
Компания Nvidia, создающая одни из самых востребованных графических процессоров в индустрии ИИ, объявила о выпуске открытой модели большого языка, которая, как сообщается, работает наравне с ведущими собственными моделями от OpenAI, Anthropic, Meta и Google.
Компания представила свое новое семейство NVLM 1.0 в недавно опубликованном техническом документе, и его возглавляет модель NVLM-D-72B с 72 миллиардами параметров. «Мы представляем NVLM 1.0, семейство мультимодальных больших языковых моделей передового класса, которые достигают самых современных результатов в задачах видения-языка, конкурируя с ведущими собственными моделями (например, GPT-4o) и моделями с открытым доступом», - пишут исследователи.
Представляем NVLM 1.0, семейство мультимодальных LLM передового класса, которые достигают самых высоких результатов в задачах «зрение-язык», конкурируя с ведущими собственными моделями (например, GPT-4o) и моделями открытого доступа (например, InternVL 2).
Примечательно, что NVLM 1.0 демонстрирует улучшенную работу только с текстом... pic.twitter.com/yKGyOqHnsp
— Вэй Пин (@_weiping) 18 сентября 2024 г.
Сообщается, что новое семейство моделей уже способно к «мультимодальности производственного уровня», демонстрируя исключительную производительность в различных зрительных и языковых задачах, а также улучшенные текстовые ответы по сравнению с базовым LLM, на котором основано семейство NVLM. «Чтобы достичь этого, мы создали и интегрировали высококачественный набор данных только по тексту в мультимодальное обучение, а также значительный объем мультимодальных данных по математике и рассуждениям, что привело к улучшению математических способностей и возможностей кодирования по всем модальностям, - объясняют исследователи.
В результате LLM может так же легко объяснить, почему мем смешной, как и решить сложные математические уравнения, шаг за шагом». Благодаря мультимодальному стилю обучения Nvidia также удалось повысить точность модели при работе с текстом в среднем на 4,3 балла в распространенных отраслевых бенчмарках.
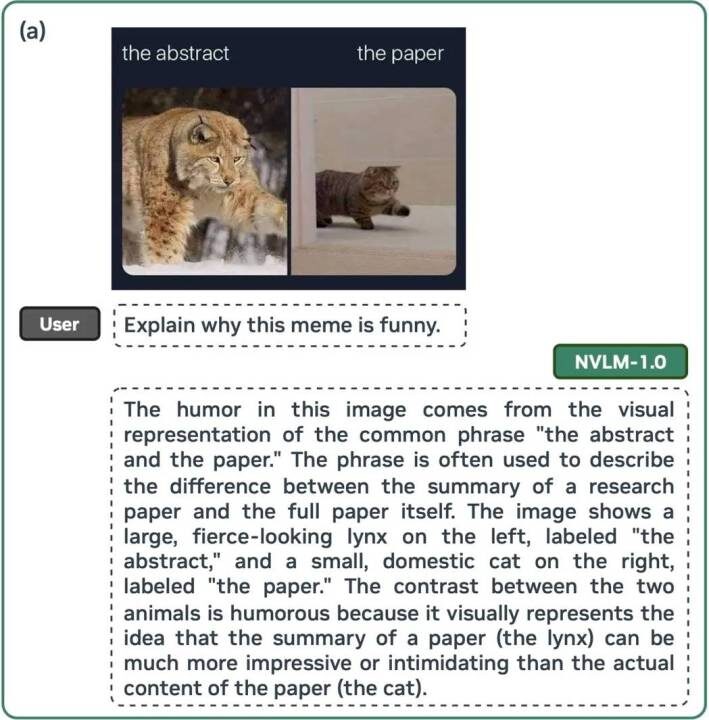
Nvidia, похоже, серьезно настроена на то, чтобы эта модель соответствовала новому определению Open Source Initiative как «открытый исходный код»: она не только выложила свои обучающие веса в открытый доступ, но и пообещала выпустить исходный код модели в ближайшем будущем. Это заметно отличается от действий таких конкурентов, как OpenAI и Google, которые ревностно охраняют детали весов и исходного кода своих LLM. Таким образом, Nvidia позиционирует семейство NVLM не как прямую конкуренцию ChatGPT-4o и Gemini 1.5 Pro, а как основу для создания сторонними разработчиками своих собственных чат-ботов и приложений искусственного интеллекта.
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Вы также можете читать меня в:
- Telegram: https://t.me/gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru



















