Google провела свою ежегодную масштабную конференцию Google I/O, на которой анонсировала для разработчиков все свои новые продукты. За время двухчасовой презентации аббревиатура «ИИ» прозвучала со сцены 121 раз. В общем, искусственный интеллект – везде. А теперь перейдём к подробностям.
Итак, анонсировали новую ИИ-модель Gemini 1.5 Flash, она занимает промежуточное положение между базовой Gemini 1.5 Nano, работающей локально на устройствах, и дорогой продвинутой 1.5 Pro. Именно такое хотели разработчики приложений и сервисов – чтобы токены запросов были дешевле, но при этом возможностей было больше, чем у слабой локальной модели. При этом модель сохранила одно из главных конкурентных преимуществ Gemini Pro: большое окно контекста в 1 миллион токенов. То есть, запрос (промпт) может быть поистине гигантстким – для сравнения, у других больших языковых моделей размер окна исчисляется, как правило, десятками тысяч токенов.

Однако позднее в Pro-модели размер окна увеличат до 2 млн токенов, то есть, она сможет за один запрос обработать более 1,4 млн. слов, или 60 тыс. строк программного кода, или 22 часа аудиозаписей либо 2 часа видео.
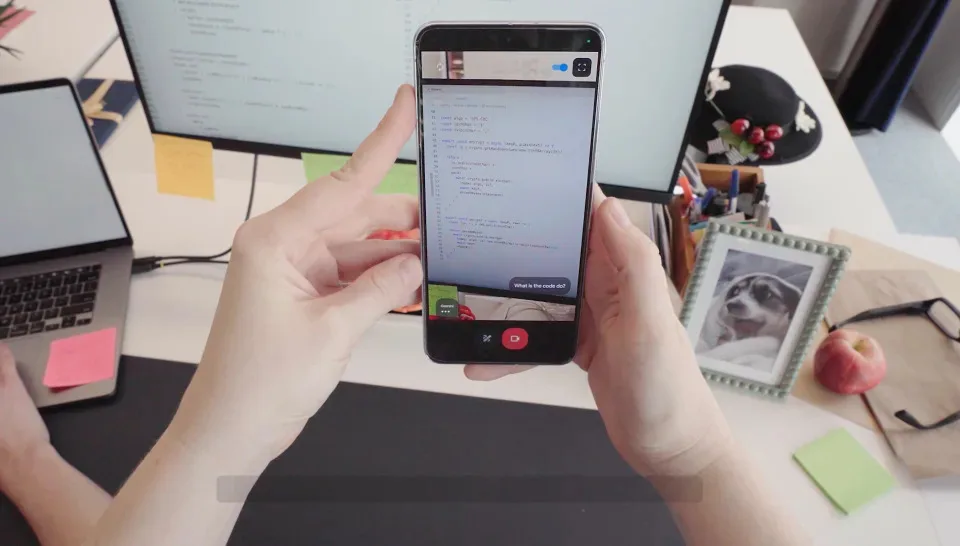
Следующая новость – Project Astra, это ранняя версия повседневного помощника на базе ИИ. В демо-ролике показывают, как пользователь наводит камеру смартфона на разные предметы, а помощник обсуждает с ним то, что видит. Самый интересный момент: помощник рассказывает пользователю, где тот забыл свои очки, хотя очки лишь один раз случайно мелькают в кадре. Но очки тут неспроста: ассистент Astra как раз может быть встроен в очки, которые будут разговаривать с вами. Тут не сойти бы с ума – в какой-то момент возникает ощущение, что говоришь сам с собой.
Двигаемся дальше: искусственный интеллект теперь есть и в Google Фото, правда, пока работает только в США. Он может реагировать на сложные запросы типа: «покажи мне лучшее фото из каждого национального парка, в котором я был». И нейросеть выберет самые красивые данные по геолокации. Также ИИ может генерировать подписи к фото для их публикации в соцсети.
Анонсированы также Veo и Imagen 3 – генеративные модели для создания изображений. Первая генерирует видео в FullHD-качестве длительностью более минуты, при этом знает о различных художественных эффектов типа таймлапса. Вторая создаёт картинки по тексовым запросам, в том числе фотореалистичные и без артефактов – лучше, чем у DALLE-3.
Большие изменения коснулись поисковой системы Google. Теперь она понимает сложные запросы на естественном языке типа: «Найди в Бостоне лучше студии йоги или пилатеса и покажи их предложения для первого занятия, а также время похода пешком от района Бикон Хилл». А по умолчанию над результатами поиска будет выдаваться ответ, собранный ИИ из разных источников, без необходимости перехода на сайты. В общем, «Яндекс Нейро», только Google. Это уже работает в США, а до конца года эту же функцию выкатят более чем для миллиарда жителей планеты.
Ну и, конечно, генеративный ИИ Gemini будет встроен в Android 15 – это главное отличие новой версии ОС. Помощник будет знать, какое приложение запущено, какая картинка на экране или какое видео вы смотрите, и паралелльно можно будет задавать помощнику контекстные вопросы о нём. Хотя что-то похожее умеет Google Assistant.
Остальны новости менее значимые: Google будет автоматически помечать сгенерированные видео и тексты «цифровыми водяными знаками», Gemini будет доступен также в боковой панели Gmail и Google Docs, и даже сможет прослушивать ваши телефонные звонки, чтобы предупреждать о мошенниках.
Ну, а побочный эффект тоже ясен: такая интеграция ИИ в вашу жизнь позволит его владельцам знать о вас ещё больше. Параноики, начинайте бояться!



















