Сегодня я покажу простую демонстрацию потоковой агрегации данных из разных топиков Apache Kafka на примере Python-приложений для соединения событий пользовательского поведения с информацией о самом пользователе.
Постановка задачи
Рассмотрим примере кликстрима, т.е. потокового поступления данных о событиях пользовательского поведения на страницах сайта. Предположим, данные о самом пользователе: его идентификаторе, электронном адресе и имени попадают в топик под названием CorpAppsTopic. JSON-схема полезной нагрузки выглядит так:

Данные о непосредственного событиях пользовательского поведения, т.е. на какой странице сайта он что-то скачал, кликнул, просмотрел и пр., публикуются в топик test. Они тоже представлены в виде JSON-документов следующей структурой:
Данные в оба топика поступают непрерывным потоком, причем один и тот же пользователь может совершить от 1 до 10 событий на любых веб-страницах. Необходимо получить агрегированные данные о том, сколько событий совершил каждый пользователь и сколько видов событий совершено вообще.
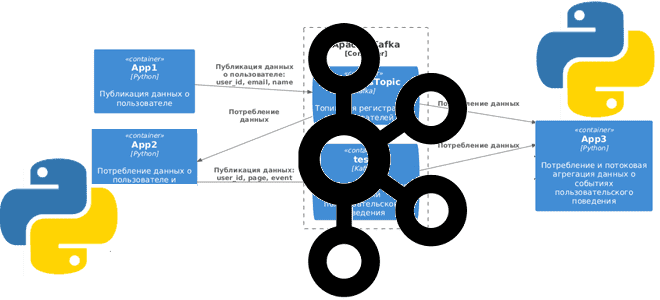
Чтобы реализовать эту задачу, прежде всего надо написать код приложений-продюсеров, которые будут публиковать данные в Kafka. А, поскольку, данные о пользователе используются для генерации событий пользовательского поведения, одно и то же приложение будет одновременно и потреблять данные из одного топика Kafka, и публиковать их в другой. Схематично это будет выглядеть так:
Скрипт PlantUML для отрисовки диаграммы:
Разобравшись с топологией потоковой системы, далее реализуем код для публикации и потребления данных.
Публикация и потребление данных в Kafka
Как обычно, экземпляр Kafka у меня развернут в облачной платформе Upstash, а писать приложения я буду на Python, используя библиотеку kafka-python. Код приложения-продюсера, которое каждые 3 секунды генерирует фейковые данные о пользователях, выглядит так:
Идентификатор пользователя вычисляется как строка от результата применения хэш-функции к его емейлу.
Код приложения, которое потребляет эти данные о пользователе и случайным генерирует события на веб-страницах, выглядит так:
Для потоковой агрегации данных из 2-х топиков надо написать еще одно приложение. Потреблять данные оно будет одновременно из разных топиков. Его код выглядит так:
Чтобы вычислить, сколько событий совершил каждый пользователь, надо соединить данные из топика CorpAppsTopic с данными из топика test по ключу user_id. А чтобы понять, сколько событий каждого вида совершено, нужно сделать агрегацию данных из топика test с группировкой по полю event.
Разумеется, все события публикации и потребления данных можно посмотреть в GUI платформы Upstash, на которой развернут экземпляр Kafka.
Таким образом, чтобы реализовать эту довольно простую с точки зрения бизнес-постановки задачу, пришлось писать полноценный потребитель. Вместо этого можно использовать коннекторы потоковой базы данных RisingWave, о которой я писала здесь. Как это сделать, покажу завтра в новой статье.
Освойте все тонкости работы с Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Копирование, размножение, распространение, перепечатка (целиком или частично), или иное использование материала допускается только с письменного разрешения правообладателя ООО "УЦ Коммерсант"