Корреляционный анализ не ограничивается простым поиском взаимосвязи между различными признаками исследуемых групп, например, между диаметром тела и диаметром ядра нейрона. Чаще всего, установленная достоверная взаимосвязь является поводом для дальнейшего диалога в программе Statisticа. Для этого нам необходимо узнать, что она нам предлагает помимо базового варианта (Quick).
В качестве примера рассмотрим таблицу с гемограммами 28 пациентов.
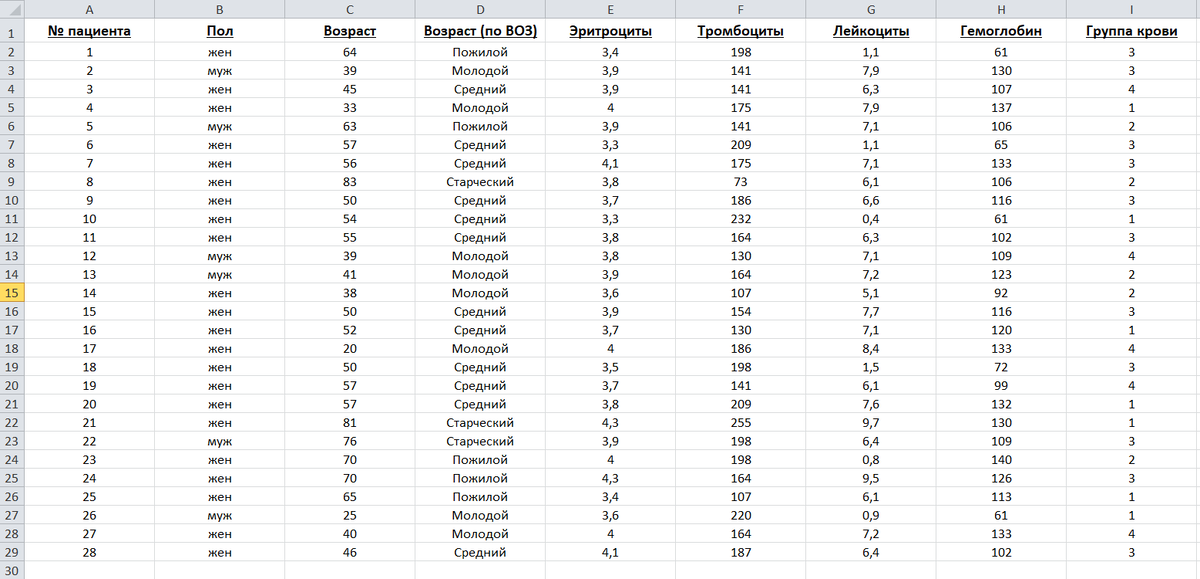
Проанализируем взаимосвязь между тремя переменными:
"Эритроциты" (столбец Е) - содержит информацию о числе эритроцитов в 10(степень12)/л крови;
"Тромбоциты" (столбец F) - содержит информацию о числе тромбоцитов в 10(степень9)/л крови;
"Гемоглобин" (столбец H) - показатель гемоглобина в крови (г/л).
Начнем с того, что запустим модуль Basic Statistics:
Выберем пункт Correlation matrices. Нажмём OK:
Мы видим диалоговое окно Correlation matrices, по умолчанию открытой на вкладке 1. Quick (Быстро):
Откроем вкладку 2. Advanced/plot (Расширенные настройки/графики):
1. Сначала, как в базовом варианте (Quick), нажмём на кнопку Summary: Correlation matrix (Результат: Корреляционная матрица).
Нам будет предложено два списка, из которых можно выбрать анализируемые переменные. Выберем "Эритроциты" и"Тромбоциты" в первом, и "Гемоглобин" во втором. Нажмём OK, и видим готовую таблицу с коэффициентами корреляции:
В корреляционной матрице приведены парные коэффициенты корреляции между выбранными переменными. Переменные "Эритроциты" и"Тромбоциты" у нас отмечены в первом столбце выбора переменных, и в итоговой таблице они также расположены в виде столбца друг под другом. Соответственно, переменная "Гемоглобин", отмеченная во втором столбце, здесь располагается в виде строки, и получается, что мы оцениваем корреляцию этой переменной с "Эритроцитами" и"Тромбоцитами" попарно. Красным цветом автоматически выделены коэффициенты значимые на уровне p<0,05. Именно на эти коэффициенты следует обратить наибольшее внимание. В нашем случае, можно отметить прямую и высокую (r = 0.77) степень взаимосвязи между содержанием эритроцитов и уровнем гемоглобина в крови. Что неудивительно:
Гемоглобин — это белок, который переносит кислород. Он находится внутри эритроцитов. Чем больше гемоглобина, тем больше кислорода может перенести кровь. Падение уровня гемоглобина или эритроцитов ниже определенного значения, порядка 110–120 г/л, называется анемией.
Корреляция между "Тромбоцитами" и уровнем гемоглобина незначима.
Теперь выйдем из модуля Basic Statistics и зайдём опять, выбрав в соответствующем диалоговом окне кнопку "Start new...":
Только теперь нажмём на кнопку "Matrix" напротив "Summary: Correlation matrix". Теперь нам предлагается один список, из которых мы выбираем "Эритроциты", "Тромбоциты" и "Гемоглобин". Нажмём OK, и перед нами - Таблица данных матрицы парных корреляции.
Эта таблица представляет собой всё те же парные коэффициенты корреляции между выбранными переменными. Только переменные "Эритроциты", "Тромбоциты" и "Гемоглобин" располагаются и в строку, и в столбик таким образом, что на пересечении двух одноимённых переменных мы видим, что r = 1, 00000, то есть, данная переменная коррелирует абсолютно с самой же собой. Получается, что каждый элемент главной диагонали нашей корреляционной матрицы равен единице, и этот момент мы отображаем отметкой 1,00000 напротив последней строки Matrix. Остальные обозначения: Means (Средние арифметические), Std.dev (Стандартные отклонения), №Cases (Объём выборки) - статистические показатели для каждой переменной.
2. Partial correlation (Частная корреляция).
Рассмотрим множественную корреляцию, когда исследуется связь между тремя и более признаками. Наиболее простой формой множественной корреляции является зависимость между тремя признаками. Применяя эти определения к текущему примеру, наши исследуемые три (для простоты) признака - это "Эритроциты", "Тромбоциты" и "Гемоглобин" из таблицы с гемограммой.
Частная корреляция - анализ взаимосвязи между двумя величинами при фиксированных значениях остальных величин. В том случае, когда имеются всего две переменные, естественной мерой зависимости является (выборочный) коэффициент корреляции между ними. А что происходит, если переменных 3 и более? Необходимо произвести корректировку. Высокое значение коэффициента корреляции между исследуемой зависимой и какой-либо независимой переменной может, как и раньше, означать высокую степень зависимости, но может быть обусловлено и другой причиной. А именно, есть третья переменная, которая оказывает сильное влияние на две первые, что и служит, в конечном счете причиной их высокой коррелированности. Поэтому возникает естественная задача найти «чистую» корреляцию между двумя переменными, исключив влияние других факторов. Исключить влияние третьей переменной позволяет частный коэффициент корреляции.
Чтобы провести анализ частных корреляций в программе Statisticа, выйдем из модуля Basic Statistics и зайдём снова уже указанным способом. Нажмём на кнопку Partial correlation:
Выбираем частные корреляции и вводим переменные.
А). Исключаем "Гемоглобин" и получаем частную корреляцию между переменными "Эритроциты" и "Тромбоциты":
Парный коэффициент корреляции между "Эритроцитами" и "Тромбоцитами" был совсем не значим (r = 0.03). Частный коэффициент корреляции между этими переменными больше, (r = 0.29), но - также незначим.
Б) Исключаем "Эритроциты" и получаем частную корреляцию между переменными "Тромбоциты" и "Гемоглобин":
Парный коэффициент корреляции между "Тромбоцитами" и "Гемоглобином" был отрицателен и не значим (r = - 0.19200). Частный коэффициент корреляции между этими переменными также отрицателен, чуть больше по величине (r = - 0.34), и - также незначим.
В). Исключаем "Тромбоциты" и получаем частную корреляцию между переменными "Эритроциты" и "Гемоглобин":
Парный коэффициент корреляции между "Эритроцитами" и "Гемоглобином" был на высоком уровне значим (r = 0.76991). Частный коэффициент корреляции чуть больше, (r = 0.79), и, разумеется также значим на высоком уровне.
Рабочее окно для ввода данных, когда мы хотим вывести Таблицу данных матрицы частных корреляций, точно такое же, как и при получении матрицы с коэффициентами корреляции (частных, при исключённых различных переменных). Чтобы получить Таблицу данных матрицы частных корреляций, нажмём на кнопку "Matrix" напротив длинной кнопки Partial correlation, выбираем, какую переменную исключаем, а между какими - оцениваем корреляцию. Нажмём OK, и видим нашу таблицу данных матрицы частных корреляций. Исключим по очереди:
А) "Гемоглобин"
Б) "Эритроциты"
В) "Тромбоциты"
Частные корреляции как инструмент анализа находят широкое применение в медицине и биологии.
Качественные изменения функций различных органов вызывают изменения функции других координированных с ним органов. Именно этот принцип лежит в основе корреляционной патологии. Так, при воздействии вредных факторов окружающей среды на организм часто первичные патологические изменения происходят лишь в пункте приложения повреждающего агента. Затем, как следствие этих изменений патологические изменения возникают в других внутренних органах, связанных с первично-измененными. И тогда мы можем наблюдать корреляцию между разными переменными, которой не существовало бы в отсутствии этого вредного фактора! Также установленные исходные корреляции подвергается существенной перестройке при формировании навыков и в принципе при осуществлении целенаправленной деятельности. Так, у систематически тренирующегося спортсмена-стрелка усиливается корреляция между зрительной чувствительностью и электрической активностью сгибателя указательного пальца правой руки. Сдвиги в исходной корреляции сопутствуют утомлению, патологическим нарушениям церебральной нейродинамики (неврозы, посттравматические состояния, эпилепсия, последствия инсультов), длительной сенсорной активации или депривации. Эти сдвиги проявляются ослаблением и извращением исходной корреляции. Пример: на фоне невроза, вызванного конфликтом пищевого и оборонительного поведения, резко ослабляется корреляция альфа-подобной активности мозговых структур, регулирующих сердечную деятельность, и целого ряда других показателей.
*В примере с анализом переменных, взятых из гемограммы пациентов, возможно, нет особого смысла рассматривать частные корреляции, так как с пациентами никто не проводил никаких манипуляций, и отсутствуют данные о наличии у них у всех какой-то патологии/воздействия вредных факторов. Анализ частных корреляций в данном случае полезно рассмотреть в учебных целях.
Последующие пункты в модуле (3 - 8) Advanced/plot (Расширенные настройки/графики) представляют собой графические методы анализа взаимосвязи между переменными. Их детальный обзор со всем многообразием опций выходит за рамки данной статьи. Поэтому ограничимся кратким перечислением того, что может тот или иной графический метод, и как им пользоваться.
3. 2D scatterplots (Двухмерная диаграмма рассеяния).
Выйдем из модуля Basic Statistics и туда зайдём снова. Нажмём на кнопку "2D scatterplots". В рабочем окне для ввода данных укажем "Эритроциты" и "Гемоглобин", тем более, что методом парных и частных корреляций мы установили их тесную взаимосвязь. Нажмём OK, и видим двухмерную диаграмму рассеяния.
Двухмерная диаграмма рассеяния представляет собой прямую регрессии с точками, каждая из которых соответствует паре переменных Х ("Эритроциты") и Y ("Гемоглобин"). Об этом же нам сообщает заглавная строка Эритроциты vs. Гемоглобин.
Эта прямая регрессии описывается уравнением прямой:
Гемоглобин = -162.0 + 71.005 * Эритроциты.
Коэффициент корреляции между "Эритроцитами" и "Гемоглобином" (r = 0.76991) - такой же, как и при расчёте парных корреляций. Так и есть, ведь мы исходно сами выбирали пару анализируемых переменных. Чтобы получить двухмерную диаграмму рассеяния для частных корреляций двух переменных при фиксированной третьей, необходимо не покидать анализ Partial correlation, а просто нажать кнопку 2D scatterplots при уже выбранных анализируемых/фиксированных переменных.
... если нам потребовалось указать для каждой точки номер её пары координат (в данном случае, номер пациента), то мы можем воспользоваться кнопкой with casenames напротив 2D scatterplots. В результате получим такое:
4. 3D scatterplots (Трёхмерная диаграмма рассеяния).
Выйдем из модуля Basic Statistics и зайдём снова. Нажмём на кнопку "3D scatterplots". В рабочем окне для ввода данных укажем "Гемоглобин" (ось Х), "Тромбоциты" (ось Y) и "Эритроциты" (ось Z, высота). Нажмём OK, и получаем трёххмерную диаграмму рассеяния.
Так же, как и для 2D scatterplots, для каждой точки можно указать соответствующий номер пациента при помощи кнопки with casenames. Результат:
5. Scatterplot matrix (Матрица диаграмм рассеяния).
Выйдем из модуля Basic Statistics и снова туда зайдём. Нажмём на кнопку Scatterplot matrix. Перед нами - стандартные корреляционные поля для выбранных переменных.
Для каждой переменной - "Эритроциты", "Тромбоциты" (сверху, сторока) и "Гемоглобин" (столбец) приведены приведены гистограммы частотных распределений. На пересечении "Гемоглобина" с "Эритроцитами" и "Тромбоцитами" находятся соответствующие корреляционные поля с линией регрессии.
6. Categ. scatterplot (Категоризированные диаграммы рассеяния). Широко используемый и весьма удобный инструмент визуализации.
Чтобы воспользоваться этим инструментом, выйдем из модуля Basic Statistics и снова туда зайдём. Нажмём на кнопку Categ. scatterplot. Для наглядности выберем две переменные "Эритроциты" (ось Х) и "Гемоглобин" (ось Y). Далее перед нами откроется поле выбора качественных (как номинальных, так и порядковых) переменных. В нашем примере таковыми являются пол пациентов (номинальная переменная) и возраст в соответствии с классификацией возрастов, принятой ВОЗ (порядковая переменная), и это отображено в соответствующем поле. Допустим, нас интересует категоризация только по признаку пола, соответственно, в поле First variable мы указываем "Пол". Далее программа предлагает нам обозначить названия переменной, нажимаем на кнопку All, и видим, что категории переменной автоматически обозначаются так, как мы их указали в списке: жен и муж. Если бы мы хотели внести дополнительную категорию, Возраст (по ВОЗ), её необходимо было бы отметить в поле Second variable; но если мы укажем Пол в этом поле повторно, программа оповестит нас о том, что списки перекрываются. Результат - диаграмма рассеяния (то есть, две прямые регрессии) отдельно для пациентов мужского пола и женского.
Прямая регрессии, описывающая зависимость между числом эритроцитов и уровнем гемоглобина в крови, для женского пола описывается уравнением прямой:
Гемоглобин = -145.7322 + 67.0109 * х.
Для мужского пола: Гемоглобин = -590.6364 + 181.8182 * х.
* х = число эритроцитов.
7. Surface plots (Графики поверхности). Наряду с 3D scatterplots (Трёхмерная диаграмма рассеяния), это ещё одно представление трёхмерного набора данных.
Он показывает взаимосвязь между тремя переменными - "Гемоглобин" (ось Х), "Тромбоциты" (ось Y) и "Эритроциты" (ось Z, высота), а не просто отображает отдельные точки данных.
Выйдем из модуля Basic Statistics и зайдём снова, нажмём на кнопку "Surface plots". В рабочем окне для ввода данных укажем наши переменные и нажмём OK. Получаем график поверхности.
8. 3D histograms (3D гистограмма). По способу анализа данных трехмерные диаграммы ничем не отличаются от двумерных, кроме того, что их можно строить по трём анализируемым переменным.
Выйдем из модуля Basic Statistics и туда зайдём снова. Нажмём на кнопку "3D histograms". В рабочем окне для ввода данных укажем "Эритроциты" и "Гемоглобин", нажмём OK, и видим 3D гистограмму.
**Стоит обратить внимание на то, что везде на графиках и в таблицах пропущенные данные (missing data) (в нашем примере такие отсутствуют) обрабатываются путём Casewise.