"Поэзия — та же добыча радия.
В грамм добыча, в год труды.
Изводишь единого слова ради
тысячи тонн словесной руды.
Но как испепеляюще слов этих жжение
рядом с тлением слова-сырца.
Эти слова приводят в движение
тысячи лет миллионов сердца".
(C) Маяковский

Датамайнинг текстов - это процесс обнаружения значимых закономерностей в текстовых данных. Он включает в себя извлечение информации, её структурирование, анализ и визуализацию результатов.
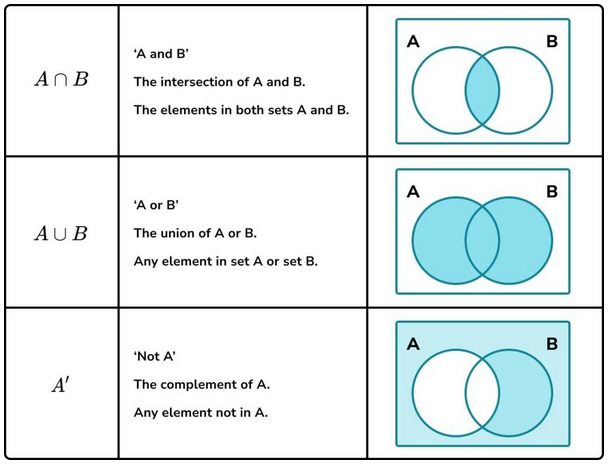
Простейшие методы анализа текстов опираются на теорию множеств. В языке Python множество - это структуры данных, в которой хранится неупорядоченная коллекция уникальных элементов. К ним применимы операции с участием других множеств элементов. Например, операция пересечения двух множеств вернёт общие элементы, одновременно присутствующие в обоих множествах; операция объединения вернёт все элементы из двух множеств, а операция разности двух множеств действует подобно операции вычитания, когда элементы одного множества удаляются из другого.
У меня есть набор данных, «Peyote» общим объёмом 300 Мб (30 тыс. страниц текста) — это галлюцинации языковой модели Sber_rugpt2large. Небольшая выборка из него — 10 тыс. фрагментов, каждый длиной 5 слов, послужит нам материалом для опытов по рассматриваемой теме.
Скачать эту выборку можно здесь.
Поместим файл pieces.txt в каталог с проектом и загрузим образцы в список:
Каждый элемент списка — слово из набора данных, отделённое от других слов пробелом. Разными словами также считаются слова с заглавной и прописной буквы, а также слова, заканчивающиеся знаком препинания, и даже состоящие из одного символа, например «и», «а» или «-». Поскольку в записях могут встречаться одни и те же слова, в списке будет большое количество повторов. Их можно исключить, преобразовав список в множество. Таким образом получится словарь для выбранного набора данных.
Преобразуем две записи списка в разные множества и выполним над ними различные операции.
С помощью операции пересечения (intersection) можно найти, какие слова являются общими для обоих множеств.
Этот приём можно применить для сортировки записей по количеству в них общих слов.
Всего 1032548 сопоставлений в которых хотя бы одно слово является общим. Те сопоставления, в которых все 5 слов общие — дубли и их из набора данных можно спокойно удалить. А дальше при уменьшении совпадения от 4 до 1 записи всё более отличаются друг от друга. Выведем для сравнения несколько записей с частичным совпадением слов. Для этого нас пригодятся индексы, записанные при сопоставлении.
Эти записи действительно оказались довольно близкими друг другу.
Убедимся что записи с 5 совпадающими словами действительно дубли, а не образцы с одинаковым набором слов но их разным расположением.
Удалим дубли и запишем обновлённый список в файл pieces_dedup.txt, чтобы каждый раз не повторять эти вычисления.
Скачать можно отсюда.
На моём компьютере процесс сопоставления занимает примерно 2 минуты и терять их всякий раз при запуске программы слишком расточительно.
Теперь снова проверим, нет ли дублей в этом файле.
Операция над множествами, обратная пересечению, называется симметричной разницей. Она даёт все элементы, которые не принадлежат одновременно обоим исходным множествам. Для нахождения симметричной разности множеств используется метод symmetric_difference().
Объединить множества можно с помощью метода union(). В результате объединения получится новое множество, состоящее из всех элементов обоих множеств.
Множество — изменяемая коллекция данных. Добавить новый элемент можно с помощью метода add(), а удалить с помощью метода discard(). Для очистки всего множества предусмотрен метод clear(). Добавить в множество сразу несколько элементов позволяет метод update(). Посмотреть все доступные методы для работы с множеством можно с помощью команды dir().
Методы, начинающиеся на is служат для проверки на соответствие определённым условиям.
Например, issubset() позволяет узнать, является ли одно множество подмножеством другого множества. А метод isdisjoint() позволяет проверить, имеют ли множества общие элементы, если не имеют — то они называются непересекающимеся.
Отправной точкой почти для всех видов анализа является подсчёт элементов на некотором уровне. В Python имеется модуль сollections с классом Counter, который упрощает вычисление частот элементов в коллекциях данных.
Для примера осуществим частотный анализ нашего набора данных, чтобы получить словарь с парами ключ/значение, где ключи соответствуют словам, а значения — их частотам.
В этом примере мы объединяем все строки в dataset в одну строку, разделяем ее на слова с помощью метода split(), а затем используем класс Counter для подсчета частоты каждого слова.
Отметим, что таким способом мы также получили набор уникальных слов идентичный тому, который был получен с помощью множества.
Оформим результат частотного анализа в виде таблицы с помощью пакета prettytable, который необходимо предварительно установить с помощью команды pip install prettytable.
Немного более продвинуты анализом, который включает вычисление частот и может применяться к неструктурированному тексту, является оценка лексического разнообразия. Эта мера показывает, насколько текст богат различными словами и выражениями. Математически эта оценка выражается отношением числа уникальных слов к общему числу слов в тексте.
Для расчёта лексического разнообразия текста с помощью Python можно использовать библиотеку ntlk. Она содержит богатый набор инструментов анализа текста, включая его разбивку на отдельные части (текенизацию), исключение слов не несущих смысловой нагрузки, подсчёт уникальных слов и многое другое. Она также предоставляет доступ к корпусам текста и ресурсам, которые могут быть полезны при анализе текста.
Сначала этот пакет нужно установить: pip install nltk.
Затем воспользоваться его встроенным загрузчиком чтобы подтащить из сети необходимые данные. В Ubuntu Linux нужно открыть консоль (Ctrl+Alt+T) и создать каталог /usr/share/nltk_data, а затем ввести команду:
python -m nltk.downloader -d /usr/share/nltk_data all
Теперь можно приступать к написанию программы. Импортируем библиотеку nltk, а также список стоп-слов (stopwords). Эти слова являются общеупотребительными в языке (например, «и», «в», «на»). Их удаление позволяет сократить объём данных для анализа и сосредоточиться на более значимых словах, что повышает точность и эффективность обработки текста.
Токенизируем текст, передав его методу nltk.word_tokenize(). И удалим из него стоп-слова с помощью генератора списка.
Общий вид такого генератора: [выражение for переменная in список], где переменная — идентификатор переменной, список — список значений, который принимает переменная, а выражение — то,чем будут заполнены элементы списка. Затем мы определяем уникальные слова в тексте, преобразовав список токенов в множество и вычисляем отношение количества уникальных слов к общему количеству слов. Это соотношение принято называть TTR (type-token ratio).
Можно интерпретировать полученный результат так, что примерно 24% текста каждого образца содержат уникальную информацию.
Одним из фундаментальных методов анализа данных является кластеризация. С помощью кластеризации набор элементов разделяют на подгруппы (кластеры) так, чтобы в каждой подгруппе были максимально похожие друг на друга элементы и минимально похожие на элементы из других подгрупп.
Нормализация данных и определение сходства — это две главные темы, с которыми приходится сталкиваться в кластеризации. Третья часто встречающаяся тема при данной работе — сокращение размерности. Для группировки элементов в множестве с использованием метрики сходства в идеале желательно сравнить каждый элемент с каждым другим элементом. В этом случае, при наихудшем развитии событий, для множества из n элементов вам придётся вычислить степень сходства примерно n^2 раз. В информатике эту ситуацию называют проблемой квадратичной сложности и обычно обозначают O(n^2). Уменьшение размерности предусматривает использование функции для организации «достаточно похожих» элементов в фиксированное число групп, чтобы элементы в каждой группе можно было в полной мере считать похожими.
Под нормализацией подразумевается приведение данных к более простому и унифицированному виду. В зависимости от решаемых задач это может быть приведение текста к нижнему регистру, удаление знаков препинания, слов не несущих значительной информационной нагрузки (стоп-слов), удаление токенов, которые появляются выше или ниже определенного порогового значения.
Два основных метода нормализации текста: стемминг и лемматизация.
Стемминг использует ряд правил для разделения строки на меньшие подстроки. Цель состоит в том, чтобы удалить аффиксы слов, которые изменяют значение. Аффикс — часть слова (морфема), которая присоединяется к корню. Примеры: передел — «пере» является аффиксом (приставкой), самолёт - «о» является аффиксом (интерфикс), задерживаемся- «ся» является аффиксом(постфикс).
Лемматизация использует словарь для поиска каждого токена и возвращает каноническое «головное» слово в словаре, называемое леммой. Например, «пытался» превращается в «пытаться», «плачет» в «плачу», «машины» в «машина» и т. д. Таким образом, все такие слова, как «пытался», «пытается» и «пытаться», будут рассматривается системой как несколько экземпляров одного и того же слова: «попробуй».
Удалить знаки препинания и специальные символы можно с использованием модуля обработки регулярных выражений:
text = re.sub('[^A-Za-zА-Яа-я0-9]+', ' ', text)
Перевести в нижний регистр и удалить стоп-слова:
text = ' '. join(e.lower() for e in text.split() if e.lower() not in stopwords)
Выполнить стемминг можно следующим образом:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
text=dataset[0]
tokens=word_tokenize(text)
stemmed_words=[stemmer.stem(word) for word in tokens]
print(stemmed_words)
Этот пример корректно работает с текстами на английском языке. Для русскоязычных текстом нужен другой стеммер -SnowballStemmer.
Лемматизация более точно обрабатывает слова, приводя их к словарной форме. Но NLTK не предоставляет прямой лемматизатор для русского языка. Поэтому для лемматизации русских текстов можно использовать стеммер, либо применить другие библиотеки.
Вместо NLTK для лемматизации русских слов вы можете использовать следующие библиотеки Python:
- Natasha: токенизация, морфологический анализ, лемматизация, синтаксический анализ и извлечение именованных сущностей.
- DeepPavlov: готовые модели NLP для классификации текстов, распознавания именованных сущностей и систем ответов на вопросы, основанные на технологии BERT.
- PyMorphy2: морфологический анализ текстов с использованием словарей OpenCorpora.
Попробуем применить Natasha. Для этого откроем терминал (Ctrl+Alt+T) и выполним команду установки библиотек:
pip install natasha yargy
Теперь можно приступать к написанию программы для лемматизации текста:
Лемматизируем все строки набора данных и запишем их в отдельный файл.
Скачать этот файл можно отсюда:
При нормализации, как видно, теряется часть информации. Поэтому в её применении нет однозначных и универсальных правил, нужно применять тот или иной подход сообразно решаемой задаче.
Основной этап перед кластеризацией набора строк — измерение степени их сходства. Здесь также существуют различные подходы, имеющие свои преимущества и недостатки. Рассмотрим некоторые из них.
1. Редакционное расстояние (расстояние Левенштейна).
Это минимальное количество операций вставок, удалений и замен, необходимое для преобразования одной строки в другую. Например, для преобразования «Биба» в «Боба» требуется одна операция замены (буквы и на о), в результате редакционное расстояние между этими двумя словами равно 1. NLTK включает реализацию алгоритма редакционного расстояния в виде функции ntlk.distance.edit_distance(s1, s2, substitution_cost=1, transpositions=False).
Расстояние Левенштейна активно используется для исправления ошибок в словах, поиска дубликатов текстов, и прочих операций с символьными последовательностями.
Также nltk позволяет вычислить модифицированную метрику — расстояние Дамерау-Левенштайна, в котором добавлена операция перестановки символов. Для этого достаточно изменить параметр transpositions с False на True.
Редакционное расстояние можно вычислять и имея на входе списки слов вместо строк. Для этого сначала нужно установить дополнительную библиотеку:
pip install editdistance
2. Сходство n-грамм
Это простой способ представления текста в виде последовательности всех возможных групп из n лексем. Этот способ обеспечивает основу для подсчёта словосочетаний. Существует много вариантов вычисления сходства с применением n-грамм. Наиболее простые — деление двух строк на последовательности биграмм (2-грамм) и оценка сходства путём подсчёта общих биграмм в них.
Именованные аргументы pad_right и pad_left позволяет организовать сопоставление начальных и конечных слов в названиях по отдельности. Благодаря им в наборы будут включены такие биграммы, как (None, 'Поэтому') и ('иметь', None). В NLTK имеется довольно полный набор функций оценки биграмм и триграмм (3-грамм), организованных в классы BigramAssociationMeasures и TrigramAssociationMeasures, в модуле nltk.metrics.association.
Они зачастую используются для обнаружения словосочетаний (коллокаций).
Коллокации — это два или более слова, которые часто встречаются вместе, например Ленинградская область. Как и во многих аспектах естественного языка, при обработке словосочетаний важен контекст. В задачах выявления словосочетаний контекстом является документ в виде списка слов.
BigramCollocationFinder строит два распределения частот: по одному для каждого слова и ещё одно для биграмм. Распределение частот, или FreqDist в NLTK, по сути представляет собой расширенный словарь, в котором ключи — это то, что подсчитывается, а значения — это содержание того, что подсчитывается. Любые применяемые фильтрации уменьшают размер этих двух FreqDist на число слов, не прошедших фильтр. Удаляя все слова, состоящие из одного или двух символов, а также стоп-слова русского языка, мы получаем гораздо более чистую информацию.
Вместо биграмм можно найти триграммы.
Помимо фильтра стоп-слов мы также применили частотный фильтр apply_freq_filter(3), который удалил все триграммы, встретившиеся менее трёх раз.
3. Расстояние Жаккара
Часто сходство можно вычислить как сходство двух множеств. Такая метрика называется сходством Жаккара. Она определяется как отношение пересечения множеств к их объединению.
Учитывая, что метрика сходства Жаккара измеряет близость двух множеств, их несходство можно измерить, вычитая это значение из 1,0 и получить оценку, известную как расстояние Жаккара.
Результат выполнения программы:
Здесь можно обратить внимание на то, что в первой и третьей строке есть два общих слова — «черные» и «обезьяны», но алгоритм, судя по результату обнаружил только одно общее слово - «черные». Второе для него разные потому, что в первой строке к слову обезьяны прилипла ещё и запятая и это воспринимается уже как совсем другое слово. Вот почему важно предварительно должным образом очистить текст от всего лишнего.
Повысить чувствительность сравнения текстов можно с помощью шинглов (w-shingling), также известных как n-граммы. Идея заключается в том, чтобы представить текст как последовательность из n идуших подряд в тексте элементов, посимвольно или пословно.
Результат выполнения программы:
Алгоритмы кластеризации.
1. Жадная кластеризация
Это алгоритм кластеризации, который стремится максимизировать локальную плотность объектов при построении кластеров. Он начинает с одного объекта и последовательно добавляет кластеры, каждый раз выбирая объект с наибольшей плотностью и добавляя его в ближайший кластер. Этот процесс продолжается до тех пор, пока не будут учтены все объекты. Цель этого процесса — максимизировать суммарное сходство между объектами одного кластера и минимизировать суммарное сходство между объектами разных кластеров.
Жадная кластеризация (или иерархическая кластеризация с единым связыванием) начинается с состояния, когда каждый элемент является отдельным кластером. Каждый шаг объединяет две ближайшие друг другу кластера. Жадность заключается в том, что элемент добавляется в первый подходящий кластер и не предпринимается попыток проверить наличие другого кластера с лучшим соответствием.
Алгоритм жадной кластеризации строк выглядит следующим образом:
- Вычислить матрицу расстояний между всеми парами строк с помощью меры расстояния Жаккара.
- Найти пару строк с наименьшим расстоянием и объединить их в один кластер.
- Обновить матрицу расстояний, заменив расстояния от каждой из двух объединённых строк до всех других строк на минимальное из этих двух расстояний
- Повторять шаги 2 и 3 до тех пор, пока все строки не будут объединены в один кластер.
Результатом будет древовидная структура, в которой каждый узел соответствует кластеру, а рёбра соединяют ближайшие кластеры. Высота ребра соответствует расстоянию между кластерами. Чтобы получить конечное разбиение на кластеры, можно «срезать» древо на заданной высоте, либо использовать более сложные критерии для выбора границы между кластерами.
Напишем часть кода, удовлетворяющую пункту 1.1. Для этого создадим структуру clusters, представляющую собой двумерный список. Каждая строка будет содержать поля: расстояние Жаккара между двумя строками, индекс первой строки в наборе данных, индекс второй строки в наборе данных, общие слова в этих строках (их можно использовать в названии кластера). Отсортировав данный список в порядке возрастания мы и получим первой записью пару строк с наименьшим расстоянием.
Результат выполнения программы.
Применим этот подход к всему набору данных и сохраним результаты в файл.
Результат выполнения программы:
Получился файл из 437873 записей общим размером 18 Мб. Его можно скачать отсюда:
для дальнейшей работы и я рекомендую так и сделать, а не заниматься самостоятельными вычислениями, потому что этот процесс может весьма затянуться (мой компьютер закончил эту работу почти за 9 часов.)
Прежде чем приступить к выполнению пункта 1.2 алгоритма жадной кластеризации подготовим список уникальных заголовков кластеров. Он нам понадобится для объединения похожих пар строк.
Из 437837 заголовков получилось 6607 уникальных.
Теперь у нас есть всё, чтобы реализовать пункты 1.2, 1.3 и 1.4
Результат выполнения программы:
Посмотрим что вошло в кластер «мелкие»:
Сохраним результат кластеризации в файл с помощью библиотеки pickle.
Загрузить его можно отсюда:
Подход с вложенным циклом, попарно сравнивающим все имеющиеся элементы, плохо масштабируется на случаи с большим значением n элементов (т. к. имеет квадратичную временную сложность O(n^2)). Чтобы справиться с проблемой нужно придумать новый алгоритм, имеющий сложность O(k x n), где k намного меньше n и представляет накладные расходы, которые растут гораздо меньше чем n. Например, можно попробовать переписать вложенные циклы так, чтобы для оценки выбирались случайные экземпляры, и таким образом уменьшить число сравнений до O(k x n), где k — размер выборки. Как и в любой другой инженерной задачи, между производительностью и качеством существует определённый баланс. При малых k ухудшается качество но растёт производительность при k близких к n растёт качество но сложность также будет приближаться к O(n^2).
Другое решение — случайно разбить данные на n сегментов (где n — некоторое число, обычно меньшее или равное квадратному корню числа элементов в множестве), выполнить кластеризацию в каждом из этих сегментов, а затем, при желании, объединить результаты. Например, для множества с 1 млн. элементов алгоритму O(n^2) потребуется выполнить трлн. логических операций, но, если разбить 1 млн. элементов на 1000 сегментов по 1000 элементов в каждом, тогда для кластеризации всех отдельных сегментов потребуется только миллиард операций.
2. Иерархическая кластеризация
Это метод, который предусматривает вычисление полной матрицы расстояний между всеми элементами, а затем выполняет обход её элементов и производит кластеризацию в соответствии с минимальным порогом расстояния. Иерархическим этот подход называется потому, что в процессе обхода матрицы и кластеризации элементов создаётся древовидная структура, которая выражает относительные расстояния между элементами. Этот метод также называют агломеративным, потому что он создаёт дерево, упорядочивая отдельные элементы данных в кластеры, которые иерархически сливаются с другими кластерами, пока весь набор данных не будет кластеризован в верхней части дерева. Листья дерева представляют кластеризуемые элементы данных, а промежуточные узлы иерархически объединяют эти элементы в кластеры.
Для выполнения иерархической кластеризации может потребоваться значительно больше времени, из-за чего метод часто не подходит для больших наборов данных. Применять данный метод лучше совместно с векторизацией текста, которая будет рассмотренная позже. Сейчас же при обработке текста мы рассматриваем его как мешок слов поэтому в кластера объединяются строки близкие не по смыслу, а по мере их сходства на основе метрики расстояния Жаккара. Поскольку оно уже было вычислено для каждой пары строк в предыдущем примере, можно использовать эту метрику для иерархической кластеризации.
Результат выполнения программы:
Посмотрим что находится в каком-нибудь кластере, получив из него индексы строк исследуемого набора данных:
Результат выполнения программы:
3. Кластеризация методом k средних
В отличие от иерархической кластеризации, которая является детерминированным методом, исчерпывающим все возможности и часто дорогостоящим, с вычислительной сложностью порядка O(n^3), кластеризация методом k средних имеет меньшую сложность, около O(k x n). Даже при больших значениях k экономия получается более чем существенной.
Экономия достигается за счёт вычисления приблизительных результатов, которые всё ещё достаточно близки к истине.
Идея заключается в том, чтобы сгруппировать многомерное пространство, содержащее n точек, в k кластеров, выполнив следующую последовательность шагов:
- Выбрать k случайных точек в пространстве данных, которые будут использоваться для формирования k кластеров: K1, K2, …, Kk.
- Связать каждую из n точек с ближайшим кластером Kn, фактически выполнив k x n сравнений.
- Для каждого из k кластеров вычислить центроид — среднее значение кластера — и присвоить это значение кластеру Ki. (То есть в каждой итерации требуется вычислить «k средних»)
- Повторять шаги 2-3, пока принадлежность к кластерам продолжает изменяться. Часто сходимость наступает после относительно небольшого числа итераций.
Алгоритм k средних можно применить и к двумерному, и к 2000-мерному пространству, но на практике размерность пространства данных обычно не превышает десяти и чаще всего равна двум или трём. Для пространств с небольшим числом измерений алгоритм k средних может оказаться весьма эффективным методом кластеризации, потому что действует довольно быстро и способен давать достаточно точные результаты. Правда, при этом нужно выбрать подходящее значение для k, что не всегда просто.
Выполним пункт 1. указанного плана кластеризации.
Выполним пункт 2 плана. Сравнивать будем той же мерой расстояния Жаккара, но в этот раз лемматизированные строки, которые предварительно загрузим из файла, нормализуем и разобьём на шинглы.
Пример лемматизированных строк, выбранных в качестве начальных центров кластеризации:
Выполним нормализации выбранных строк:
Результат нормализации выбранных строк:
Связать каждую из n точек с ближайшим кластером Kn — это в нашем случае рассчитать расстояние Жаккара от каждой из выбранных случайно 35 строк до всех остальных строк в наборе и поместить в каждый из кластеров те строки, которые к нему ближе остальных.
Результаты поместим в словарь и сохраним на диск, чтобы не повторять эти вычисления каждый раз заново.
Скачать его можно отсюда:
Теперь каждую из n точек набора данных переместим в ближайший к ней (по расстоянию Жаккара) кластер.
Скачать его можно отсюда.
Выведем список кластеров и их размеры:
Посмотрим что у нас имеется в кластере 8127. Но предварительно отсортируем его элементы в порядке возрастания расстояния индексов строк до центра. Также сгруппируем индексы кластера, имеющие одинаковые расстояния.
Результат выполнения программы:
Посмотрим что это за строки:
Результат выполнения программы:
Уберём повторяющиеся строки и посмотрим что вошло в кластер 4123.
Результат выполнения программы:
Для выполнения пунктов 3 и 4 перепишем уже отлаженные части кода в виде функций.
Продолжение
Продолжение
Продолжение
Результат выполнения программы:
Продолжение:
Продолжение
Проделанное выше можно рассматривать как упражнения по программированию. В реальных практических задачах часто предпочтительнее применять готовые библиотеки, нежели пытаться написать всё с нуля.
Инструменты кластеризации есть в NLTK, scypy, scikit-learn и других пакетах.
В качестве примере возьмём библиотеку cluster, которую нужно предварительно установить:
pip install cluster
Данный пакет поддерживает как иерархическую кластеризацию, так и кластеризацию методом k средних. Последнюю и возьмём в качестве примера.
Нужные нам методы из cluster называются KmeansClustering() и getclusters(). В KmeansClustering() мы будем передавать два параметра x, выражающий индекс строки и y - её расстояние Жаккара до другой строки. В getclusters() передадим параметр, указывающий число кластеров, в которые будут сгруппированы данные.
Сначала нужно придать нашему набору данных подходящую структуру.
Результат:
Теперь у нас есть список кортежей, каждый из которых представляет собой пару x, y (индекс строки, расстояние Жаккара). Запустим кластеризацию на 4 кластера и сохраним результаты в файлы clust1, clust2, clust3 и clust4.
Результат выполнения программы:
Скачать его можно отсюда.
Выведем содержимое кластеров:
Результат выполнения программы:
Результат получился самый странный из всех приведённых выше. Сложно вообще сказать в чём заключается логика группировки данных строк в кластеры. По видимому так получилось из-за того, что в метод KmeansClustering() были переданы наборы расстояний Жаккара, полученные из предыдущего примера для выбранных случайным образом строк. Там одни и те же или близкие расстояния изначально разделялись по кластерам, а в последнем случае они все оказались в одной куче. Нужно было взять набор расстояний из примера жадной кластеризации, тогда, скорее всего, результат был бы получше.
Но в любом случае цель пощупать различные инструменты для обработки текста в этой статье достигнута. И их теперь будет легче применить в реальных задачах.
Пока что датамайнинг текста строился на основе представления текста как мешка слов. Это позволило выявлять примитивным способом тексты имеющие между собой что-то общее формально. Но есть и более сложные способы датаймайнинга, позволяющие выявлять смысловое сходство текстов. Для этого нужно перейти от мешка слов к векторным пространствам, чему и будет посвящена следующая статья.
При подготовке статьи были использованы следующие источники:
1. Мэтью Рассел, Михаил Классен "Data Mining", стр. 34-205;
2. nltk.metrics.association module;
3. Bag of tricks для разметки текстовых данных: Часть 2. Удаление дубликатов;
5. Обучение без учителя: 4 метода кластеризации данных на Python
6. Кластеризация и визуализация текстовой информации
9. Расстояние Левенштейна для чайников
10. Source code for nltk.metrics.association
11. Venn Diagram
12. Natasha solves basic NLP tasks for Russian language
15. Инструменты для решения NER-задач для русского языка
16. 12.3. Преобразование текстовых данных и работа с ними в Python
17. Готовим тексты на русском для Machine Learning с Python
18. Анализ текстовых данных с помощью NLTK и Python
19. Искусственные интеллекты OpenAI, Yndex, Mistral, LLama.