Опять простые числа, но у этой задачи рейтинг сложности 20%, так что я в деле.
Задача
Простые числа 3, 7, 109 и 673 достаточно замечательны. Если взять любые два из них и объединить их в произвольном порядке, в результате всегда получится простое число. Например, взяв 7 и 109, получатся простые числа 7109 и 1097. Сумма этих четырёх простых чисел, 792, представляет собой наименьшую сумму элементов множества из четырех простых чисел, обладающих данным свойством.
Найдите наименьшую сумму элементов множества из 5 простых чисел, для которых объединение любых двух даст новое простое число.
Решение
Чую, что оно будет слишком примитивное, но других мыслей по этому поводу у меня пока нет. Другие решения принципиально не гуглил, оставлю на подумать ещё.
Простые числа должны объединяться в группы по признаку совместимости. Например, берём первое число 3. Ему пока не с кем объединиться, поэтому оно образует группу из одного числа – самого себя.
Далее идёт допустим число 7, и оно объединяется с 3. Мы получаем три группы: (3), (3,7) и (7). Как можно видеть, не только осталась старая одиночная группа (3), но и добавилась ещё одна (7). Для чего это делается? Чтобы в любом случае для каждого возможного варианта нашлось своё сочетание. К примеру, 109 сочетается с (3,7) и создаёт группу (3,7,109), но старая группа (3,7) тоже остаётся, чтобы найти сочетания с каким-то другим числом. При этом 109 с одиночными (3) и (7) создаст ещё и группы (3, 109) и (7, 109) по тем же причинам.
Дальнейшие числа могут сочетаться с любой из этих групп и в свою очередь создавать свои.
Поиск будет закончен, как только размер одной из групп станет равным 5.
Инструментарий
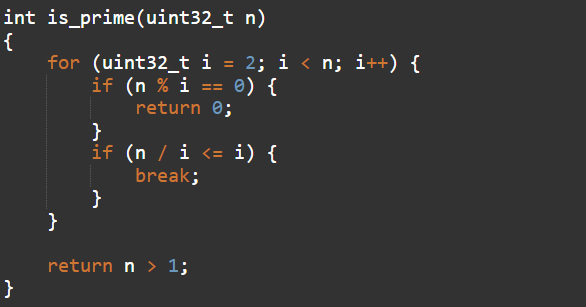
На манеже, как всегда, избитая функция определения простого числа:
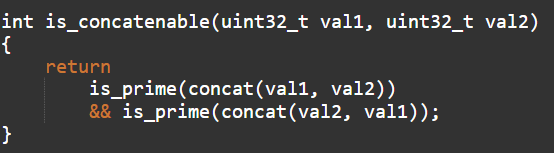
Далее функция, которая определяет возможность объединения двух простых чисел:
Далее функция concat(), которая это объединение собственно и делает:
Она рассчитывает множитель разрядов для второго числа, затем умножает первое число на этот множитель и прибавляет второе.
Затем начинаются сложности. Как было видно из вступления, нам нужно будет создавать много групп разного размера. Как управлять памятью? Можно заранее выделить на каждую группу максимальный размер, то есть 5 элементов, плюс нужен ещё способ посчитать элементы в группе. Вариант рабочий, но память будет расходоваться расточительно.
Я в конце концов пришёл к концепции дерева. К примеру, число 3 является узлом дерева. К нему можно прицепить узлы со значениями 7 и 11. Тогда у узла 7 родитель будет 3 и у узла 11 родитель тоже будет 3. Это, соответственно, означает группы (3,7) и (3,11):
3 - 7
|
11
К узлу 7 можно прицепить узел 109:
3 - 7 - 109
|
11
Тогда получаются группы (3,7,109) и (3,11). Но как говорилось выше, нужно сохранять и все старые группы тоже и также делать новые одиночные и частичные. Поэтому на самом деле дерево будет содержать такие связи:
3
7
7->3
11
11->3
109
109->3
109->7
109->7->3
Обратим внимание, что запись 109->7->3 ссылается на 7, которая ссылается на 3, в то время как 109->7 ссылается просто на 7. Чтобы не путать, где какая 7, числа надо заменить на индексы в дереве. Перепишу схему, добавив слева индекс для каждого элемента:
0: 3->x
1: 7->x
2: 7->0
3: 11->x
4: 11->0
5: 109->x
6: 109->0
7: 109->1
8: 109->2
Теперь запись 109->1 ссылается на индекс 1, то есть на 7. А запись 109->2 ссылается на индекс 2, то есть на 7->0, который в свою очередь ссылается на индекс 0, то есть 3.
С помощью x я обозначаю корневой элемент, которому не на кого ссылаться. Значение x выясним ниже.
Итак, чтобы добавить число к группе, не нужно создавать целую новую группу. Создаётся только один узел дерева, который ссылается на предыдущий. Предыдущий при этом может использоваться заново сколько угодно раз, на него просто будут ссылаться ещё и ещё из разных мест.
Перейдём к инструментарию для работы с деревом.
Это узел дерева, который имеет собственное значение val и индекс родительского узла parent.
Это дерево, с зарезервированным большим массивом под узлы nodes[] и счётчиком узлов size.
Функция tree_add_val() добавляет корневой узел в дерево:
Как можно видеть, узел добавляется в массив в следующую свободную позицию, у которой индекс равен tree->size. А ссылка на родителя у этого узла равна этому же индексу, то есть он ссылается сам на себя. Таким образом я отличаю, что узел корневой. Сделать индекс, к примеру, нулевым я не могу, так как 0 это тоже индекс, а применять некие волшебные значения типа 99999... или -1 тоже не хочется.
Функция tree_add_child() работает аналогично, но добавляет уже не корневой узел, а с конкретным родителем parent:
Погнали!
Создадим необходимые рабочие переменные: дерево tree и счётчик размера группы group_size. В массив found[] я буду собирать найденные числа, чтобы затем посчитать их сумму. Вообще сумму можно считать сразу, и по условию задачи требуется только она, но с числами будет красивее, согласитесь.
Гоним цикл по простым числам от 3 и далее:
Хочу заметить, что в заголовке цикла вместо привычного num+=2 используется num = next_prime(num).
Функция next_prime() выполняет роль генератора – выдаёт следующее простое число после num:
Я это сделал ради того, чтобы внутри главного цикла не проверять число num на простоту, и убрать одно вложенное условие.
Итак, мы получили следующее простое число. Теперь идём по уже имеющемуся дереву и пытаемся пристроить это число к какому-либо узлу:
Если число сочетается с узлом, то проверяем узел-родитель, затем его родителя и т.д. до тех пор пока не дойдём до корневого узла. Если мы до него дошли, значит вся цепочка сочетаема, и тогда мы добавляем в её конец текущее число и заканчиваем перебор:
После того как перебор закончен, проверяем длину полученной цепочки group_size. Если она достигла нужного значения, прекращаем дальнейшие проверки:
В конце всех переборов, если мы ещё не получили результат, добавляем текущее число как новый корневой узел дерева:
Ну и остаётся только распечатать найденные значения и посчитать сумму:
Ссылка на онлайн-компилятор языка C с текстом программы
Производительность
Увы и ах, программа работает, по сравнению с предыдущими задачами, крайне медленно. На моём ноутбуке это 34 секунды. Нетрудно видеть, что сложность данной задачи квадратичная. На каждый N-й добавленный в дерево элемент делается порядка N проверок.
Что с этим делать, пока не знаю. Но решение проходит по критериям проекта Эйлер.
Я сделал одну оптимизацию, а именно сохранял результаты is_concatenable() в кэш-массив, чтобы не перерасчитывать совместимость одних и тех чисел повторно. Это ускорило программу на 10 секунд. Ну то есть на 30%, это в принципе хорошо, но всё равно 24 секунды.
Я не стал включать эту оптимизацию в выложенный код, потому что она принципиально ничего не решает, но зашумляет листинг.
Если более оптимальное решение существует, оно должно как-то сокращать перебор, чтобы сделать его не квадратичным. У меня был один вариант, над которым я бился пару дней, но так ничего и не добился, поэтому пока что только так.
Подборка всех задач: