«Институт Извлечения Информации (ИНИЗИН)» - поистине огромный институт с многими лабораториями. Мы посетили несколько из них, и в каждой целые бригады докторов и кандидатов наук колдовали над маленьким кусочком какой-то пленки. Рассматривали ее в микроскоп, просвечивали рентгеновскими лучами, окунали в химические растворы и кололи иголками. В каждой лаборатории я спрашивал ученых, чем они занимаются, они смотрели на Эдисона Ксенофонтовича, а тот весело хохотал. Когда мы очутились на улице он сказал:
— А помните, вы привезли с собой такую вот квадратную черную штучку? Мы её называем дискеттой.
— Флоппи-диск? — спросил я. — Но зачем же они ее разрезали?
— Ну как же. Они пытаются извлечь заложенную в нее информацию.
(С) Владимир Войнович «Москва 2042».

Даже при том, что такие методы обработки естественного языка (Natural Language Processing, NLP), как сегментация предложений, лексемизация, фрагментация слов и определение сущностей, необходимы для достижения более глубокого понимания текстовых данных, для начала полезно познакомиться с некоторыми основами из теории поиска информации. Фундаментальные аспекты этой теории — метод извлечения релевантных документов из корпуса - TF-IDF (Term Frequency/Inverse Document Frequency — частота слова/обратная частота документа) и метрика косинусного сходства.
Математически TF-IDF выражается как произведение частоты слова на обратную частоту документа: tf_idf = tf x idf, где tf представляет важность слова в конкретном документе, а idf — важность слова для всего корпуса. Их произведение даёт оценку, учитывающую оба фактора.
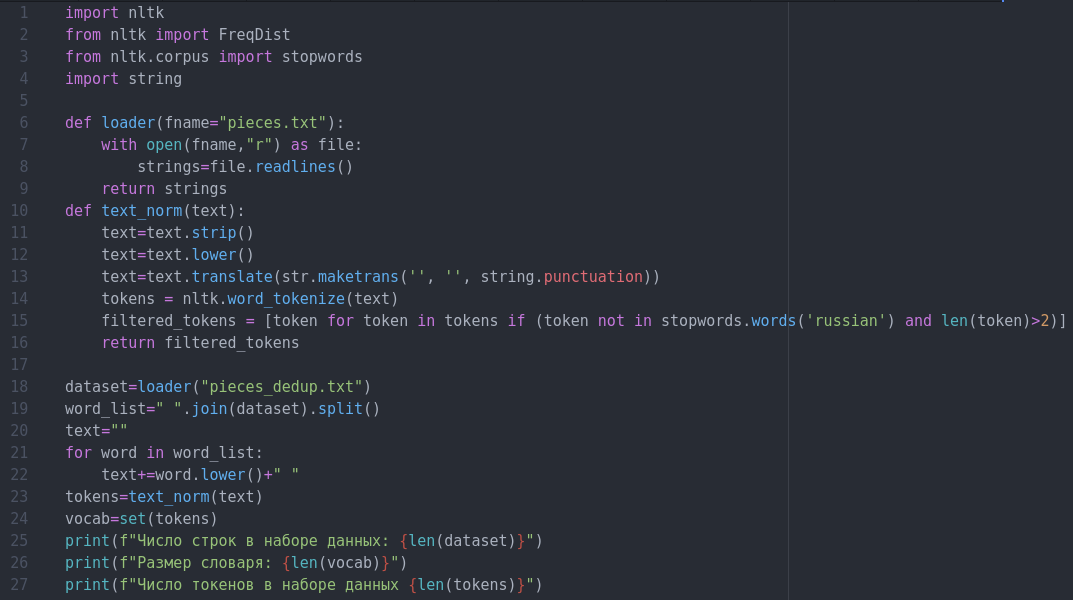
Подсчитаем частоту слов в корпусе из 10 000 строк, уже применявшемся в предыдущей статье. Для начала загрузим этот набор и импортируем необходимые библиотеки из пакета nltk.
Посмотрим ещё раз на некоторые возможности nltk для работы с текстом.
Метод collocations() - позволяет вывести найденные в корпусе словосочетания.
Метод concordance() - показывает примеры вхождения слова в тексте.
В словарь fdist помещаются частоты слов в корпусе.
Метод most_common позволяет получить наиболее часто встречающиеся слова в корпусе.
Результат выполнения программы:
Зная частоту слова (токена) и общее количество слов, можно рассчитать его значимость в тексте просто поделив первое число на второе. Например для слова «человек» частота: 128, а общее количество токеннов: 35571, значит значимость этого слова в корпусе: 128/35571=0,003598437.
То же самое можно получить используя ngrams и FreqDist из nltk:
Построим график частотного распределения слов в виде столбчатой диаграммы, где по оси X будут отображаться слова, а по оси Y — их частоты. Каждое слово будет отдельным столбцом, высота которого будет соответствовать его частоте.
Результат выполнения программы:
Огибающая этого графика демонстрирует эмпирический закон частотного распределения слов в текстах на естественных языках (закон Ципфа), согласно которому частота слова в корпусе обратно пропорциональна его порядковому номеру (рангу) в таблице частот. Большая часть области в таком распределении лежит в его хвосте.
Вычислим оценку TF-IDF для текстовой выборки и посмотрим, как её можно использовать для определения релевантности документов запросу.
Для начала обратится к формулам.
Term Frequency (частоту слова) мы уже получим применив ngrams и FreqDist из nltk.
Результат выполнения программы:
Теперь получим оценку IDF для каждого слова. Для этого напишем функцию, которая будет получать список всех строк нашего набора данных, а возвращать словарь, в котором каждое слово — ключ, а его оценка IDF — вещественное значение.
Результат выполнения программы:
У нас есть всё, чтобы вычислить оценку TF-IDF для каждого слова путём умножения оценок TF и IDF.
Результат выполнения программы:
Если нам нужно сопоставить новый текст с записями из набора данных, то TF заново рассчитывается для каждого слова этого нового текста, а IDF используется уже рассчитанный ранее. Поэтому имеет смысл написать эту функцию отдельно.
Пример использования:
Результат выполнения:
Имея набор функций для расчёта TF-IDF мы можем выполнять информационный поиск строк в наборе данных, наиболее близких запрашиваемой строке.
Результат выполнения программы:
Другие пример:
Ещё пример:
Ещё пример:
Абстракции TF, IDF и TF_IDF реализованы и в nltk.Textcollection(), поэтому в реальных задачах обычно нет необходимости писать их собственные реализации.
Результат выполнения программы:
Абсолютные значения оценок релевантности в этом примере отличаются от результатов предыдущего примера, но на самом деле это мелочь, по сравнению с самой возможностью найти и отсортировать тексты по релевантности запросу.
Одно очевидное улучшение заключается в том, чтобы привести глаголы к общему основанию, устранив различия в их написании. Некоторые простые в использовании реализации алгоритмов стемминга доступны в модуле nltk.stem. Для русского языка лучший результат можно получить лемматизировав текст с помощью пакета инструментов для обработки естественного языка Natasha. Пример работы с этим пакетом был рассмотрен в статье «Датамайнинг текстов»:
У нас есть готовый набор тех же самых строк, прошедших лематизацию с помощью Natasha. Загрузить его можно отсюда:
Загрузим его в программу и посмотрим насколько велика получится разница в поиске релевантных запросу строк.
Результат выполнения программы:
Результат выполнения программы:
При обработке неструктурированного текста часто упускается из виду возможность получить ценную информацию за счёт рассмотрения нескольких лексем вместе. Между тем, многие понятия мы выражаем фразами, а не отдельными словами. Применение n-грамм даёт простой и эффективный метод кластеризации слов, часто встречающихся вместе.
Найдём наиболее часто встречающиеся словосочетания в нашем наборе данных.
Результат выполнения программы:
Теперь с помощью TF-IDF найдём документы наиболее релевантные данным сочетаниям:
«мудрый правитель»
«выполнять функция»
После обработки и обнаружения релевантных документов следующим естественным шагом является определение сходства документов. Если для выборки из корпуса документов, соответствующих поисковому запросу, можно использовать оценку TF-IDF, то для определения сходства документов можно использовать оценку косинусного сходства, которая является одним из наиболее распространённых методов сравнения документов друг с другом.
В основе идеи косинусного сходства лежит модель представления в векторном пространстве.
Метод TF-IDF представляет документы как неупорядоченные наборы слов. В большом многомерном векторном пространстве каждому документу соответствует свой вектор, а расстояние между любыми двумя векторами определяет степень сходства соответствующих документов. Можно представить запрос в виде вектора и обнаружить наиболее релевантные документы, определив векторы документов с наименьшим расстоянием до вектора запроса.
Вектор в данном случае — список чисел, выражающий направление относительно начала координат и расстояние от этого начала. Вектор можно представить в виде отрезка, соединяющего начало координат и точку в N-мерном пространстве.
Например, если документ представлен словами («Open» и «Web») с соответствующим вектором (0.45, 0.67), элементами которого являются такие значения, как оценки TF-IDF для слов. В векторном пространстве этот документ можно представить отрезком в двумерной системе координат, соединяющим начало координат (0, 0) и точку (0.45, 0.67).
В координатной плоскости X/Y ось X будет представлять слово «Open», ось Y — слово «Web», а вектор от (0,0) до (0.45, 0.67) — рассматриваемый документ. В документах из большего числа слов действует тот же принцип построения векторов, просто добавляется больше осей.
Учитывая, что документы можно моделировать в виде векторов в пространстве слов, каждый член которых представлен соответствующей оценкой TF-IDF, задача сводится к тому, чтобы определить метрику, наилучшим образом представляющую сходство между двумя документами. Часто в качестве такой метрики успешно используется косинус угла между ними, и называется эта метрика косинусным сходством векторов. Определяется она как скалярное произведение соответствующих единичных векторов.
Как только у нас будут наши векторы, мы можем использовать де-факто стандартную меру сходства для этой ситуации: косинусное сходство. Косинусное сходство измеряет угол между двумя векторами и возвращает реальное значение от -1 до 1.
Если векторы имеют только положительные значения, как в нашем случае, выходные данные фактически будут находиться между 0 и 1. Он вернет 0, когда два вектора ортогональны, то есть документы не имеют никакого сходства, и 1, когда два вектора параллельны, то есть документы полностью идентичны:
Чем ближе два вектора друг к другу, тем меньше угол между ними и, следовательно, тем больше косинус угла между ними. Два одинаковых вектора будут иметь угол 0 градусов и метрику сходства 1,0. Два ортогональных вектора будут иметь угол 90 градусов и метрику сходства 0,0.
В NLTK имеется функция nltk.cluster.util.cosine_distance(v1, v2), вычисляющая косинусное сходство, благодаря которой сравнивать документы довольно просто.
Преобразуем наш набор данных в словарь, ключи которого будут заголовками записей, а значение — сами записи. В качестве заголовков выберем из каждой строки два самых длинных слова.
Напишем программу для поиска похожих строк с использованием метрики косинусного сходства.
Начнём с того, что создадим и заполним структуру данных td_matrix таким образом, чтобы при обращении td_matrix[doc_title][term] можно было получить оценку tf_idf для слова в документе.
Теперь сконструируем векторы с оценками для одинаковых слов в одних и тех же позициях. Используя метод cosine_distance() из nltk.cluster.util вычислим величину сходства между строками. И словарь с полученными результатами запишем в файл.
Результат выполнения программы:
Расчёты заняли примерно 34 минуты. В дальнейшем можно воспользоваться файлом с сохранённым результатом. Но Делиться им я не стану по причине получившегося неожиданно большим размера.
Посмотрим, что там получилось.
Получился словарь, в котором ключ — слово или несколько слов (заголовок документа), а значение — словарь с теми же ключами и косинусными расстояниями между этим документом и всеми другими документами в наборе данных.
Посмотрим как формируются векторы и вычисляется косинусное расстояние внутри цикла.
Для визуализации сходства документов можно использовать графоподобные структуры, где связи между документами кодируют меру сходства между ними.
Выберем 25 случайных ключей из словаря distances.
Создадим матрицу сходства документов. В каждой её ячейке (i, j) будет сохраняться разность между 1,0 и косинусным сходством между документами i и j.
Визуализируем матрицу косинусного сходства с помощью метода imshow() из библиотеки matplotlib.
В результате выполнения этого кода создаётся рисунок, на котором отображена матрица косинусного сходства между выбранными документами. Цвета на рисунке соответствуют величине косинусного сходства: светлее цвет — выше сходство.
Словарь сравнений всех строк со всеми на основе косинусного сходства получился довольно разрежённым — большая часть значений являются дублирующимися записями заголовков строк которые не имеют между собой ничего общего (расстояние равно 1.0). Отфильтруем такие записи и запишем результат в новый файл.
В результате размер файла словаря уменьшился в 20 раз.
Скачать его можно отсюда.
https://disk.yandex.ru/d/zqJoYRmnKy1U9g
Загрузим отфильтрованный словарь и продолжим эксперименты с матричными диаграммами.
Результат выполнения программы:
Создав словарь косинусных расстояний для набора данных у нас по-сути оказался набор кластеров, в которые записи сгруппированы по степени их сходства. И получен он за 34 минуты, что оказалось примерно в 12 раз быстрее, чем это происходило в примере жадной кластеризации на основе расстояния Жаккара.
Посмотрим какие строки из набора данных группируются под заголовками — ключами словаря distances. Для этого нам понадобится словарь индексов, где ключами будут те же заголовки, а значениями — индексы строк в наборе данных, к которым эти заголовки относятся. Доработаем написанный ранее код, чтобы добавить этот словарь.
Теперь выведем, например, что оказалось в кластере «спутник помощь».
Результат выполнения программы:
Чем меньше расстояние между строкой, ставшей основой кластера и сравниваемой с ней строкой, тем более похожи эти строки. В конце списка расположились строки наиболее далёкие друг от друга из тех, между которыми есть хотя бы немного сходства (расстояние близко к 1.0).
Посмотрим, что попало в кластер «пытаться доказать»
Комбинируя заголовок кластера с заголовком строки так, чтобы в новый заголовок вошли слова, которые есть только в одном из заголовков и сопоставляя его с этой строкой, можно установить связь этих дополнительных слов с изменениями в строке.
Например, «пытаться доказать» порождает строку, «Он пытается доказать своим соседям»
А комбинация «пытаться доказать» и «доказать историк» даёт новый заголовок «пытаться доказать историк», который порождает строку: «когда историк хочет доказать свою».
Ещё примеры:
«пытаться доказать» и «справедливость доказать» => «пытаться доказать справедливость» => «Таким образом была доказана справедливость»;
«пытаться доказать» и «следовательно удаться» => «пытаться доказать следовательно удаться» => «Следовательно, если соседу удастся убедить»;
«пытаться доказать» и «например директор» => «пытаться доказать например директор» => «Например, директора пытаются убедить клиентов».
TF-IDF — мощный и простой в использовании инструмент. Однако, применяя анализ n-грамм для учёта словосочетаний и порядка следования слов, мы сталкиваемся с проблемой, когда TF-IDF приписывает одинаковый смысл всем одинаковым лексемам. Однако в действительности это далеко не так. Омонимы — это слова, одинаковые по написанию и произношению, но разные по значению, смысл которых определяется контекстом. Такие примеры омонимов, как ключ (для замка или родник), балка (часть конструкции или участок местности), глажу (бельё или животное), ручка (двери или пишущая) точка (в предложении или на карте) и т. д., наглядно показывают важность контекста для определения смысла слов.
Косинусное сходство страдает практически теми же недостатками, что и TF-IDF. Оно не учитывает ни контекст документа, ни порядок слов в n-граммах и предполагает сходство слов, находящихся близко друг другу в векторном пространстве, что, конечно же, не всегда верно. Конкретно в рассмотренной реализации косинусного сходства для оценки относительной важности слов в документах также применялся TF-IDF, из-за чего ей свойственны все недостатки TF-IDF.
Существуют другие методы, которые в большей мере зависят от контекста и глубже погружаются в семантику данных на человеческом языке.
Основная идея NLP заключается в том, чтобы взять документ, состоящий из упорядоченной коллекции символов, следующих правилам синтаксиса и грамматики, и определить семантику, связанную с этими символами.
Анализ контекста естественного языка — сложная задача, при решении которой требуется учитывать множество казалось бы незначительных мелочей. Например, функция split(), используемая для разбиения текста на лексемы, оставляет знаки препинания в составе лексем, что сказывается на точности подсчёта частот. Такие простые знаки препинания, как точка, сигнализирующая о конце предложения, образуют контекст, который легко распознаётся нашим мозгом, но компьютеру намного сложнее добиться такого же уровня сходства.
Нам не составит особого труда выделять такие части документа как предложения, но машине нужен сложный и подробный набор инструкций, чтобы решить эту задачу.
Первой попыткой решить эту задачу мог бы стать простой поиск в тексте точек, восклицательного и вопросительного знаков. Однако данный способ обладает потенциальной погрешностью, если в тексте встречаются лексемы вроде т. к., т. д., т. е.
Даже обладая полнотой информации о структуре предложения, часто требуется дополнительный контекст, окружающий предложение, чтобы правильно его интерпретировать. Нужно как-то научить машину правильно выделять ключевые части текста.
Конвейер NLP с использованием NLTK включает следующие шаги:
- Определение концов предложений.
- Лексемизация.
- Маркировка частей речи.
- Объединение.
- Извлечение.
Преобразовать текст в коллекцию предложений можно с помощью метода nltk.tokenize.sent_tokenize().
Лексемизации подвергаются уже отдельные предложения.
На этапе маркировки частей речи каждой лексеме присваивается метка, определяющая её часть речи (Part-Of-Speech, POS).
Вот список сокращений, которые могут возвращаться методом nltk.pos_tag():
CC — координирующая конъюнкция; CD — кардинальная цифра; DT — определитель; FW — иностранное слово; IN — предлог/подчинительный союз; JJ — прилагательное; JJR — прилагательное, сравнительная степень; JJS — прилагательное, превосходная степень; LS — маркер списка; MD — модальный; NN — существительное в единственном числе; NNS — существительное во множественном числе; NNP — существительное собственное в единственном числе; NNPS — существительное собственное во множественном числе; PDT — предопределитель; PRP — личное местоимение родителя; PRP$ — притяжательное местоимение; RB — наречие; RBR — наречие, сравнительная степень; RBS — наречие, превосходная степень; RP — частица; OT — междометие; VB — глагол, базовая форма; VBD — глагол, прошедшее время; VBG — глагол, деепричастие/причастие настоящего времени; VBN — глагол, причастие прошедшего времени; VBP — глагол настоящее время; VBD — глагол, прошедшее время; VBG — глагол, деепричастие/причастие настоящего времени; VBN — глагол, причастие прошедшего времени; VBZ — глагол от третьего лица, настоящее время.
Похоже, что nltk.pos_tag() не корректно маркирует части речи в текстах на русском языке.
Например, [('Эта', 'JJ'), ('особенность', 'NNP'), ('человеческого', 'NNP'), ('сознания', 'NNP'), ('позволяет', 'NNP'), ('.', '.')], слово «позволяет» должно маркироваться как VB, а не NNP.
Попробуем поручить эту работу другой библиотеке — pymorphy2. Этот инструмент предназначен для морфологического анализа слов русского языка в Python. Библиотека позволяет выполнять разбор слова на его составляющие (например, определение части речи, падежа, числа и т. д.) и склонение слов в различные формы.
Для начала нужно установить эту библиотеку, выполнив команду в терминале:
pip install pymorphy2
Обозначения частей речи взяты из документации к библиотеке pymorphy2 отсюда.
В этот раз получилось значительно лучше, слово «позволяет» промаркировано как VERB, т. е. глагол, что правильно.
Теперь, проведя разметку текста частями речи можно выделить из текста словосочетания по-новому. Например, такие как существительное — полное прилагательное.
Сохраним результаты поиска таких словосочетаний по всему набору данных в файл.
Аналогичным образом выделим и сохраним другие словосочетания:
Ну и некоторые другие комбинации одним махом.
Скачать всё это добро одним файлом можно отсюда.
Сборка составных лексем, выражающих логические понятия — совершенно иной подход к определению словосочетаний, отличный от статистического анализа. Для объединения фрагментов текста и их маркировки как именованных сущностей в nltk имеется специальная функция nltk.chunk.ne_chunk_sents(). Но, т. к. обнаружилось, что тексты на русском языке он тегирует неправильно, придётся использовать другие инструменты. Поможет нам в этом, как подсказывает Алиса из Яндекса, уже известный по задачам лемматизации инструмент — Natasha.
Вообще, этот пакет решает следующие задачи обработки естественного языка:
- сегментация текста на токены и предложения;
- морфологический и синтаксический анализ;
- лемматизация;
- извлечение именованных сущностей.
Посмотрим на структуры данных.
Чтобы сформировать список из всех извлечённых из строки именованных сущностей, можно обратиться к doc.spans:
Выведем все именованные сущности из нашего набора данных.
Сохраним результаты этого вывода в файл формата JSON. Это текстовый формат обмена данными, основанный на JavaSctipt (JS). Но при этом формат независим от JS и может испльзоваться в любом языке программирования. Его часто используют чтобы сохранить данные для машинного обучения. По структуре он похож на словари python вида ключ-значение, например:
{
"query": "Виктор Иван",
"count": 7
}
JSON-объект — это неупорядоченное множество пар «ключ:значение».
В качестве значения может быть не только строка или число. Это может быть и другой объект. Например:
{ "value": "Иванов Виктор", "unrestricted_value": "Иванов Виктор", "data": { "surname": "Иванов", "name": "Виктор", "patronymic": null, "gender": "MALE" } } В Python имеется библиотека json для работы с этим форматом.
Преобразуем извлечённые именованные сущности в нормальную форму, затем каждую просклоняем по падежам и составим словарь, в котором ключи — нормальная форма именованной сущности, а значения — словари её склонений. Этот словарь и запишем в файл json.
Как видно, записи в файле хранятся в кодировке UTF в виде escape-последовательностей.
Можно хранить и в ASCII как текст.
Скачать этот файл можно отсюда.
Частотный и морфологический анализ, тегирование и именованные сущности могут пригодиться при подготовке данных для машинного обучения. Одним из важнейших этапов в этом деле является проектирование признаков (feature engineering) - преобразование всей касающейся задачи информации в числа, пригодные для построения матрицы признаков. При этом важно преобразовать текст в набор репрезентативных числовых значений.
Один из простейших методов кодирования данных — по количеству слов: для каждого фрагмента текста подсчитывается количество вхождений в него каждого из слов, после чего результаты помещаются в таблицу.
Для векторизации текста на основе числа слов можно создать столбцы, соответствующие словам из набора данных, в которые помещать количество вхождений каждого из слов в тексте. Получится разрежённая матрица.
У такого подхода есть недостаток: слишком часто встречающиеся слова получат слишком большое значение, что может помешать правильной классификации текста. Эту проблему можно решить, используя TF-IDF. При нём слова получают вес с учётом частоты их появления во всех документах.
Другой недостаток такого подхода — размер вектора получается равным размеру словаря, в то же время лишь малая его часть действительно будет задействована при преобразовании отдельного текста (большинство значений будут равны нулю). Поэтому более сложные подходы машинного обучения опираются на представление текстов в виде плотных векторов.
Плотные векторы (эмбеддинги) — это представление слов или текстовых фрагментов виде числовых векторов, где каждый элемент представляет какую-нибудь смысловую (семантическую) характеристику. Такие векторы содержит значительно меньше значений, чем длинна словаря, но большая их часть не нулевые. И они позволяют лучше выполнять такие операции как поиск похожих текстов на основе косинусного сходства между векторами.
Ещё один удобный тип признаков — выведенные математически из каких-либо входных признаков. Например, линейную регрессию можно преобразовать в полиномиальную регрессию путём преобразования входных данных. Этот метод называется регрессией по комбинации базисных функций. Пример можно посмотреть в одной из предыдущих статей.
Подробнее эмбеддинги будут рассмотрены в следующей статье, а пока что посмотрим, что ещё можно сделать с текстами, имея уже освоенный инструментарий.
Можно, например, составлять аннотации текстов методом Луна. Основные шаги, которые нужно пройти, чтобы обобщить текст таким способом:
1. Предварительная обработка текста:
- импортировать необходимые библиотеки;
- разделить текст на предложения;
- разделить каждое предложение на отдельные слова;
- привести слова к нижнему регистру и удалить стоп-слова;
- провести лемматизацию слов.
2. Вычисление важности слов:
- создать словарь, в котором ключами будут слова, а значениями — их частота в тексте;
- вычислить вес каждого слова, используя формулу Х.П. Луна: weight = (1+ log(frequency)) * log(N / (1 + df)), где frequency — частота лова в тексте, N — общее количество слов втексте, df — количество предложений, содержащих данное слово;
- отсортировать слова по их весу в порядке убывания.
3. Генерация аннотации:
- выбрать N наиболее важных слов из отсортированного списка;
- сформировать аннотацию, объединив выбранные слова в предложение.
В качестве текста, который будем аннотировать возьмём одну из галлюцинаций LLM RuGPT2-large, которую можно загрузить отсюда.
Продолжение:
Результат выполнения программы:
Из такой аннотации мало что можно понять об исходном тексте.
Но эту программу можно улучшить если добавить кластеризацию и работать на уровне предложений а не только отдельных слов. Тогда можно отбросить неважные предложения, используя как фильтр среднюю оценку плюс долю стандартного отклонения.
Продолжение.
Продолжение
Результат выполнения программы:
Это уже намного лучше. По крайней мере из такой аннотации можно понять о чём текст.
Алгоритм Луна основывается на предположении, что важные предложения в документе содержат слова, встречающиеся наиболее часто. Однако есть несколько тонкостей, которые следует отметить. Во-первых, не все часто встречающиеся слова важны; стоп-слова, к примеру, едва-ли представляют интерес для анализа. Отфильтровывая дополнительные стоп-слова, характерные для конкретного набора данных, можно повысить эффективность этого алгоритма. Также можно получить интересные результаты, если внедрить метрику TF-IDF в функцию оценки для конкретного источника данных, чтобы определить наиболее общие слова для данной области.
Следующим шагом является извлечение N наиболее важных слов. Алгоритм из двух любых предложений в документе выберет то, которое содержит больше этих слов. Оценка предложений осуществляется функцией score_sentences. Из отобранных таким образом предложений и получается реферат текста.
Для оценки предложений функция score_sentences объединяет лексемы в кластеры, применяя простую метрику порогового расстояния, и оценивает каждый кластер по следующей формуле:
За оценку всего предложения принимается наибольшая из оценок кластеров, выявленных в этом предложении.
Функция score_sentences просто выполняет рутинные операции, выявляя кластеры в предложении. Кластер определяется как последовательность, содержащая два или более важных слова, при этом каждое важное слово находится от ближайшего соседа не дальше порогового расстояния.
После оценки всех предложений остаётся только определить, какие из них следует включить в обощённую версию. Первый подход основан на фильтрации предложений по статистическому порогу, для чего вычисляются среднее и стандартное отклонение полученных оценок, а второй — просто возвращает N предложений с наибольшими оценками.
Алгоритм Луна прост в реализации и основан на предположении, что часто встречающиеся слова в документе являются наиболее описательными для него. Однако этот алгоритм, как и другие, основанные на идеях классического информационного поиска, сам по себе не пытается проанализировать данные на более глубоком, семантическом уровне, даже при том, что использует не только идею «мешка слов». Он напрямую определяет обобщения как функцию от часто встречающихся слов и использует не очень сложный метод оценки предложений, но (как и в случае с TF-IDF) тем удивительнее, насколько хорошо он справляется с произвольно выбранными данными.
При подготовке статьи были использованы следующие материалы:
1. М. Рассел, М. Классен "Data Mining", с. 208 -304
2. Дж. Вандер Плас "Python для сложных задач", с. 427 - 430
5. Natasha: инструмент для извлечения именованных сущностей из русских текстов.
6. Можно всё: решение NLP задач при помощи spacy.
7. Инструментарий естественного языка - объединение тегеров.
8. Как SentencePiece токенизирует русскоязычный текст.
9. How to process textual data using TF-IDF in Python.
10. Извлечение признаков из текстовых данных с использованием TF-IDF.
11. Python | Remove punctuation from string.
12. Семантический поиск: от простого сходства Жаккара к сложному SBERT.
13. How to Compute the Similarity Between Two Text Documents?
14. Питонистический подход к циклам for: range() и enumerate().
15. Получение всех ключей из словаря в Python.
16. Python: получаем максимальный элемент списка, словаря или кортежа.