
О теории метода RAG, реализуемого программно, можно почитать в моей статье
Программная реализация
Программно метод RAG можно реализовать на языке программирования python. Я буду приводить пример, как я реализовал метод используя python на операционной системе MacOS. Реализация на других операционных системах может отличаться из-за совместимости используемых пакетов.
Шаг первый. Готовим векторную базу данных
Векторную базу данных я готовлю с помощью скрипта create_database_pdf.py. Ниже я буду приводить выдержки их него, снабжая комментариями
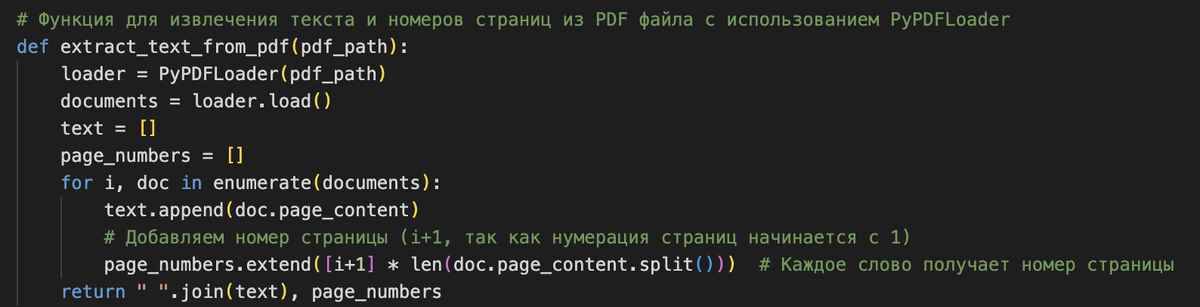
Объявляем функцию, которая извлекает текст из PDF файлов и запоминает номер страницы из которой текст был извлечен. Номера страниц запоминаются, что бы при получении ответа понять, с какой именно страницы был извлечен чанк для подготовки ответа.
Объявляем функцию, которая разбивает текст, поступающий на вход на чанки. Перекрытие(overlap) - это параметр, который отвечает на сколько следующий chank заступает на предыдущий. Это позволяет более точно подбирать нужные сhunks. В противном случае, ключевая информация может быть обрезана и остаться в предыдущем кусочке текста, не попав к контекст для нейросети.
Определяем основные переменные и списки используемые в коде. Для хранения данных я выбрал векторную базу данных Chromadb, которая хорошо подходит для таких задач.
Используя объявленный выше функции анализируем все PDF документы из заданной директории, делим на чанки, записывая в метаданные с какой страницы какого документа был взят тот или иной чанк. Полученные куски переводим в векторное представление с помощью языковой модели для оптимизации поиска данных.
Чанки в векторном представлении добавляем к коллекцию нашей базы данных. Вместе с чашками записываем метаданные, которые включают в себя документ и страницу документа, из которого был взят кусочек, а так же его идентификатор.
В конце добавляем код, для вывода информации о том, как прошло создание векторной базы данных на основе PDF файлов. Данная информация будет полезна для отладки и что бы понять, все прошло хорошо.
Из вывода в терминале мы видим, что в результате работы скрипта был разбит 1 документ (это PDF с правилами к игре Манчкин) на 56 чанков. Кроме того выводится пример такого чанка с методанными, а именно:
- ID чанка
- Имя документа из которого этот чанк
- Номер страницы документа из которого этот чанк
- Сам контент(текст) чанка
Шаг второй. Готовим запрос, отправляем его языковой модели и получаем ответ
Готовить запрос, отправлять языковой модели и получать от нее ответ я буду с помощью скрипта create_database_pdf.py
Определяем основные переменные и списки используемые в коде.
Описываем шаблон запроса к нейросети (промпта)
Объявляем функцию, с помощью которой мы будем переводить наш вопрос в векторное представление, искать по нему подходящие чанки и добавлять их в промпт. У найденных чанков, так же запоминаем методанные.
Объявляем функцию, которая будет отправлять получившийся промпт на развернутый с помощью LM Studio локально сервер с языковой моделью. При необходимости промт, можно отправлять не на локальный сервер, а на сервер c ChatGPT или с другой языковой моделью.
О том, что такое LM Studio и как ей пользоваться можно почитать в моей статье
Используя объявленный выше функции направляем промтп языковой модели и получаем от нее ответ.
Запустить скрипт, можно следующим образом, в качестве аргумента передав запрос.
python ask.py "Что такое бродячая тварь?"
Обработав наш запрос, скрипт подготовит следующим промпт
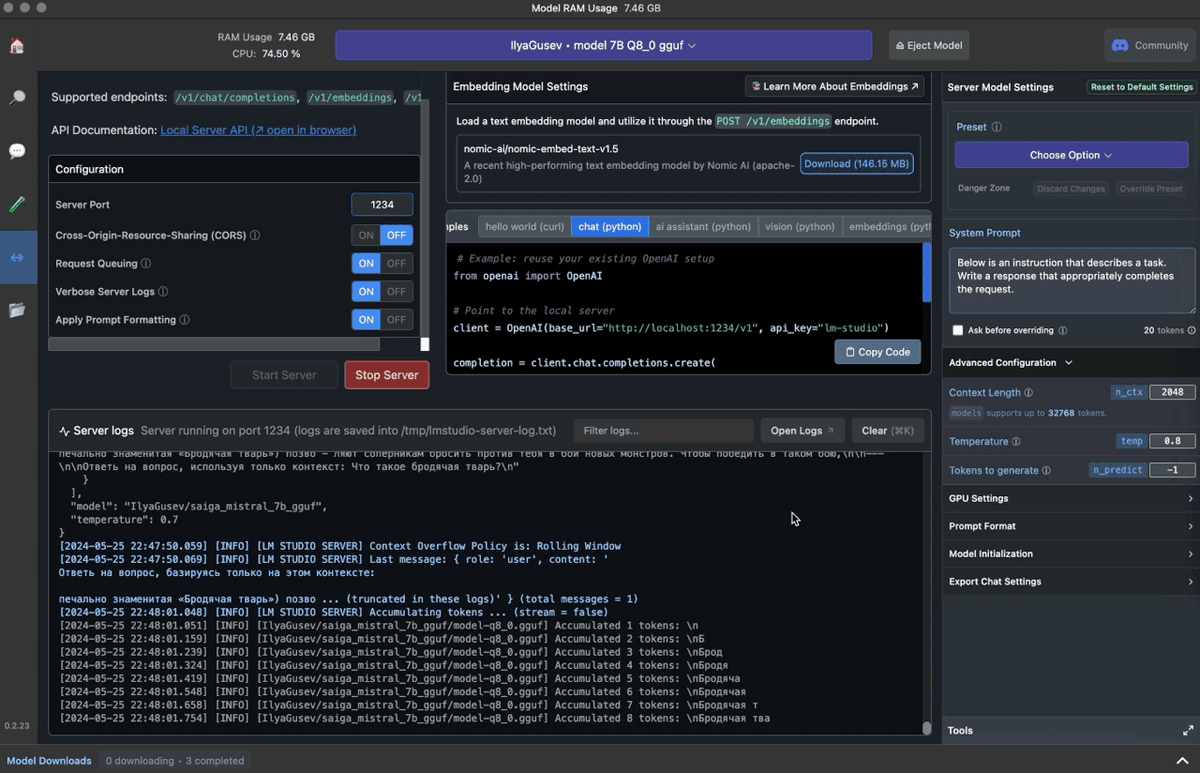
Локальный сервер с языковой моделью получает наш промпт и готовит на него ответ
В ответ от языковой модели мы получаем актуальный ответ, соответствующий запросу на основе данных из нашей базы знаний.
Вы прекрасны!
Исходный код
Исходный код можно найти на моем GitHub
😇 Если вам интересна тема нейросетей, то подписывайтесь на мой канал в telegram