Ниже поговорим о том, как более практично использовать нейросети.
RAG (retrieval augmented generation) - тряпка генерация с расширенным поиском, технология позволяющая натравить нейросеть на ваши файлы и получать не бесполезные общие ответы, а ответы касающиеся содержания именно ваших документов, книг, писем и т.п.
Технология довольно тривиальная, ваши файлы разбиваются на кусочки и сохраняются в векторной базе данных, когда вы что-то спрашиваете у языковой модели, производится поиск в базе данных, и к вашему промту (запросу) добавляются найденные кусочки текстовых файлов, и языковая модель отвечает уже с учетом этого контекста.
Вы спросите, нафига нам этот костыль в 2к24, когда каждая первая модель поддерживает контекст минимум в 128к, и есть Gemini с контекстом в 2 миллиона токенов (подозреваю, что в нем тоже RAG используется)? Причина прозаична, большой контекст требует большее количество памяти. Так, например, 10к токенов (слов) кодируется в матрицу 10к на 10к, то есть (10^4)^2 = 10^8 чисел. Если мы их записываем в формате float16, то есть 2 байта на число, получается 2*10^8 байт, это 200 МБ памяти. Проделав те же вычисления с контекстом 100к токенов получим уже 20ГБ памяти. У многих из вас есть столько лишней видеопамяти (или даже ОЗУ) при загрузке языковой модели? А контекст в 1 миллион токенов потребует 2 терабайта памяти.
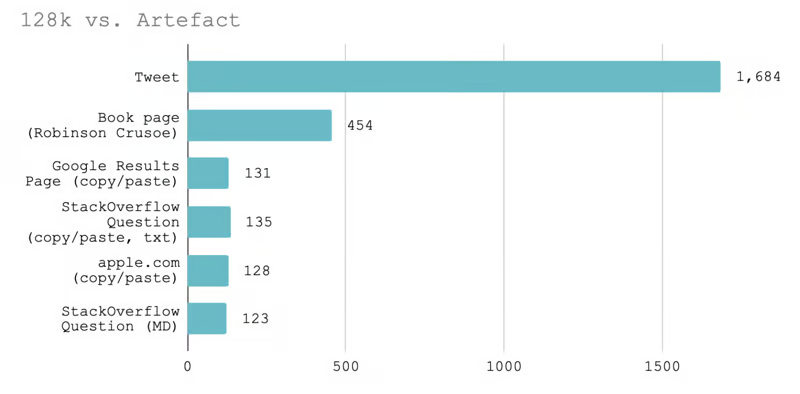
Люди подсчитывали, сколько и чего помещается в контекст 128к, согласитесь, не много, примерно 450 книжных страниц.
Стоит сделать оговорку, что это относится к стандартным transformers, коими пока являются 99% используемых языковых моделей. Но исследования ведутся и уже говорят о бесконечном контексте, вот например:
А Magic заявили о контекстном окне в 100 миллионов токенов в их модели LTM-2-mini:
Светлое будущее нас ожидает, но пока вернемся к реальности, чтобы обрабатывать большие объемы текстовой информации надо много памяти, и даже если программно мы можем масштабировать контекст сколько угодно, в железе - это очень дорого.
На помощь нам приходит RAG. Вышеописанный принцип работы RAG -самый примитивный, есть, например, такие, где в базе данных хранятся не просто кусочки документов, а кусочки документов с предварительно написанные нейросетью к ним вопросы, что делает поиск более быстрым и точным. Вообще за последний год вышли сотни алгоритмов по использованию RAG, многое уже реализовано, еще больше осталось просто концепциями и научными статьями.
Я же предлагаю поговорить о чем-то более шкурным, о том, что мы можем реально использовать здесь и сейчас, не заморачиваясь с изучением питона (большинство интерфейсов RAG реализованы с консольным интерфейсом), о RAG с удобным графическим интерфейсом.
Из названия публикации понятно, что речь пойдет о программе Anething LLM. Но сначала нельзя не упомянуть альтернативы.
Все, наверное, слышали про NotebookLM от гугла, который прославился тем, что создает аудиоподкасты по любым документам, которые вы в него загрузите. Жаль, конечно, что подкасты исключительно на английском языке. NotebookLM помимо этого является RAG системой, ты загружаешь свои файлы и Gemini с ними работает. Несомненный плюс этого сервиса - то, что он бесплатный и работает без VPN, если провести небольшое шаманство с DNS. Минус - гугл обучает свои модели на ваших данных.
Еще один пример всем известного RAG - это Copilot от мелкомягких в Windows 11. Сам я его не пробовал, но писали, что он скринит экран каждые несколько секунд и сохраняет их в RAG, из-за чего помнит любые действия пользователя. То, что он работает локально, дает надежду, что винду с копилотом завезут рано или поздно на рутрекер.
Вообще в той или иной степени RAG системы есть у все коммерческих нейросетей. Что до локальных систем, то почти все приложения по запуску языковых моделей потихоньку внедряют себе RAG функционал.
LM Studio с версии 0.3 начала поддержку загрузки файлов, и если размер файла превышает контекстное окно модели, LM Studio автоматически применяет RAG. Как они сами пишут, иногда этот метод работает действительно хорошо, но иногда он требует некоторой настройки и экспериментов.
Msty - набирающий популярность комбайн по запуску LLM, функционал шире, чем у LM Studio, а использование проще (во всяком случае они себя так позиционируют). Имеет встроенный RAG под названием "Стек знаний". Ничего плохого сказать не могу, если бы не простота AnythingLLM и хвалебные отзывы в пендосском интернете, возможно бы героем этой статьи был бы Msty.
Старичок SilluyTavern в представлении не нуждается, имел RAG еще за год до того, как это стало мейнстримом. У них RAG называется банком данных, и предполагалось, что он необходим для сохранения всей информации по игровым мирам, которые создаются в процессе RP, но никто не запрещает его использовать для любых целей, ведь банк данных поддерживает все те же источники, что и другие RAG (документы, ютуб, ссылки из интернета).
И наконец AnythingLLM, как написано у них на сайте, приложение искусственного интеллекта "все в одном". И оно реально пытается быть универсальным, дальше по тексту мы это увидим.
AnythingLLM - это полнофункциональное приложение, в котором вы можете использовать коммерческие готовые LLM или популярные LLM с открытым исходным кодом и решения vectorDB для создания приватного чата без компромиссов, который вы можете запускать локально, а также размещать удаленно и иметь возможность разумно общаться с любыми документами, которые вы ему предоставляете.
Нас интересует именно локальная составляющая этой программы, ввиду естественного запроса человека на приватность в разговоре с нейросетью.
И так приступим к установке.
Скачиваем установщик с официального сайта и устанавливаем.
При первом запуске приложение предложит провести настройку, не бойтесь выбрать что-то не так, потом всегда можно выбрать другие настройки.
Итак, первое, что предлагается - это выбрать языковую модель (LLM).
Вариантов много, прям очень много. Можно использовать коммерческие LLM, если есть ключи, можно подключаться к Ollama или LM Studio и вообще ко всему, что имеет api OpenAI, можно скачать модель с HuggingFace, можно использовать ранее скаченные GGUF. А можно скачать официально поддерживаемые AnythingLLM модели с их сервера. Предлагаю, для начала, так и поступить. Тыкаем по Llama3.1 8B и переходим к следующей странице.
Здесь пропускаем предложение отправить им свой емайл, переходим дальше и вводим название вашего рабочего пространства.
Все, AnythingLLM готов к работе. Приятным бонусом оказывается интерфейс с русским языком
Жмякаем по пиктограмме гаечного ключа в левом нижнем углу, выбираем пункт "Конфиденциальность и данные" и отключаем телеметрию (необязательно).
Пробуем.
Для начала нам нужно загрузить свои данные, тыкаем по копке:
Вылезает окно:
Сходу я не придумал, какие файлы использовать, поэтому решил использовать интернет ссылку. Есть забавная страничка на HuggingFace под названием "Ежедневная газета" на которой публикуют все вышедшие сегодня (или в любую дату) научные статьи про искусственный интеллект. Вот она, кстати.
Для использования интернет ссылки переходим во вкладку Data Connectors, как видим, можно подключать не только ссылки, но и Гитхаб, и Ютуб и еще что-то.
Нажимаем Bulk Link Scrape, вставляем ссылку, глубину ставим 2, максимальное число ссылок 50. Ждем.
Переходим обратно во вкладку Documents, выделяем скаченные странички и нажимаем Move to Workspace. Сохраняем.
Далее переходим в настройки рабочего пространства (шестеренка). Во вкладке "Векторная база данных" меняем количество контекстных фрагментов на число побольше, с дефолтными 4 у меня плохо работает. Но и слишком много тоже не ставим, помним про ограничение контекстного окна модели.
Вот результаты небольшого тестирования:
По-моему круто. Помимо этой основной функции AnythingLLM умеет озвучивать ответы и распознавать голос, мелочь, а приятно.
В последнем тесте я использовал модель Qwen2.5-3B-instruct-q4_k_m расшаренную с LM Studio. На удивление для размера меньше 2 GB она отвечает вполне разумно.
Есть и неудачный опыт, попробовал одну массивную книжку (размером 3 МБ текста) обработать, и ничего путного не вышло. Задаешь вопрос про середину книги, но RAG находит контекстные кусочки из начала книги, исчерпывает лимит и, естественно, ответ получается неправильный. В оправдание можно сказать только, то что NotebookLM от гугла тоже не осилил этот тест.
Помимо выбора LLM в этой программе можно выбрать стороннюю векторную базу, по дефолту стоит LanceDB.
Для тех, кто решил использовать этот инструмент в свое работе, у них есть подробная справка.
Резюмируя, хочется сказать, что AnythingLLM не идеален, но он определенно расширяет возможности человека во взаимодействии с языковыми моделями.