В этой статье я опишу свой шаблон исследования для селекции моделей, а также подниму вопрос неоднозначности замеров, ответа у меня на него нет, пока....
Экспериментирую с набором данных добавляю убираю разные атрибуты. В моём случае это разные индикаторы, тайм фичи или дополнительные инструмент например индекс RTSI. А получаю сильно хуже точность на валидационной выборке в сравнении с тестовой.
Пару слов о модели
Регрессия по дневным свечам прогнозирую рост на неделю вперёд. Меня интересует рост от 2%
Как выстроен пайплайн для подбора и оценки модели.
- Грузим данные (с мосбиржи)
- считаем фичи(индикаторы)
- готовим обучающую выборку, тестовую выборку и валидационную
Валидационная - данные за 2 последних месяца модель при обучении их не видит.
Трейн и тест выборки - классическая sklearn train_test_split

- Обучаем модель
- Замеры на тестовых данных
- Замеряем точность (я использую встроенный Score + mse)
score: 0.5616976879261406 mse: 0.024174698
- Далее строю график где по одной оси прогноз а по другой факт. Визуализация невязок. Тут можно почитать И вот тут хорошо описано про метрики регрессии.
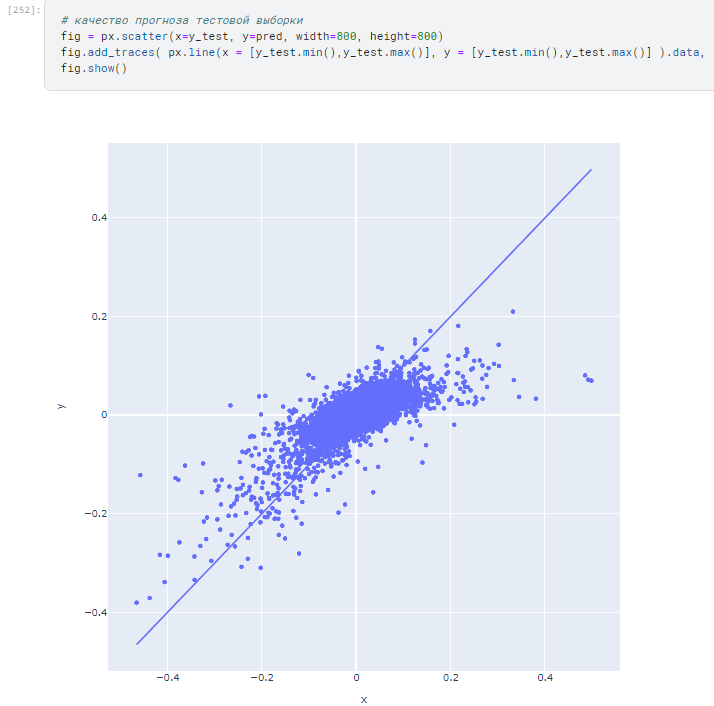
- Подбираю границу срабатывания (тк у меня регрессия и есть целевой показатель) при каком пороговом значении доход максимальный. У меня примерно в районе 0.02
- Считаю экономику примерные показатели выгоды если все сигналы модели отработать. Точнее баланс сумма дохода на вложенную 1000р - сумма убытка с той-же вложенной суммы (без вычета комиссии брокера за транзакцию)
- Замеры на валидационной выборке
- Также график, назову график невязки (но я не уверен что его так правильно называть)
- Подбор границы
- Экономика
- Ну и под конец матрица несоответствий тут про неё материал
- Также, строю прогнозные точки входа на реальных данных (валидационных)
Итак проблема
На тестовых данных всё очень хорошо, но на валидации сильно хуже. Я понимаю что на валидации - должно быть хуже по точности. Но получается сильно хуже.
Ну и график невязки на валидации совершенно не той формы. Он вытянут вдоль оси x=0 а должен быть вдоль y=x.
Здесь у меня пока ответа на вопрос нет. Есть гипотеза. Рынок сильно изменился за 2 последних месяца. (Косвенное подтверждение - если обучать на интервале 4 года в прошлое и на 1 год, во 2м случае точность выше )
Проблема выбора #2
С одной стороны модель хорошая (score ~0.6) на тестовых данных, но плохая на валидации финмодели (баланс маленький), с другой - модель с более низкой точностью на тесте но на валидации финмодели в плюс. Моё решение Тут я выбираю модель где фин модель на валидации лучше.
PS
Если вы знаете что не так или подходы как улучшить показатели - велком в комменты буду очень благодарен. Ну или у Вас есть что добавить. Или разнести в щепки мой подход - прочитаю внимательно. Если понравились материалы помните про лайки, они помогают продвигать канал, а также мотивируют автора на новые исследования и публикации.