В одной из предыдущих публикаций мы рассматривали, как рост человека - независимая переменная, предиктор, влияет на его массу (зависимая переменная, или переменная отклика). Иными словами, мы пытались предсказать поведение переменной отклика, веса, по его предиктору. И предиктор у нас был всего один - рост!
На практике же чаще всего требуется изучить влияние не одного, а сразу нескольких (2 и более) предикторов на переменную отклика. В данной ситуации следует использовать множественный линейный регрессионный анализ (multiple linear regression). Это - более сложная разновидность линейного регрессионного анализа. Она позволяет:
- предсказывать значение зависимых переменных отклика по известным значениям нескольких переменных-предикторов;
- оценивать степень независимого друг от друга влияния каждого из предикторов на значение переменной отклика.
То же в виде формулы. Пусть y - зависимая переменная, изменение которой мы хотим посмотреть в ответ на различные значения других переменных (x1, x2, ..., xj).
Модель множественной линейной регрессии предполагает, что с увеличением/уменьшением значений независимых переменных значение зависимой переменной отклика увеличивается/уменьшается линейно.
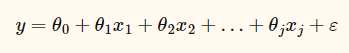
Коэффициенты регрессии, "теты": θ1, θ2, θj - важнейшие показатели, которые подлежат вычислению (методом наименьших квадратов). Они показывают изменение зависимой переменной при условии «неподвижности» остальных коэффициентов. "Теты" - величины размерные (каждая в своей шкале). Величина какой-то θi показывает, насколько в среднем изменяется значение зависимой переменной отклика y при увеличении соответствующего независимого признака xi на единицу (шкалы его измерения). Соответственно, чем больше θi, тем в большей степени признак xi влияет на результирующий признак y.
Рассматриваемое уравнение содержит коэффициенты регрессии в их "натуральном" виде, то есть, в абсолютных единицах измерения признаков. Однако оценка влияния переменных, включенных в модель множественной регрессии, может быть значительно затруднена, если эти переменные - разные по своей сущности и имеют различные единицы измерения. Поэтому существует стандартизированная модель регрессии, в которой все значения исследуемых признаков х переведены в стандарты tx по формуле (включает в себя (σх – стандартное отклонение):
Тогда коэффициент регрессии θi будет выражен не в своей "натуральной" единице измерения, а в долях среднего квадратического отклонения переменной отклика у. Это - так называемый бета-коэффициент βi.
Таким образом, стандартизированное уравнение регрессии будет иметь вид:
!Важно! переменные должны быть количественными - непрерывные (измеряемые в интервальной шкале) или относительные (измеряемые в шкалах отношений).
В результате проведения эпидемиологических и клинических исследований копятся много переменных, и некоторые из них представляют интерес как переменные отклики.
Примеры: модель оценки костной плотности у женщин в менопаузе, в которую показатель костной плотности (кг/м3) входит как переменная отклик, а возраст и индекс массы тела - как переменные предикторы. Модель оценки тяжести заболевания COVID-19: предикторы - возраст, показатели наличия диабета, ССЗ, гипертонии, ожирения.
Пример для множественного линейного регрессионного анализа в программе Statisticа
Необходимо провести множественную линейную регрессию зависимости систолического артериального давления (САД) (мм рт.ст.) от следующих показателей:
- возраст
Артериальное давление являет собой один из ключевых показателей состояния сердечно-сосудистой системы, играющей важную роль в поддержании нормальной жизнедеятельности организма. Нормы артериального давления значительно варьируются в зависимости от возраста человека. У пожилых людей есть несколько характерных особенностей, которые влияют на их АД. Прежде всего это увеличение сосудистой жесткости, уменьшение эластичности аорты и других сосудов, изменения в сердечной функции (уменьшение сократительной способности сердца и меньшая чувствительность к нервным сигналам, регулирующим сердечный ритм), ухудшение функции почек. В результате этих изменений, нормальное АД для пожилых людей может быть немного выше, чем для молодых.
- показатель гемоглобина (г/л).
Уровень гемоглобина может влиять на показатели артериального давления: чем выше уровень белка, тем выше давление и наоборот. Гипертония наступает, когда вязкость крови увеличивается.
Для начала внесём данные, полученные в ходе исследования, в таблицу:
Воспользуемся модулем Multiple Regression Analysis (Анализ множественной регрессии). Запустим его из меню: Statistics / Multiple Regression Analysis
Перед нами появилось диалоговое окно Multiple Regression Analysis. По умолчанию оно открыто на закладке Quick (Быстро) с единственной кнопкой Variables. Нажмём на эту кнопку, и укажем зависимую (Dependent variable) и независимую (Independent variable) переменные. В нашем случае «САД» - зависимая переменная, которая должна (или не должна) зависеть от «Возраста» и «Гемоглобина» (независимые переменные):
Нажмём OK. Во вновь появившемся окне Multiple Regression Analysis мы убеждаемся, что переменные указаны верно:
В результате работы программы появляется новая панель с расчетными характеристиками.
На этой панели с заглавием Multiple Regression Analysis отображаются следующие показатели:
- Dependent (Зависимая переменная отклик). Это у нас САД (систолическое артериальное давление);
- № of cases (Количество переменных). Их у нас 16;
- Multiple R (Множественный коэффициент корреляции). Он определяет степень тесноты связи результирующего признака y со всем набором независимых признаков x1, x2, ..., xj.
В случае парной регрессии, т. е. при наличии всего одного признака x, значение Multiple R совпадает с коэффициентом корреляции Пирсона.
Если же переменных предикторов два и более, то множественный коэффициент корреляции вычисляется по формуле (для предикторов x1 и x2):
В нашем случае Multiple R = 0,99, из чего можно заключить, что теснота связи САД с Возрастом и Гемоглобином почти абсолютная.
- R? или R2 (Коэффициент детерминации). Он отражает «качество» рассчитанной регрессии. В нашем случае R2 = 0.98. В этом случае говорят, что изменения зависимой переменной, САД, на 98% объясняются изменением независимых факторов/переменных, Возраста и Гемоглобина. Можно сказать, что построенная регрессионная модель отлично описывает связь между возрастом и уровнем гемоглобина и артериальным давлением.
- adjusted R? или adjusted R2 («Скорректированный» коэффициент детерминации). Скорректированное значение предыдущего показателя:
В нашем случае adjusted R? = 0,98.
Стоит отметить, что программа Statisticа не всегда адекватно отображает квадрат, и часто проставляет вместо него знак ?.
- F (величина F-критерия, или критерия Фишера). Значимость множественной корреляции мы определяем по критерию Фишера:
В нашем примере: F = 355,93;
- df (Число степеней свободы) для уравнения множественной линейной регрессии. У нас df = 2,13;
- р (уровень значимости). В нашем случае р значительно меньше 0,05, то есть, гипотеза об отсутствии линейной связи уверенно отклоняется;
- Standard error of estimate (Стандартная ошибка оценки). Это одна из наиболее важных характеристик точности полученного уравнения, показывающая рассеяние наблюдаемых значений относительно линии регрессии. Стандартная ошибка оценки регрессионной модели у нас равна 2,64.
- Intercept (Оценка свободного члена). Это - собственно свободный член θ0 из уравнения множественной линейной регрессии:
У нас он равен 68,44.
Свободный член показывает сдвиг прямой относительно точки начала координат вверх или вниз:
- Std. Error (Стандартная ошибка). Стандартная ошибка оценки свободного члена; в нашем примере этот показатель составляет 3,15;
- t с указанным в скобках числом степеней свободы - наблюдаемое для свободного члена значение t-критерия. В нашем примере t ( , 13) = 21,72;
- р (уровень значимости) - соответствующий уровень значимости для t-критерия. В нашем примере значение вероятности значительно меньше 0,05, что позволяет говорить о значимости свободного члена регрессии.
- Под информационной частью окна отображаются коэффициенты регрессии, фигурирующие в стандартизированной форме уравнения регрессии, — бета-коэффициенты. Значимые оценки высвечиваются красным цветом. Из переменных, включенных в анализ в нашем примере, значимым оказался Возраст (beta = 0,95), а незначимым - Гемоглобин (beta = 0,048).
Уровень значимости обозначен строкой Alpha for highlightning effects; по умолчанию он принимается за 0,05. Его можно поменять, нажимая на стрелку вверх и вниз.
И, наконец, нажав на значок со стрелками вверх в правом нижнем углу панели, мы имеем возможность скрыть её:
Нажмём на кнопку Summary: Regression results (Результаты регрессионного анализа). Появится Итоговая таблица регрессии, где суммированы результаты регрессионного анализа для каждой из независимых переменных
1. Beta - оценка стандартизированных коэффициентов регрессии, или бета-коэффициенты β из стандартизированного уравнения регрессии.
В нашем примере: beta (Возраст) = 0,95 и beta (Гемоглобин) = 0,048.
2. Std.Err. of Beta - стандартные ошибки стандартизированных коэффициентов регрессии.
В нашем примере: Std.Err. of Beta (Возраст и Гемоглобин) = 0,069.
3. B - оценка нестандартизированных коэффициентов регрессии, или "тета" θ из уравнения регрессии в "натуральном" виде со свободным членом (соответственно, значение Intercept у нас здесь будет присутствовать).
В нашем примере: В (Intercept) = 68,44; В(Возраст) = 1,25; В(Гемоглобин) = 0,04.
4. Std.Err. of B - стандартные ошибки нестандартизированных коэффициентов регрессии.
В нашем примере: Std.Err. of В (Intercept) = 3,15; Std.Err. of В(Возраст) = 0,09; Std.Err. of В(Гемоглобин) = 0,06.
5. t(13) - значения критерия Стьюдента (в скобках указано число степеней свободы) для проверки гипотезы о равенстве коэффициентов нулю.
В нашем примере: t(13)(Intercept) = 21,72; t(13)(Возраст) = 13,73; t(13)(Гемоглобин) = 0,69. Чем больше t, тем ниже вероятность того, что коэффициент равен нулю.
6. p-level - уровня значимости для предыдущего t-показателя
В нашем примере: для Intercept и Возраст значительно меньше 0,001, что высокозначимо; для Гемоглобин р = 0,50, что незначимо.
Итак, несмотря на теоретические сведения о влиянии уровня гемоглобина на величину давления, у нас этот фактор оказался совершенно не значимым. Причин может быть много, так как мы не располагаем сведениями о выборке, на которой мы работаем. Вероятно, это данные пациентов, на которых проводимая терапия повлияла таким образом, что на величину САД стали оказывать другие факторы, причём так, что гемоглобин оказался незначимым!
*Полученные автоматически значения для удобства округлялись до сотых.