Доброго здоровья читателям моего канала programmer's notes. Подписываемся и ставим лайки.
Оконные функции в команду select
Хороший инструмент появился некоторое время назад в PostgreSQL. С некоторой натяжкой это можно назвать разновидностью группировки. В некоторых случаях это более удобный её вариант.
1. При использовании оконных функций всегда используется оператор over.
2. С оператором over используются не только специальные функции, но и агрегирующие функции.
3. Оператор over используется только в разделе over.
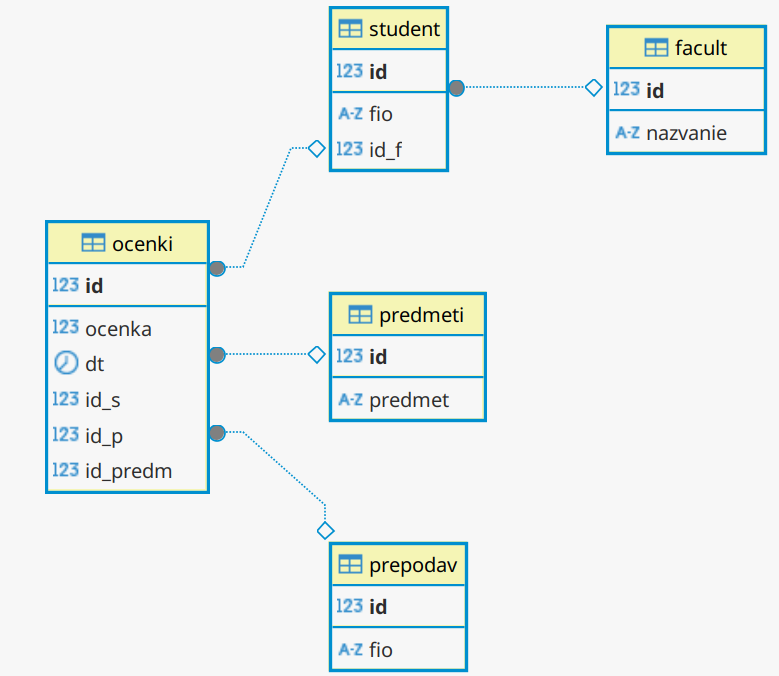
Схему данных используем прежнюю (см. Рисунок 1).
О функции row_number()
Рассмотрим самый простой пример. Функция row_number() и over без параметров.
select fio "ФИО", row_number() over() "Номер"
from student
order by "Номер";
Результат выполнения программы см. на рисунке 2.
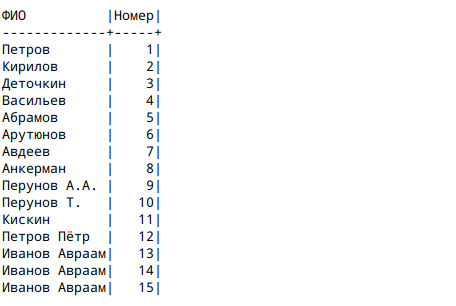
Как видим, мы получили список значений из таблицы с нумерацией строк.
Несколько видоизменим предыдущий запрос. Добавим оператор order by в скобки после over.
select fio "ФИО", row_number() over(order by fio) "Номер"
from student
order by "Номер";
В результате получим "два в одном": сортировку и по номеру и по fio (см. Рисунок 3). Т.е. два order by просто дополнили друг друга.
Продолжим наши эксперименты. Будем теперь использовать оператор partition by. Этот оператор напоминает group by. Но только разбиение на группы не мешает выводу всех строк предусмотренных запросом.
select fio "ФИО", row_number() over(partition by fio) "Номер"
from student
order by fio;
Результат выполнения см. Рисунок 4.
Функция row_number() теперь работает в каждой группе. Все группы состоят только из одной строки, кроме группы образованной однофамильцами. Соответственно внутри этой группы мы имеем нумерацию от 1 до 3.
Переходим к агрегирующим функциям
Возьмём агрегирующую функцию count()
select fio "ФИО", count(*) over() "Номер"
from student
order by fio;
Результат выполнения см. на рисунке 5
Мы видим, что использование over() привело к тому, что группой для count() является всё множество полученных строк. Т.е. в каждой строке мы получили количество всех строк.
Видоизменим запрос
select fio "ФИО", count(*) over(order by fio) "Номер"
from student
order by fio;
Т..е. теперь мы добавили в скобки после over оператор order by. Результат мы видим на рисунке 6.
Результат означает следующее. Счетчик вычисляется для каждой строки начиная с первой и по эту строку. Т.е. группа (окно) для каждой строки n начинается с 1 и заканчивается n. Запомним что даёт order by для агрегирующий функций (!!!).
Ну и наконец partition by.
select fio "ФИО", count(*) over(partition by fio) "Номер"
from student
order by fio;
Результат выполнения см. на рисунке 7
Комментировать не буду, результат должен быть понятен.
Примеры запросов с over
Перейдём теперь к примерам использования оконных функций в более сложных примерах. Схема данных всё та же, см. Рисунок 1.
select f.nazvanie "Факультет", s.fio "ФИО",
row_number() over (partition by f.nazvanie order by s.fio) "Номер"
from student s inner join facult f on f.id=s.id_f;
В результате выполнения запроса мы получаем список студентов по факультетам с отдельной нумерацией в пределах каждого факультета (см. Рисунок 8).
Если нам нужна ещё и сквозная нумерация, то нет ничего проще.
select f.nazvanie "Факультет", s.fio "ФИО",
row_number() over (partition by f.nazvanie order by s.fio) "Номер",
row_number() over () "Номер сквозной"
from student s inner join facult f on f.id=s.id_f;
Мы просто добавили ещё одно полу с функцией row_number() и пустыми скобками после over (см. Рисунок 9).
Ну теперь задача по-сложнее. Необходимо получить список студентов с указанием факультета, а также средняя оценка по факультету и средняя конкретного студента. В начале решим её традиционным способом без использования оператора over.
select distinct f.nazvanie "Факультет", s.fio "ФИО", s.id,
(
select avg(oo.ocenka)
from student ss inner join ocenki oo on ss.id=oo.id_s
inner join facult ff on ff.id=ss.id_f
where f.id=ff.id
group by ff.nazvanie
) as "По факультету",
(
select avg(oo.ocenka)
from student ss inner join ocenki oo on ss.id=oo.id_s
where ss.id=s.id
group by ss.id
) as "Студент"
from student s inner join ocenki o
on s.id=o.id_s
inner join facult f on f.id=s.id_f
order by s.fio;
Согласитесь выражение громоздкое. Нам для вычисления для каждой строки средней оценки студента и средней оценки по факультету пришлось использовать два подзапроса (выражения в скобках). Студенты, не имеющие оценок в результат не попали (см. Рисунок 10).
А вот, что будет, если мы будем использовать агрегирующие функции вместе с оператором over. Результат тот же, а запрос в два раза короче. avg() вместе с partition by делает чудеса.
select distinct f.nazvanie "Факультет", s.fio "ФИО", s.id,
avg(o.ocenka) over (partition by f.id) "По факультету",
avg(o.ocenka) over (partition by s.id) "Студент"
from student s inner join ocenki o
on s.id=o.id_s
inner join facult f on f.id=s.id_f
order by s.fio;
Справочник оконных функций PostgreSQL
Приведём справочник оконных функций. Но прежде укажем вот на что. В технологии оконных функций встречается понятие и раздела и окна. Это несколько разные понятия. Раздел (partition) — это группа строк, которые имеют одинаковые значения согласно partition by. Если partition by не указан то раздел совпадает со всем набором строк. Оконная функция вычисляется по строкам, попадающим в один раздел с текущей строкой.
Окно (frame) — это набор строк в разделе отдельно для каждой строки. Некоторые оконные функции и агрегирующие функции обрабатывают только строки рамки окна, а не всего раздела. По умолчанию с указанием order by рамка состоит из всех строк от начала раздела до текущей строки и строк, равных текущей строке по значению выражения order by. Без order by рамка по умолчанию состоит из всех строк раздела.
- row_number() — присваивает уникальные последовательные целые числа строкам в каждом наборе данных, определяемых с помощью partition by;
- rank() — аналогична row_number(), для строк с одинаковыми значениями устанавливается одинаковый ранг, а следующий ранг пропускается;
- dense_rank() — то же, что rank(), но без пропусков;
- percent_rank() — вычисление относительного ранга значения в каждом наборе данных;
- cume_dist () — совокупное распределение значений в каждом наборе: (число строк раздела, меньших или равных текущей строке) / (общее число строк раздела) ;
- ntile(num_buckets integer) — позволяет распределить строки из каждого набора результатов на указанное количество примерно равных групп;
- lag (value anycompatible [, offset integer [, default anycompatible]] ) — позволяет получить доступ к данным предыдущей строки внутри одного и того же набора результатов. Возвращает значение value, вычисленное для строки, сдвинутой на offset строк от текущей к началу раздела; если такой строки нет, возвращается значение default (оно должно быть совместимого с value типа). Оба аргумента, offset и default, вычисляются для текущей строки. Если они не указываются, offset считается равным 1, а default — NULL;
- lead (value anycompatible [, offset integer [, default anycompatible]]) — позволяет получить значение из последующей строки в наборе результатов. Возвращает значение value, вычисленное для строки, сдвинутой на offset строк от текущей к концу набора; если такой строки нет, возвращается значение default (оно должно быть совместимого с value типа). Оба аргумента, offset и default, вычисляются для текущей строки. Если они не указываются, offset считается равным 1, а default — NULL;
- first_value (value anyelement) — возвращает значение (value), вычисленное для первой строки в рамке окна;
- last_value (value anyelement) — возвращает значение (value), вычисленное для последней строки в рамке окна;
- nth_value (value anyelement, n integer) — возвращает значение (value), вычисленное в n-ой строке в рамке окна (считая с 1), или NULL, если такой строки нет.
Пока всё!
Хорошего программирования. Оставляйте свои комментарии, не забывайте про лайки и подписывайтесь на мой канал programmer's notes.