данных — Dynamic-Length Float (DFloat11). Он основывается на интересном наблюдении: стандартный формат BFloat16, который используется в большинстве современных LLM, не оптимален с точки зрения информационной плотности. В частности, из 8 бит экспоненты обычно используются всего 2–3 бита реальной информации, остальные биты практически бесполезны.
Исследователи применили энтропийное кодирование (например, кодирование Хаффмана), назначая более короткие коды чаще встречающимся значениям и добиваясь таким образом эффективного сжатия без потерь.
🚀 Как удалось ускорить GPU-инференс?
Одной из главных трудностей подхода на основе динамической длины кодирования является производительность при распаковке данных на GPU. GPU рассчитаны на параллельную обработку данных с фиксированной длиной и плохо подходят для последовательного декодирования кодов Хаффмана.
Решение было найдено за счет нескольких ключевых инноваций:
- 🧩 Компактные таблицы поиска (LUT): Вместо одной большой таблицы была предложена декомпозиция на несколько маленьких LUT, которые помещаются в быструю SRAM-память графических процессоров.
- 🧵 Двухфазный GPU-кернел: Вместо одновременной записи и чтения была реализована двухфазная схема, при которой потоки сначала считают необходимые позиции для декодированных данных, а затем уже пишут данные, снижая задержки и увеличивая параллелизм.
- 🗃 Декомпрессия на уровне блоков трансформера: Вместо того чтобы декомпрессировать каждую небольшую матрицу по отдельности, ученые предложили объединять операции по декомпрессии сразу для всего блока трансформера, значительно увеличивая эффективность использования GPU.
📊 Эффективность на практике
Исследователи протестировали свой метод на нескольких популярных моделях и добились впечатляющих результатов:
- 🎯 100% точность: DFloat11-сжатие абсолютно не влияет на точность модели, что подтверждено результатами на стандартных бенчмарках (MMLU, TruthfulQA и др.).
- 📉 Сжатие на 30%: Размер моделей сократился примерно до 70% от оригинала, что позволяет использовать гораздо меньшие объёмы памяти.
- ⚡️ Рост производительности: При одинаковых аппаратных ресурсах модели с DFloat11 показали увеличение пропускной способности до 38 раз по сравнению с подходом, при котором несжатые модели частично выгружались на CPU.
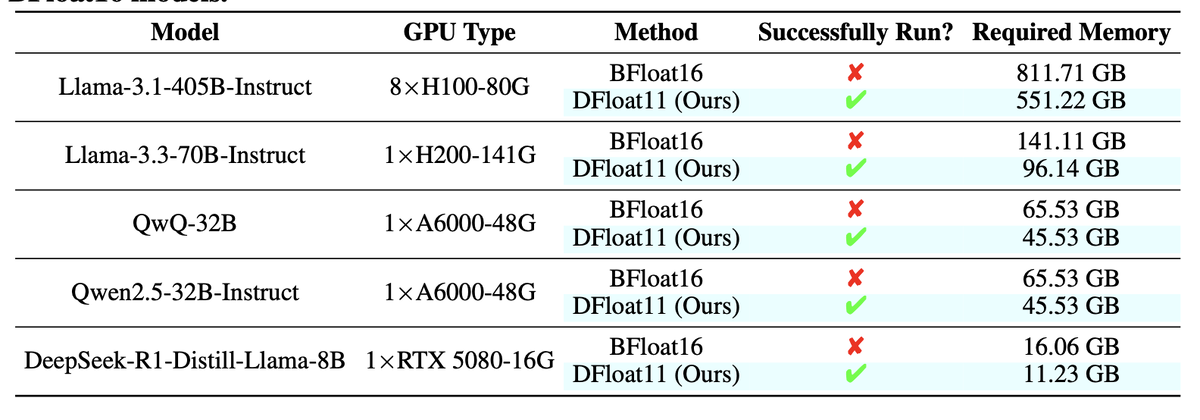
Также методика позволила запускать такие тяжёлые модели, как Llama-3.1-405B (810 Гб в оригинале), на одном сервере с 8 GPU по 80 Гб, ранее это было невозможно без применения кластера.
📌 Личное мнение и взгляд в будущее
Авторы подхода подчеркнули важность разработки именно lossless-методов компрессии: хотя квантование в INT8 или FP8 стало уже стандартом и снижает размер моделей сильнее (до 50% и более), оно всегда вносит неопределённость и риски для качества моделей. Поэтому применение подходов, подобных DFloat11, будет особенно востребовано там, где критична точность и воспроизводимость результатов — например, в медицине, финансах или науке.
Мне же лично особенно нравится практическая элегантность подхода: авторы не только решили сложную проблему, но и показали грамотную инженерную реализацию на GPU. Это пример того, как теоретические идеи и глубокое понимание аппаратной архитектуры рождают по-настоящему эффективные инструменты.
Очевидно, что такой подход будет востребован не только для существующих моделей, но и для новых поколений нейросетей, которые, судя по всему, продолжат активно расти в размерах.
🔗 Ссылки на материалы и ресурсы: