Начало - сценарий "Select-only" Чтобы снизить количество ожиданий BufferContent в PostgreSQL, можно предпринять несколько шагов: 2. **Увеличение shared_buffers**: Увеличение параметра shared_buffers может помочь уменьшить количество ожиданий BufferContent, так как это увеличит объем памяти, доступный для кэширования данных. Однако, важно не перегружать систему памятью, поэтому увеличивайте этот параметр постепенно и мониторьте производительность. Цитата из ответов ChatPPG. Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu cat /proc/cpuinfo processor : 0 model name : Intel Xeon Processor (Skylake, IBRS, no TSX) cpu MHz : 2693.670 processor : 1 model name : Intel Xeon Processor (Skylake, IBRS, no TSX) cpu MHz : 2693.670 current_delta = (ROUND( random ())::integer)*10 + 1 ; SELECT MIN(aid) INTO min_i FROM pgbench_accounts ; SELECT MAX(aid) INTO max_i FROM pgbench_accounts ; current_aid = max_i / 2; UPDATE pgbench_accounts SET abalance

Задача эксперимента
1. Продолжение тестирования PG_HAZEL на стандартных сценариях нагрузочного тестирования.
Начало - сценарий "Select-only"
2.Проверка рекомендаций ChatPPG
Чтобы снизить количество ожиданий BufferContent в PostgreSQL, можно предпринять несколько шагов:
2. **Увеличение shared_buffers**: Увеличение параметра shared_buffers может помочь уменьшить количество ожиданий BufferContent, так как это увеличит объем памяти, доступный для кэширования данных. Однако, важно не перегружать систему памятью, поэтому увеличивайте этот параметр постепенно и мониторьте производительность.
Цитата из ответов ChatPPG.
Версия СУБД
Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu
Виртуальная машина
cat /proc/cpuinfo
processor : 0
model name : Intel Xeon Processor (Skylake, IBRS, no TSX)
cpu MHz : 2693.670
processor : 1
model name : Intel Xeon Processor (Skylake, IBRS, no TSX)
cpu MHz : 2693.670
Тестовый запрос
current_delta = (ROUND( random ())::integer)*10 + 1 ;
SELECT MIN(aid) INTO min_i FROM pgbench_accounts ;
SELECT MAX(aid) INTO max_i FROM pgbench_accounts ;
current_aid = max_i / 2;
UPDATE pgbench_accounts SET abalance = abalance + current_delta WHERE aid = current_aid ;
SELECT abalance INTO test_rec FROM pgbench_accounts WHERE aid = current_aid ;
SELECT MIN(tid) INTO min_i FROM pgbench_tellers ;
SELECT MAX(tid) INTO max_i FROM pgbench_tellers ;
current_tid = max_i / 2;
UPDATE pgbench_tellers SET tbalance = tbalance + current_delta WHERE tid = current_tid ;
SELECT MIN(bid) INTO min_i FROM pgbench_branches ;
SELECT MAX(bid) INTO max_i FROM pgbench_branches ;
current_bid = max_i / 2;
UPDATE pgbench_branches SET bbalance = bbalance + current_delta WHERE bid = current_bid ;
Сравнительные эксперименты
Эксперимент-1 : shared_buffer = 428MB
Эксперимент-2 : shared_buffer = 642MB
Операционная скорость и медианное время тестового SQL запроса
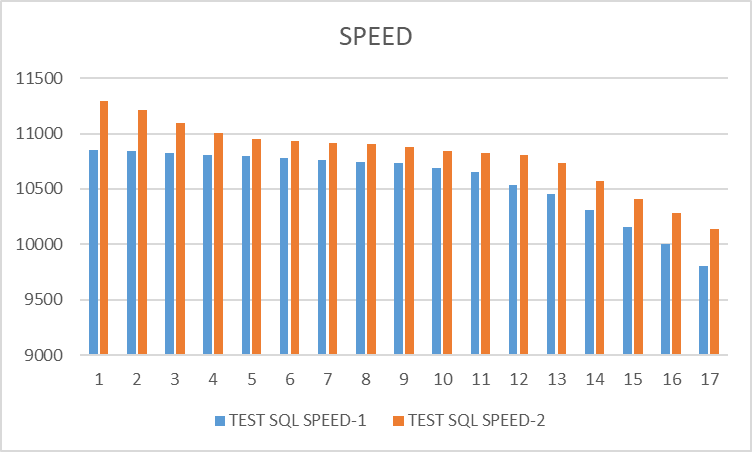
Результат
Скорость выполнения тестового запроса в Эксперименте 2 -уменьшилась от 1 до 4%.
Время выполнения тестового запроса в Эксперименте 2 - уменьшилась от 2 до 5%.
Инциденты производительности в ходе нагрузочного тестирования
Результаты
- Количество инцидентов снижения производительности СУБД - не изменилось.
- Снижение скорости - снизилось: 38% / 30%.
Количество SQL запросов по событиям ожидания (wait_event)
Результаты
- Количество SQL запросов, имеющих ожидания увеличилось - 46 / 73.
- Количество SQL запросов, имеющих ожидания BufferContent не изменилось - 4 / 4.
Статистические показатели по SQL запросам по событию ожидания LWLock
- Эксперимент 1 - Отношение ожидания / количество запросов : 0,0707105255331172
- Эксперимент 2 - Отношение ожидания / количество запросов : 0,0551550664365399
Результаты
- Отношение ожидания к количеству запросов уменьшилось ~22%.
Ожидания по тестовому SQL запросу
Табличные значения
Графики истории статистики выполнения и ожиданий
События ожидания
Результаты
- Количество событий ожиданий BufferContent существенно не изменилось
- Возникли события ожидания XidGen
Событие ожидания XidGen
- XidGen Ожидание при выделении нового идентификатора транзакции.
Рекомендация ChatPPG по снижению количества ожиданий XidGen
Ожидание XidGen в PostgreSQL возникает, когда процессу требуется уникальный идентификатор транзакции (XID), но он не может получить его немедленно из-за конкуренции с другими процессами. Это может произойти в следующих случаях:
1. Конкуренция за XID: Когда множество транзакций одновременно запрашивают новые XID, они могут столкнуться с блокировкой на уровне XidGenLock. Это LW-блокировка (Lightweight Lock) используется для синхронизации доступа к генератору XID.
2. Высокая нагрузка: При высокой нагрузке на базу данных, когда множество транзакций одновременно выполняются и требуют новые XID, может возникнуть ожидание XidGen.
3. Завершение транзакций: Когда транзакции завершаются, они освобождают свои XID, и другие транзакции могут их использовать. Однако, если процесс не может быстро получить новый XID, он может попасть в состояние ожидания XidGen.
Для минимизации ожидания XidGen можно рассмотреть следующие меры:
- Оптимизация транзакций: Уменьшите длительность транзакций и убедитесь, что они завершаются вовремя.
- Настройка autovacuum: Увеличьте количество автовакуумных процессов с помощью параметра autovacuum_max_workers, чтобы управлять транзакциями более эффективно.
- Настройка checkpoint_completion_target: Этот параметр управляет тем, как много времени должно быть потрачено на завершение точки контрольного снимка перед передачей управления другим процессам. Оптимизация этого параметра может помочь снизить конкуренцию за ресурсы.
Выводы по результатам сравнительных экспериментов
В данной конфигурации , при заданном характере нагрузки :
- Увеличение значения параметра shared_buffer на 50% привело к увеличению операционной скорости от 1 до 4% и уменьшению медианного времени выполнения тестового запроса от 2 до 5%.
- Увеличение события ожидания XidGen связано с увеличением операционной скорости СУБД и возникшей конкуренцией за XID.