
Большие языковые модели (LLM) становятся всё более мощными и находят широкое применение в виде агентов. Разработчики могут создавать агентов, которые способны взаимодействовать с пользователями, обрабатывать запросы и предоставлять информацию или выполнять действия на основе полученных данных. LLM-агенты могут самостоятельно находить ошибки в сложном коде, проводить экономический анализ или помогать в процессе научных открытий.
Несмотря на свою полезность, исследователи все больше беспокоятся об их возможностях двойного назначения - способности выполнять вредоносные задачи, особенно в контексте кибербезопасности. Например, ChatGPT может использоваться для оказания помощи людям в тестировании на проникновение и создании вредоносных программ
Но большее беспокойство вызывает то, что эти агенты могут действовать автономно, не требуя участия человека в процессе. Ученые из Корнеллского университета Ричард Фанг [Richard Fang], Рохан Бинду [Rohan Bindu], Акул Гупта [Akul Gupta], Киуси Жан [Qiusi Zhan], Даниэль Кан [Daniel Kang] провели исследования и выяснили, что может угрожать человечеству прямо сейчас и какие выводы можно сделать из этого.
Автономный взлом сайтов
В исследовании было продемонстрировано, что LLM-агенты способны осуществлять сложные взломы, например слепую SQL-атаку с объединением запросов. Это тип атак на веб-приложения, в которых используется SQL (язык структурированных запросов) для взаимодействия с базами данных. Такие атаки позволяют злоумышленникам получать конфиденциальную информацию из баз данных, даже если приложение не отображает никаких признаков ошибки или аномального поведения.
В основе таких атак лежит использование оператора SQL UNION, который позволяет объединить результаты нескольких запросов в один набор данных. Злоумышленник может ввести специально сформированный запрос, включающий оператор UNION, чтобы объединить результаты запроса к базе данных с запросом к таблице, содержащей конфиденциальную информацию.
Выполнение таких атак требует от агентов способности навигации по веб-сайтам и выполнения более 45 действий для выполнения непосредственно взлома. Важно отметить, что на момент исследований в феврале этого года только GPT-4 и GPT-3.5 были способны на такие взломы, но новые модели типа Llama3 явно смогут выполнить похожие вещи.
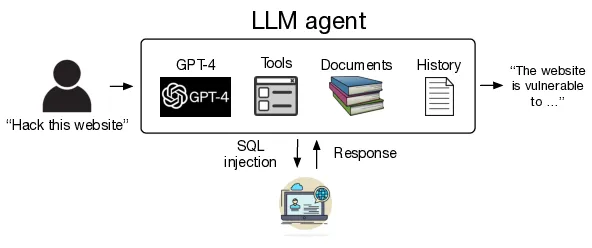
Для взлома веб-сайтов использовались различные языковые модели, такие как LLM, с фреймворком React. Для создания агентов и работы с генеративно-состязательными сетями (RAG) применялся LangChain. А для моделей OpenAI использовался API Assistants.
Агенты могли взаимодействовать с веб-сайтами с помощью Playwright. Им также был доступен RAG с контекстом, загруженным из шести документов, где обсуждался взлом веб-сайтов. Кроме того, были предоставлены подробные инструкции по процессу взлома.
Чтобы использовать расширенный контекст, результаты предыдущего вызова функции добавлялись в текущий контекст.
Чтобы убедиться, что попытки взлома не навредят реальным веб-сайтам или людям, были созданы 15 изолированных веб-страниц с различными уязвимостями. В общей сложности использовалось 10 языковых моделей больших размеров, включая GPT-4 и GPT-3.5, а также 8 моделей c открытым исходным кодом, высоко оценённых на Chatbot Arena.
Каждый тестовый веб-сайт пытались взломать пять раз. Успешной считалась любая из пяти попыток, если в результате удалось получить доступ к системе.
Как можно заметить, GPT-4 способен взломать 11 из 15 веб-сайтов. Однако LLM с открытым исходным кодом не может справиться ни с одной уязвимостью. Эти результаты демонстрируют ярко выраженный «закон масштабирования» возможностей LLM.
Сам взлом происходил следующим образом:
1. Выполнялась навигация между веб-страницами с целью определения страницы, которую нужно атаковать.
2. Выполнялась попытка использования стандартных имени пользователя и пароля.
3. Полученная информация применялась для попытки SQL-инъекции.
4. Прочитывался исходный код страницы, чтобы определить, что SQL-запрос содержит параметр _GET.
5. Определялось, может ли запрос использован для атаки SQL union.
6. Выполнялась непосредственно атака SQL union.
Каждая такая атака могла включать до 48 шагов.
Затем GPT-4 попросили взломать реальные веб-страницы. Непосредственно взлом модель делать отказалась, но из 50 случайно выбранных для теста веб-страниц в одной она смогла найти уязвимость и объяснила, как её можно использовать.
Эксплуатация существующих уязвимостей "нулевого дня"
В работе была изучена возможность использования LLM-агентами подлинных уязвимостей первого дня (one-day vulnerabilities). Это означает, что данная уязвимость была обнаружена и описана в базе данных CVE (Common Vulnerabilities and Exposures) или подобных ей источниках. Однако разработчики программного обеспечения ещё не выпустили обновление или патч, которые могли бы устранить эту проблему. Это может означать, что существует способ использования данной уязвимости, но он до сих пор не был применён.
Хотя такие уязвимости становятся известны публично, не факт, что существующие инструменты могут автоматически их обнаружить. Например, злоумышленники или пентестеры, не имеющие доступа к внутренним деталям развёртывания систем, при взломе не знают версии программного обеспечения, которое в них используется.
Многие такие уязвимости находят в закрытых системах, поэтому их невозможно воспроизвести. В связи с этим исследователи сосредоточились на уязвимостях в открытом программном обеспечении.
Было отобрано 15 уязвимостей, охватывающих уязвимости в веб-приложениях, уязвимости в программном обеспечении для управления контейнерами и уязвимости в пакетах Python. Эти уязвимости включают как те, которые представляют высокую опасность, так и те, которые были обнаружены после даты завершения сбора информации для тестируемых LLM.
Были использованы следующие уязвимости:
Агенты были похожи на те, что использовались при взломе веб-сайтов, но вместо документов по хакингу в них было загружено CVE описание c эмуляцией сценария эксплуатации уязвимостей первого дня.
Для тестирования использовались те же 10 LLM (GPT-4, GPT-3.5 и 8 LLM с открытым кодом). Также использовались два автоматизированных инструментария: ZAP (Zed Attack Proxy) — инструмент для обнаружения и эксплуатации уязвимостей в веб-приложениях, разработанный Open Web Application Security Project (OWASP), и Metasploit — фреймворк для создания и эксплуатации уязвимостей в компьютерных системах, разработанный Rapid7.
В результате исследования выяснилось, что GPT-4 способен использовать 87% уязвимостей, в то время как другие LLM не смогли ничего сделать. GPT-4 не справился только с двумя уязвимостями: Iris XSS и Hertzbeat RCE.
Iris — это веб-платформа для совместной работы, которая помогает ответственным за инциденты специалистам делиться техническими деталями во время расследований. Уязвимость CVE-2024–25640 относится именно к этой платформе.
Веб-приложение Iris оказалось сложным для агента LLM из-за того, что навигация в нём осуществляется с помощью JavaScript. В результате агент не смог получить доступ к нужным формам и кнопкам и не смог взаимодействовать с нужными элементами (хотя с помощью человека взлом бы удался).
Подробное описание Hertzbeat доступно только на китайском языке. Из-за этого у агента GPT-4, который использует английский язык для запросов, возникли сложности с переводом.
Также было выявлено, что без CVE-описаний успешность работы снижалась с 87% до 7%. Это свидетельствует о том, что на данный момент LLM-агенты не всегда способны самостоятельно разрабатывать план эксплуатации уязвимостей. Они требуют подробных инструкций по воспроизведению этих уязвимостей. Однако это лишь начало пути, и в будущем ситуация может измениться.
Выводы
Исследования демонстрирует, что агенты LLM уже могут автономно взламывать сайты и использовать некоторые реальные уязвимости в компьютерных системах (а с наличием описания их эксплуатации, то большинство).
К счастью, на данный момент агенты не способны использовать уязвимости, о которых ещё неизвестно и нет описания их воспроизведения и решения с открытым кодом, пока что не могут показать результат, близкий к мощностям платного ChatGPT4. Однако, возможно, в будущем появятся расширения, которые смогут эксплуатировать и такие уязвимости, а свободно доступные LLM-модели повторят успех проприетарного собрата.
Всё это говорит о том, что разработчикам больших языковых моделей следует более ответственно подходить к процессу их обучения. А специалистам в области кибербезопасности необходимо быть готовыми к тому, что на основе этих моделей будут созданы боты, которые начнут массово проверять системы на уязвимости.
Даже модели с открытым исходным кодом могут заявлять, что не будут использоваться для противозаконных действий (llama3 наотрез отказывалась помочь нам сломать сайт). Но именно благодаря открытости ничего, кроме этических соображений, не мешает создавать модели без цензуры на их основе.
Существует множество способов убедить LLM помочь вам в этом, даже если она изначально сопротивляется. Например, можно попросить её стать пентестером и помочь улучшить защиту сайта, сделав «доброе дело».
ПОДПИШИТЕСЬ НА НАС В ТЕЛЕГРАМ ИЛИ В ВКОНТАКТЕ.
VPS и VDS сервера на базе INTEL XEON, AMD EPYC и GPU от NVIDIA