Откуда такой заголовок, и в чём суть проблемы?
Кодирование Хаффмана это алгоритм сжатия данных, древний, известный и несложный.
Конкретно у меня возникла трудность с его пониманием. То есть, я много раз про него слышал, формально знаю как работает, но это знание о каких-то механических действиях, которые просто делаются и что-то получается. Я читал труд Хаффмана в оригинале, читал Википедию, читал обсуждения на StackOverflow, даже у ChatGPT спрашивал. В итоге всё равно не понял.
Так бывает, когда пропускаешь какую-то одну деталь и без неё головоломка никак не складывается. И именно эту деталь тебе никто не может сообщить.
Поэтому я тут буду есть медведя по частям и попробую, начиная с низов, прийти к полному пониманию.
Начну не с самого Хаффмана, а с введения в проблему.
Сжатие сообщения
Вот у нас есть сообщение, состоящее из символов. Каждый символ сообщения закодирован каким-то кодом.
Небольшое замечание. В теории кодирования это не "код", а "кодовое слово", но я уже пробовал так писать, и получалось слишком неуклюже, поэтому буду сокращать до просто "код" в бытовом, а не теоретическом понимании.
В нашем примере сообщение состоит из символов ASCII, и символы кодируют сами себя в том виде, в каком они есть. Например, символ 'A' хранится как числовое значение 65, поэтому можно сказать, что символ 'A' имеет код 65.
Длина одного кода, таким образом – 8 бит. Как можно сжать сообщение?
Предположим, оно состоит только из 32 уникальных символов, куда входят буквы латинского алфавита и какие-нибудь знаки препинания.
Этим уникальным символам можно назначить новые коды, по сути порядковые номера, со значениями от 0 до 31, и тогда на хранение одного кода потребуется 5 бит вместо 8. Вот мы как бы уже и сжали сообщение в 1,6 раза.
Префиксные коды
Чтобы сжать сообщение ещё сильнее, требуется ввести коды переменной длины.
Можно пройтись по всему сообщению и посчитать частоты символов. Например, в слове ABRAСADABRA частоты следующие:
A: 5
B: 2
R: 2
C: 1
D: 1
Так как символ A встречается наиболее часто, то логично назначить ему самый короткий код 0. Затем символ B с кодом 1. Затем R с кодом 00, C с кодом 01 и D с кодом 10.
Получается, что длина кодов A и B – 1 бит, длина кодов R, C и D – 2 бита. И самые короткие коды используются чаще всего.
Теперь исходное сообщение побитно закодировано так:
0, 1, 00, 0, 01, 0, 10, 0, 1, 00, 01
Соединяем всё в цепочку бит: 0100001010010001. Получили длину сообщения 16 бит.
Следующая задача это декодировать сообщение, то есть восстановить его. Необходимое условие для этого – словарь, с помощью которого оно кодировалось. Он у нас есть, и там обозначено, что 0 это A, 1 это B, и т.д.
Но мы сталкиваемся с проблемой. Если бы все коды в сообщении были одной длины, например 3 бита, тогда A был бы 000, B был бы 001 и т.д., и мы бы просто читали сообщение порциями по 3 бита.
Но так как они разной длины, то глядя на начало сообщения 01000..., мы не знаем, какой символ там первый. Это A с кодом 0, или C с кодом 01? А дальше будет B с кодом 1 или D с кодом 10?
Проблема возникает из-за того, что код C = 01 содержит в начале другой код A = 0, как префикс.
Чтобы решить проблему, надо, чтобы ни один код в наборе не являлся префиксом другого кода.
Такой набор кодов будет в терминах теории кодирования называться "префиксным кодом", а также "беспрефиксным кодом". Ахахах, противоречиво, да, но реально есть два варианта названия.
И вот примерно отсюда начинается Хаффман, потому что его задача – построить такой префиксный код.
Я взял просто общие положения и пытаюсь сейчас самостоятельно что-то вымутить.
Как избежать совпадения префикса?
Ещё раз перепишу текущий алфавит:
A: 0
B: 1
Я могу составить последовательности ABBA, BABA и т.д., и там всё будет хорошо, так как A и B не являются префиксами друг друга.
Далее,
R: 00
C: 01
Уже очевидно, что R можно понять как AA, а C как AB. Тогда я переделываю всё вот так:
A: 00
B: 01
R: 100
C: 101
Отличительным признаком является наличие 1 в начале кода. Встретив в начале 1, я точно буду знать, что это не A и не B. Далее:
D: 1100
E: 1101
F: 11100
G: 11101
Я дописал новые символы, чтобы проследить закономерность. Единицы, идущие подряд, формируют уникальное начало кода, которое не совпадает ни с одним из предыдущих начал, вслед за которым находится значение 00 или 01.
Кодирую пример по новой методике:
A: 00
B: 01
R: 100
C: 101
D: 1100
И всё сообщение: 00, 01, 100, 00, 101, 00, 1100, 00, 01, 100, 00, или 000110000101001100000110000. Получилась длина 27 бит.
Теперь попробуем раскодировать обратно. Для этого читаем по одному биту и накапливаем значение до тех пор, пока оно не совпадёт с чем-то из словаря.
0: не совпадает ни с чем, накапливаем
0: получили 00, совпало с A, вернули A, сбросили текущее значение
0: не совпадает ни с чем, накапливаем
1: получили 01, совпало с B, вернули B, сбросили текущее значение
1: не совпадает ни с чем, накапливаем
0: получили 10, не совпадает ни с чем, накапливаем
0: получили 100, совпало с R, вернули R, сбросили текущее значение
Как видим, мы успешно вернули первые три символа ABR, и так можно продолжать дальше.
Тут можно подвести черту и сказать, что Хаффман реализован. По-своему, по-наивному, но реализован. Что же тогда остаётся непонятным?
Во-первых, Хаффман в процессе строит дерево, во-вторых, его коды получаются не такие, как у меня. По моей методике получается, что уникальной частью кода могут быть только последовательности 111... или 000..., смотря как выбрать базу. У Хаффмана же такого правила нет, но коды тем не менее получаются уникальные.
Дерево
В реализации дерева как такового у меня необходимости нет, но сама структура кодов логически уже является деревом, так что оно есть, просто потому что есть:
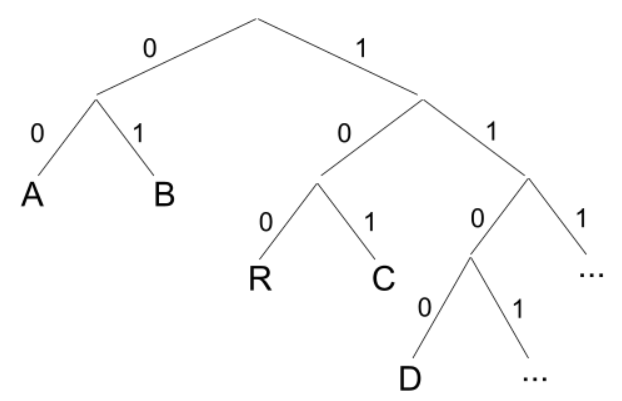
Выше речь шла о считывании сообщения побитно и поиске совпадающего кода. Так вот дерево позволяет эффективно его искать. К примеру, мы в процессе считывания кода 1100 и ищем от корня дерева побитно: если 1, то идём вправо, если 0, то влево, пока не придём к конечному узлу. В данном случае, двигаясь по веткам 1-1-0-0, мы придём к D.
У Хаффмана то же самое, только дерево строится по-другому. Если моё дерево достраивать дальше, получится вот такая повторяющаяся структура:
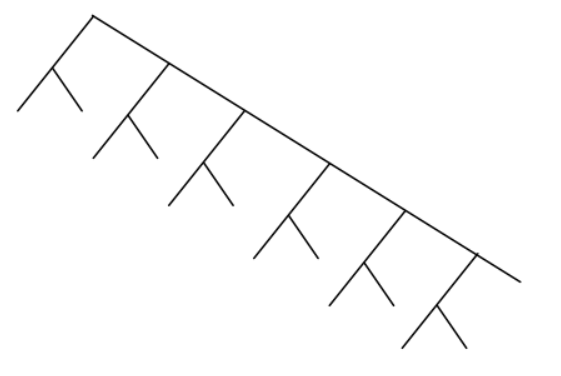
У Хаффмана же оно сбалансировано. Попробуем построить по Хаффману, пользуясь готовыми инструкциями. Нужно сразу создать конечные узлы дерева в виде A, B, C, D, R, и назначить им веса (частоты использования).
A:5 B:2 R:2 C:1 D:1
Затем берём пару самых редких узлов и делаем из них поддерево с новым весом (суммой весов).
Повторяем процесс. Теперь можно соединить B:2 либо с R:2, либо с CD:2, либо R:2 с CD:2.
Далее соединяем BR:4 и CD:2.
И остаётся только соединить A:5 и всё остальное:
Посмотрим, какие коды получились на этот раз:
A: 0
B: 100
R: 101
C: 110
D: 111
Всё сообщение: 01001010110011101001010, 23 бита. У меня было 27, у Хаффмана получилось меньше. Я понимаю, почему – за счёт лучшей сбалансированности дерева и оптимизации кодов по длине. Но какова логика построения?
Логично то, что наиболее редкие символы находятся в самом низу дерева, то есть у них самые длинные коды. Логично также строить дерево с конца, автоматически удлиняя код для всех веток, которые уже есть, при надстройке над ними новой ветки. Самые частые символы попадут на вершину дерева и будут иметь самые короткие коды.
Стало быть, моя проблема в том, что я создавал коды начиная с самого частого символа, присваивая ему 0, затем следующему 1 и т.д. Вроде как всё так и надо, но возникает проблема с уникальным префиксом 111..., который удлиняется через каждые два шага, и значит длина кода слишком быстро вырастает. А почему через два? Потому что у меня эффективный диапазон значений только 00 и 01. Я мог бы выбрать 000, 001, 010, 011, тогда наращивать префикс можно было бы только через 4 шага. Но базовая длина кода при этом увеличивается на 1. То есть проблема в том, что двигаясь от начала, я не могу предсказать, как мне сбалансировать базовую длину кода и частоту наращивания префикса.
Как уникальные префиксы получаются у Хаффмана?
Каждая первая пара символов по умолчанию уникальна, так как они имеют коды 0 и 1 и не могут являться префиксами друг друга. Но вот появилась вторая пара символов, у которых тоже коды 1 и 0.
Эти две пары позже свяжутся в новую пару. При этом пара BR:4 получит дополнительный префикс 0, а пара CD:2 получит дополнительный префикс 1.
Код удлинился на 1 бит и теперь B = 00, R = 01, C = 10, D = 11. Уникальность сохранилась за счёт удлинения кода и назначения каждой паре своего уникального начального бита. При дальнейших объединениях пар каждой из веток будет назначаться дополнительный бит 0 или 1, код будет удлиняться, и следовательно каждый раз будет оставаться уникальным.
Пожалуй, понял.
Читайте дальше: