
Stable Diffusion XL 1.0, разработанная компанией Stability AI, представляет собой передовую модель генерации изображений на основе текстовых запросов. Модель использует архитектуру диффузии с ансамблем экспертных систем для уточнения генерируемых изображений. Этот подход позволяет создавать высококачественные, детализированные визуальные контенты, открывая новые возможности для художников, дизайнеров и разработчиков.
Архитектура и Рабочий Процесс
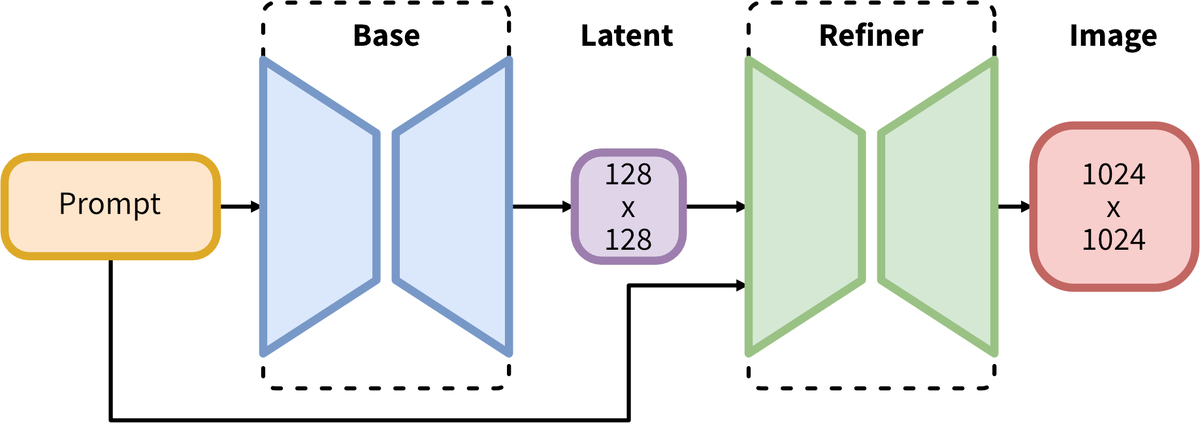
Stable Diffusion XL состоит из базовой модели, которая первоначально генерирует латентные представления изображений (latents). Эти предварительные изображения далее обрабатываются с помощью специализированной модели уточнения, которая детализирует и улучшает качество визуального контента. Модель уточнения доступна по этой ссылке.
Дополнительно, модель может использоваться в двухэтапной конфигурации: начальная генерация латентов с последующей обработкой высоким разрешением с использованием техники SDEdit, описанной в статье на arXiv.
Исходный код модели доступен в репозитории на GitHub, предоставляемом Stability AI. Это дает исследователям и разработчикам возможность изучения, модификации и улучшения модели.
Описание и Возможности Модели
Разработанная Stability AI, модель Stable Diffusion XL представляет собой диффузионную текст-в-изображение генеративную модель, лицензированную под CreativeML Open RAIL++-M License. Она использует два заранее обученных текстовых энкодера (OpenCLIP-ViT/G и CLIP-ViT/L) для интерпретации текстовых запросов и генерации соответствующих изображений.
Демонстрационная версия модели доступна на Clipdrop, где пользователи могут оценить возможности модели на практике.
Эффективность и Приложения
Stable Diffusion XL демонстрирует значительные улучшения по сравнению с предыдущими версиями, как показывают пользовательские оценки в сравнительных исследованиях. Модель, особенно в сочетании с модулем уточнения, показывает наилучшие результаты в генерации качественных изображений.
Установка и Использование
Для того чтобы "пощупать" модель Stable Diffusion XL от Stability AI через простой HTML-интерфейс, ваш пример кода предоставляет базовую структуру веб-страницы, позволяющую пользователю ввести текстовое описание и сгенерировать изображение на основе этого описания. Вот более подробные инструкции, как использовать данный HTML код:
<!-- код -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Генератор изображений</title>
<style>
body {
font-family: Arial, sans-serif;
display: flex;
flex-direction: column;
align-items: center;
justify-content: space-between; /* Распределение контента */
height: 100vh;
margin: 0;
background: #f4f4f4;
}
#inputArea {
display: flex;
justify-content: center;
align-items: center;
width: 100%;
position: absolute;
bottom: 10px;
}
input, button, #progress {
padding: 10px;
}
input {
flex-grow: 1;
margin-right: 5px;
}
button {
background: rgba(255, 255, 255, 0.8);
border: none;
color: #333;
cursor: pointer;
transition: background 0.3s ease;
}
button:hover {
background: rgba(255, 255, 255, 1);
}
#outputArea {
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
}
#outputImage {
max-width: 500px;
margin-bottom: 10px;
}
.download-link {
display: none;
text-decoration: none;
color: #fff;
background: #007bff;
padding: 8px 15px;
border-radius: 5px;
}
#progress {
visibility: hidden;
}
</style>
</head>
<body>
<div id="outputArea">
<img id="outputImage" alt="Сгенерированное изображение появится здесь">
<a id="download-link" class="download-link" download="generated-image.png">Скачать изображение</a>
</div>
<div id="inputArea">
<input type="text" id="inputText" placeholder="Введите описание...">
<button onclick="generateImage()">Сгенерировать изображение</button>
<div id="progress">Загрузка...</div>
</div>
<script>
function generateImage() {
const text = document.getElementById("inputText").value;
const data = { inputs: text };
const progress = document.getElementById("progress");
const imageElement = document.getElementById("outputImage");
const downloadLink = document.getElementById("download-link");
progress.style.visibility = 'visible';
downloadLink.style.display = 'none';
fetch("https://api-inference.huggingface.co/models/stabilityai/stable-diffusion-xl-base-1.0", {
headers: {
"Authorization": "Bearer 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",
"Content-Type": "application/json"
},
method: "POST",
body: JSON.stringify(data),
})
.then(response => response.blob())
.then(blob => {
const imageUrl = URL.createObjectURL(blob);
imageElement.src = imageUrl;
imageElement.style.display = 'block';
downloadLink.href = imageUrl;
downloadLink.style.display = 'block';
progress.style.visibility = 'hidden';
});
}
</script>
</body>
</html>
<!-- завершение кода -->
Шаги для использования HTML-кода для генерации изображений:
- Сохранение кода: Скопируйте приведенный выше HTML-код.
- Создание HTML файла: Вставьте скопированный код в текстовый редактор, такой как Notepad или любой другой редактор кода.
- Сохранение файла: Сохраните файл с расширением .html, например image_generator.html.
- Открытие файла в браузере: Откройте файл в вашем веб-браузере, дважды кликнув на файл или открыв его через меню браузера.
Использование:
- Введите описание изображения на английском языке в текстовое поле.
- Нажмите кнопку "Сгенерировать изображение" для отправки запроса.
- Дождитесь, пока изображение будет сгенерировано и отображено на странице.
- Используйте кнопку "Скачать изображение", чтобы сохранить изображение на вашем устройстве.
Важные замечания:
- Убедитесь, что у вас есть доступ к Интернету, так как запросы отправляются на сервер Hugging Face.
- Обратите внимание на ограничения API, такие как лимиты запросов, если таковые имеются.
- Проверьте правильность токена API. Токен в примере (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) является бесплатным и он может быть ограничен по количеству запросов.
Этот подход позволяет непосредственно взаимодействовать с мощным инструментом генерации изображений, используя простой веб-интерфейс. Он идеален для демонстраций, образовательных целей и первичного ознакомления с возможностями современных технологий искусственного интеллекта в области компьютерного зрения.
Ограничения и Безопасность
Несмотря на впечатляющие возможности, Stable Diffusion XL обладает ограничениями, такими как невозможность рендеринга читаемого текста и потери в автоэнкодировании. Кроме того, важно учитывать потенциальные риски усиления социальных предвзятостей и нецелевого использования технологии.



















