Наивная схема распараллеливания исходно-последовательной программы
Давайте “возьмём быка за рога” и изобразим такую вот схему, иллюстрирующую наивный процесс распараллеливания программы (кстати, схему, претендующую на всеобщность, рис. 3). Вспоминая Алана Тюринга, мы (привычно) говорим о программы как о последовательности отдельных законченных машинных команд (кстати, утверждение о возможности составления любых, сколь угодно сложных программ, из единичных и ограниченных команд составляет один из важнейших результатов научной деятельности Тюринга).
Заявленная наивность (в данном случае - упрощённость) данной схемы заключается в изображении фактически линейной программы; в действительности имеется большое количество условных и безусловных переходов (действие которых также должно быть учтено). Кстати, традиционный метод использования регистра-счётчика команд в случае параллелизации вычислений не очень подходит… современный вариант заключается в реализации метода предика́тов; чуть подробнее см. публикацию #009).
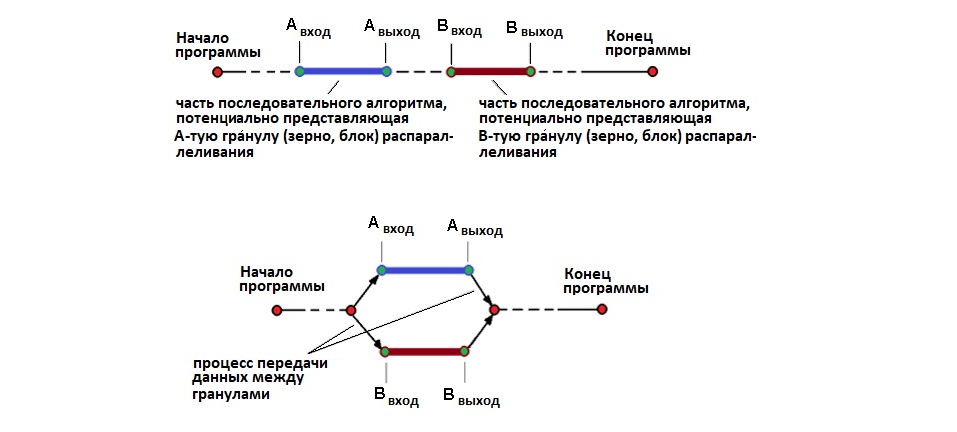
Имеем два участка кода (на самом деле их, конечно, может быть много) – последовательности [Aвход ÷ Aвыход] и [Bвход ÷ Bвыход]. Размер участков кода А и В фиксирован (он может быть от одной машинной команды до произвольного их количества – не больше, конечно, общего размера программы). Основное условие параллелизма - блоки A и Bмогут быть выполнены параллельно тогда и только тогда, если набор Bвход является независимым от Aвыход по всем составляющим наборам элементов. Процесс разбиения целой исходно-последовательной программы на мо́гущие выполняться параллельно блоки называется декомпозицией, а блоки эти часто называют грану́лами параллелизма.
Обратите внимание на (неявную) особенность схемы – она “работает” слева направо (согласно хода выполнения программы)! В самом деле, условие независимости Bвход от Aвыход может быть проверено только после анализа Aвыход и так далее от начала программы к её концу. Ничего особенного – в этом и заключается глубинная причинноследственность сущностей программы (и алгоритма, конечно же)...
Существуют вычислительные архитектуры с размером гранулы параллелизма менее машинный команды – это т.н. процессоры модуля́рной арифметики (система оста́точных классов), да и во всем известных процессорах x86 фирмы Intel Corp. и AMD (Advanced Micro Device, Inc.) отдельные части машинных команд выполняются отнюдь не целиком (а частями параллельно на конвейере).
Каждая гранула параллелизма выполняется на отдельном вычислителе, включающем арифметико-логическое устройство (АЛУ) и локальную оперативную память (ОП). В противном случае мы имеет дело не с истинным параллелизмом, а с конкурентным выполнением программ (отдельные задания выполняются попеременно, т.о. конкурируя за один и тот же вычислительный ресурс).
“Хорошо всё на бумаге, да забыли про овраги”
До сих пор не определены:
- Размер блоков (возможных гранул параллелизма).
- Положение каждого блока (напр., в виде координаты его начала в виде смещения номера машинной команды относительно начала программы).
Так как реальные программы содержат многие миллионы машинных команд, общее число сочетаний по этим двум степеням свободы огромно и в общем случае задача формального построения плана (расписания) выполнения параллельной программы относится к NP-полным, методов точного решения которых неизвестно. Точное решение можно получить исключительно методом грубого (примитивного) перебора вариантов (brute force) вследствие необходимости запредельного (в некоторых случаях - для существующих суперкомпьютеров – сопоставимого со временем существования Вселенной) времени (оптимисты могут надеяться на квантовые компьютеры). Впрочем, это стандартная ситуация для “задач составления расписаний”…
Как Читатель понимает NP-полноту́ выражений? Кстати, NP в данном контексте формально означает всего лишь “недетерминированное (необязательное) завершение за полиномиальное время”…
Использование гра́нул параллелизма повышенного размера
Казалось бы, использование гранул параллелизма повышенного размера (до размера тысяч машинных команд или множества строк исходного кода на языке высокого уровня) помогает исправить ситуацию (резко снижается число степеней свободы при переборе), но при этом имеет и минусы – напр., излишне большой объём входных и выходных данных. Использование гранул параллелизма повышенного размера широко применяется, впрочем, в случае явного параллелизма по данным (случаи, когда даже при неглубоком анализе информационной структуры алгоритма выпукло обозначаются структурные блоки для обработки – напр., в случае блочной структуры алгоритмов линейной алгебры – операции над векторами и матрицами). Приходится констатировать, что в большинстве случаев конечные пользователи на этом уровне “анализа тонкой информационной структуры алгоритмов” и остаются…
Причём обычно приходится решать задачу многокристальной оптимизации (напр., нужно совместить максимальную скорость расчёта с минимальным использованием имеющегося в распоряжении оборудования – отдельных параллельных вычислителей). Задача рациональной (причём речь даже не идёт глобальной оптимизации, а хотя бы о рациональности – разумности, оптимальности хотя бы по одному-двум параметрам) декомпозиции поистине сложна́..!
В простых случаях (например, при постулировании размера анализируемых блоков в одну машинную инструкцию) построение плана сильно упрощается (подход соответствует уровню параллелизма в одну машинную команду, fine-grained parallelism).
Обычно различают четыре уровня (определяемые размером гранулы) параллелизма - уровень битов (микроуровневый), уровень машинных команд (мелкозерни́стый, fine-grained, ILP - Instruction-Level Parallelizm), уровень потоков (среднезернистый, medium-grained), уровень заданий (крупногрануля́рный, coarse-grained); дополнительно различают параллелизм по данным и параллелизм по задачам.
Однако в этом случае следует подумать о технических возможностях “доста́вки” кода и данных каждой команды (наклонные линии со стрелками на рис. 3) к конкретному вычислителю – время на такую операцию должно быть (в идеале) много меньше длительности выполнения самой команды (иначе получим вычислительную систему, за́нятую в основном “перека́чкой” данных внутри себя в ущерб прямому назначению - выполнению арифметико-логических действий). Время выполнения простых арифметических машинных команд в современных процессорах достигает 10^(-9) сек (наносекунд), время до́ступа к данным в оперативной памяти требует порядка 100 машинных тактов (следствие многоуровневой адресации). При равном времени выборки данных из памяти и времени выполнения машинных команд “бесполезно теряется” не менее 50% времени (проблема бутылочного горлышка, bootlneck).
Однако естественно стремление увеличить размер гранулы параллелизма. Дело в том, что обычно время доставки данных к вычислителю растёт медленнее, чем время обработки данных (это убедительно показал акад. Воеводин В.В. в своей книге “Вычислительная математика и структура алгоритмов”).
Для процедуры перемножения матриц, например, время выполнения гранулы параллелизма растёт пропорционально N^3, а время доставки данных к вычислителю – N^2. Не следует надеяться, правда, что второе всегда окажется меньше первого – не учитываемые в подобных методах оценки коэффициенты в определённом диапазоне могут показать прямо противоположное).
Удобно ввести коэффициент (степень) гранулярности kгран. показывающий отношение времён выполнения гранулы tвыч. и доставки данных для выполнения входящих в гранулу команд в виде tдост. :

Этот показатель хорошо иллюстрирует (относительное) соотношение времён, потребное для совершения собственно вычислений и времени, необходимого для доставки данных для этих вычислений. Мы же с Вами существует во Времени - на это, кстати, указывают не вертикальные, а наклонные линии (это рядом с которыми помещена надпись “Процесс передачи данных между гранулами”) на рис. 3.
Явление сетевой деграда́ции вычислений
При kгран.≈1 потери времени на доставку данных для вычислений составляет не менее 50%, при kгран.≈10 – около 10%, при kгран.≈100 - около 1% и т.д. Для доставки данных от памяти к вычислителю обычно используется шины передачи данных или компьютерные сети, для максимально полной загрузки вычислителя требуется достижение очень высокой скорости передачи данных при минимуме задержки обмена (лате́нтности); при этом в выражении (1) снижается значение знаменателя. В настоящее время перспективным считается реализация технологий создания микросхем, позволяющих максимально сблизить области обработки и хранения данных. При этом первые шаги в этом направлении сделаны (автор имеет в виду реализацию части кэш-памяти непосредственно на кристалле процессора).
Такая ситуация (время доста́вки данных велико́ по сравнению с временем их обработки - т.е. kгран. мал) приводит к т.н. сетевой деградации вычислений - явлению очень неприятному и не всегда правильно диагностируемому. Подобное явление возникает, напр., при попытках распределения излишне простых операций (единицы машинных команд) на отдельные ядра многоядерного процессора.
На миниатюре сверху качественно показано это явление. На графике по оси абсцисс отложено число параллельных вычислителей, по оси ординат – ускорение (убыстре́ние относительно времени последовательного выполнения программы). В этих координатах пунктирная прямая соответствует идеальному распараллеливанию; N3>N2>N1 – размер (абсолютный) гранул параллелизма. При малом значении N1 и большом числе параллельных вычислителей реализуется режим сетевой деградации вычислений, при котором ускорение вычислений падает ниже уровня, характерного для режима последовательных вычислений (показано жирным красным эллипсом).
К счастью, обычно помогает дополнительная информация об алгоритме (выпуклый пример – поблочная обработка в задачах линейной алгебры). Однако это тема для рассмотрения в будущем.
"Если вы видите свет в конце тоннеля…"
Казалось бы – проблем больше чем ответов..? Как гова́ривал (выдающийся польский писатель-сатирик и философ) Стани́слав Е́жи Лец – “Если вы видите свет в конце тоннеля, это значит что на вас со страшной скоростью несётся поезд”... Если бы так было бы, тогда и цикла публикаций этого не было бы..!
Автор перечислил (несколько) “лежащих на поверхности” проблем параллелизации вычислений. А какие дополнительные проблемы реализации параллельных вычислений видите Вы?