Лет 5 назад я написал статью с аналогичным названием, но про деление.
Там я красочно и в картинках попытался описать, почему у детей возникают проблемы с делением, почему вдруг дети разучились делить.
Но школьники нынче не умеют и умножать (там даже в комментариях написали, что с умножением та же проблема).
Если мои читатели оглянутся назад, то с уверенностью могут сказать "в наше время такого не было!" Ну в самом деле, в школах раньше могли не знать теорему синусов или векторы, но уж таблицу умножения знали все!
Казалось бы - что может быть проще таблицы умножения? Ан нет. Многие дети, даже выучив таблицу умножения, умножать не умеют. (А большинство её просто не учат).
В статье про деление я описал проблему недостаточно чётко. Постараюсь исправиться.
Оптимизация умножения
Давайте посмотрим, как выглядит умножение, скажем 1573*352 в классической записи умножения "столбиком". Так всех учат в начальной школе:
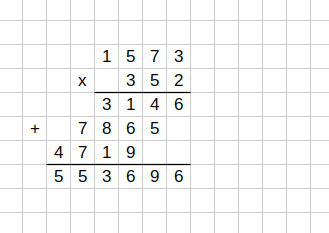
Вот всем понятно, что тут написано? Я на полном серьёзе. Может ли каждый взрослый читатель рассказать, какая цифра что значит и откуда взялась?
А меня-то больше интересует ещё вот какие два момента:
1) много ли шагов здесь пропущено (скрыто "между строк")?
2) можно ли восстановить эти шаги, не имея опыта умножения, только по картинке?
Я сейчас распишу этапы появления этой записи, но немного в ином ключе, чем привыкли читатели.
Умножение - суть многократное сложение (как бы там кто ни утверждал иное). Один множитель - что складываем, второй - количество раз (но не сколько раз складывать, а сколько раз брать).
И если пользоваться определением, у нас получилась бы такая запись:
Хоть эта запись уже укороченная (сложение выполнено "столбиком" в максимально оптимальной записи), её можно ещё "сгармошить", записывая лишь результаты сложений:
Если бы мы умножали на 4 или на 5 - проблемы бы не было совершенно. На этом можно было бы заканчивать. Но мы хотим сделать такой алгоритм, который бы позволял умножать на любые числа. На 352 умножать и так уже довольно тяжело - слишком много писать. А если на 1024 умножать захотим? Тыщу строк писать? Рука отвалится.
Есть общеизвестный способ укоротить этот процесс. Выполнять сложение не штуками, а "пачками". Например, мы знаем, что если один раз - 1573, то десять раз - ... 15730. Запись идентичная, но с "добавлением" нолика в конце. Поэтому можно запись сократить в 10 раз, если складывать не штуками, а "пачками" по 10!
Ну почти в 10 раз (в конце всё равно пришлось дважды добавлять не "пачками", а штуками).
Легко догадаться, что можно прибавлять и сотнями, тысячами и вообще - любыми пачками, запись которых получается из исходного числа дописыванием нолика. Почему именно такими пачками? Потому что нет необходимости что-то вычислять: все вычисления заменяются на дорисовывание.
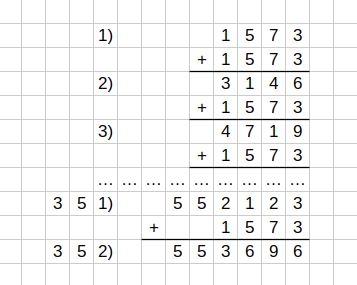
В общем-то, многоточия можно было бы не писать, там пропущено всего две строки 320 и 330.
Итого мы сложили сотни раз по 1573 - трижды, десятки раз - пять раз и штуками - дважды.
Теперь мы можем поступить, как я предлагал в статье про деление - составить частную таблицу умножения для числа 1573, и складывать только "один" раз. Если в таблице "дописать" нолики, то мы сразу получим и 2 раза, и два десятка раз и даже две сотни раз (аналогично с 300 и 50).
На картинке красным выделены нолики, которые приписались для получения пачек по 10, а зелёным - пачек по 100 (десять пачек по десятку). Напоминаю, что каждая строчка получается из предыдущей путём прибавления первого множителя (1573).
Отсюда уже можно получить почти полноценную запись умножения столбиком. Достаточно поменять местами слагаемые - наверх поднять разы, а вниз опустить сотни раз. И записать исходные множители.
Последний шаг оптимизации - стирание цветных ноликов - я расписывать не будут. В данном варианте умножения - это всего лишь экономия чернил (хотя, в комментариях про деление кто-то там писал, что его всякие нолики раздражали как трата времени и места в тетради).
То есть смотрите, что получилось. В привычной нам короткой записи умножения "столбиком" скрыты несколько этапов весьма нетривиальной оптимизации, с использованием особенностей позиционной десятичной системы счисления.
В принципе, мы получили весьма приемлемую оптимизацию алгоритма - из простого сложения O(n) раз, мы получили всего десять сложений (на самом деле 8, но с учётом нуля и одного мы получим 10 строк в частной таблице умножения) - то есть, O(1) действий. Однако добавились ещё O(log n) сложений промежуточных произведений и столько же "приписок" (которые вообще за действие нет смысла считать).
На этом можно было бы и остановиться.
Продолжение оптимизации
Но возникает интересный путь "дооптимизации".
У нас ещё остался столбец "частной таблицы умножения". Который тоже можно оптимизировать. Говоря прямо - убрать из записи. Но для этого нужно как-то получить промежуточные слагаемые.
Обратили внимание, что второй множитель у нас как-то естественно разбился на отдельные десятичные цифры? Вместо 352 мы имеем отдельно 3 сотни, 5 десятков и 2 штуки.
Путём довольно хитрых манипуляций, первый множитель тоже разбивается на цифры.
По сути дела, теперь трижды производится всё вышеописанное, но первым множителем выступают цифры второго множителя, а вторым множителем - первый множитель целиком.
Ну, такая заумная фраза, надо её разжевать. То есть, мы умножаем не 1573 на 3, 5 и 2 по очереди, а наоборот - 2 на 1573, 3 на 1573 и 5 на 1573. Проводим все те же рассуждения, получаем для каждого случая частные таблицы умножения (для 2, 3 и 5), и получаем, что 1573 тоже разобьётся на цифры - 1 тысяча, 5 сотен, 7 десятков и 3 единицы.
Получим перемножение каждой цифры первого множителя с каждой цифрой второго множителя. И так чисто "совпало", что из этих произведений будут состоять и промежуточные произведения 3146, 78650 и 471900 (мы этого и добивались).
Если мы умножения цифр выполним в уме, выполним перенос десятков "заранее", то получится прямо полноценный "столбик", к которому все привыкли:
Здесь условно точками обозначен перенос десятков, который по факту выполнялся "в уме", а в клеточки записывался только результат, а серым отмечено то, что выполняется "в уме".
Про перенос десятков скажу особо. С одной стороны, при сложении (например, во время составлении "частной" таблицы умножения") мы обязаны выполнять перенос десятков при переполнении разряда в каждом сложении. Это составная часть сложения столбиком, здесь нет ничего особенного. Но с другой стороны, числа, которые записаны в клетках предыдущей иллюстрации - это не цифры числа, полученного сложением, а числа - ответы "элементарных" умножений. Соответственно, перенос десятков происходит слегка по иным законам (например, может переноситься не один, а сразу несколько десятков, что отмечено несколькими точками).
О производительности. Конечно, у нас резко упала производительность. Вместо O(log n) мы получили O(log n * log m). Вне зависимости от порядка множителей, мы вынуждены сделать 12 умножений (из-за повторений можно выполнить 11 умножений), в то время, как в предыдущем варианте умножения, приходилось выполнить 8 сложений. Порядок множителей лишь позволит получить меньше промежуточных результатов, и нам потребуется O(min(log n, log m)) сложений.
С другой стороны, у нас теперь нет необходимости задумываться о разрядных весах и прочих особенностях позиционной записи. Если раньше во втором множителе цифра "3" значила 300, то в таком варианте оптимизации, теперь цифра "3" значит 3. Важным этапом можно считать то, что мы перешли от "частной" таблицы умножения, которую надо было составлять для каждого умножения, к "общей" таблице умножения, которую нужно заучить всего 1 раз на все возможные умножения.
При всём количественном усложнении процесса, алгоритм упростился качественно. Он стал более формализуемым, не допускающим отклонений, более масштабируемым.
В этот момент математика перестала требовать понимания. Единственное требование - знать таблицу умножения, чтобы выполнять много маленьких умножений.
Восприятие алгоритма
А теперь давайте посмотрим, на этот алгоритм в отрыве от всего этого пути оптимизации.
Выполняя на первый взгляд бессмысленный ритуал алгоритм, мы получаем верный ответ на умножение.
Алгоритм сводится к тому, что нужно разбить оба множителя на десятичные цифры, перемножить каждую с каждой (чтобы не запутаться, видимо, запись производится в определённые клетки), получить из отдельных произведений целые числа, сложить результаты. Ах да, предварительно нужно выучить таблицу умножения, иначе придётся подглядывать.
Ну что, много можно из этого понять?
Об оптимальности
Как мы видим, классический метод умножения столбиком через таблицу умножения не только не самый короткий по действиям (вычислительной сложности), но ещё и требует дополнительной табличной информации.
При этом уменьшить количественно этот алгоритм просто невозможно. То есть, это предел автоматизации.
Оптимальность тут, конечно, не с точки зрения производительности. Оптимальность тут следует читать как "минимизированы требования к пониманию".
Ну, то есть, его уже некуда упрощать. Проще некуда!
Кстати, если рассматривать "мой" способ с "частной" таблицей умножения (на котором я предлагал остановиться), то у него есть ещё средства оптимизации. Оптимизировать сам "столбик" уже просто некуда, но можно сэкономить на составлении частной таблицы умножения.
Например, можно заметить, что эту самую "частную" таблицу умножения мы используем не всю. Поскольку после этого умножения таблица не пригодится больше никогда, можно её и не составлять целиком. В приведённом примере можно было бы не складывать дальше пятой строчки 5) 7865.
Кроме того, можно "перескакивать" через строки, используя уже полученные строки. Например, строка 4 не используется, можно было бы к 4719 прибавить не 1573, а сразу 3146. И тогда 5 раз по 1573 у нас получилось бы автоматически как 3 раза и ещё 2 раза.
О подсистемах для умножения
Как я сказал в статье про подсистемы мышления, мозг должен столкнуться с рутинной работой и тогда он создаст под неё подсистему, которая будет выполнять эту работу, не задействуя основное ядро мышления. Но для создания подсистемы, работа должна иметь пути оптимизации. Соответственно, максимально оптимизированный алгоритм умножения столбиком не подходит под этот критерий. Он хоть и рутинный, но он не может быть оптимизирован (по крайней мере, по смыслу), и каждый раз для выполнения умножения потребуется будить ядро мышления.
Запоминание таблицы умножения не создаст подсистему. Не могу пока объяснить, почему, но вот такие запоминалки не включаются как подсистемы, и всегда требуют обращения к ядру.
Как правило, создаются подсистемы, напрямую не связанные с умножением, автоматизирующие некоторые отдельные шаги алгоритма. Но если сознание не будет контролировать все эти отдельные шаги, то легко, например, потерять разряд.