
В 2024 году поисковые системы — неотъемлемая часть жизни практически каждого человека, ведь именно они помогают ориентироваться в бесконечном потоке информации. Каждый поисковик имеет уникальные алгоритмы, которые все время улучшаются и обновляются. Одно из таких возможных нововведений от компании Google — алгоритм TW-BERT, который может изменить самую крупную поисковую выдачу, отразиться на каждом владельце сайта и повлиять на релевантность контента в поиске каждого человека в мире.
Материал написан редакцией Traffic Cardinal — это медиа о маркетинге, арбитраже трафика и заработке в Интернете. Подписывайтесь на наш Телеграм, чтобы быть в курсе актуальных новостей манимейкинга!
Что собой представляют алгоритмы?
Перед тем, как разобраться с TW-BERT, кратко вспомним о роли алгоритмов. Алгоритмы — фундамент поисковых систем, позволяющий фильтровать миллионы сайтов и при этом показывать каждому отдельному пользователю релевантный результат за доли секунд, стоит заметить, что помимо критерия релевантности очень важна «авторитетность» контента, иными словами его польза, которая определяется рядом критериев, один из которых — % дочитываний.
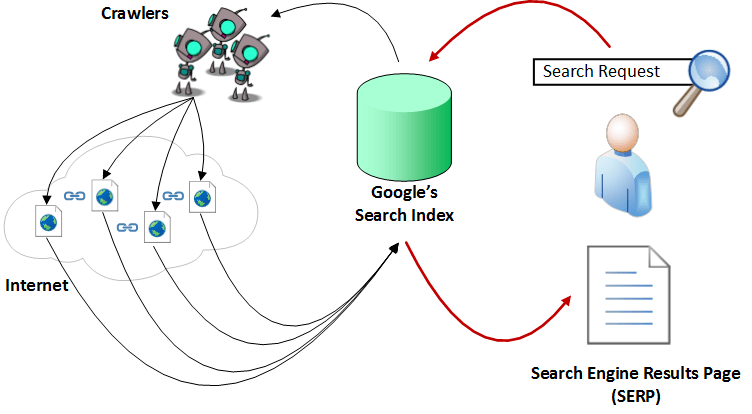
Очень упрощенный пример алгоритма Google
Страница результатов поисковой системы называется SERP. Обратите внимание, что результаты практически любой поисковой выдачи содержат как естественные поисковые запросы, так и платную рекламу, помимо этого могут присутствовать дополнительные элементы (фотографии, видео, новости и.т.п).
Теперь перейдем к сути статьи — алгоритму TW-BERT.
Презентация TW-BERT
В августе 2023 года на конференции Knowledge Discovery and Data Mining (KDD) был продемонстрирован новый алгоритм от компании Google под названием «TW-BERT». Данный алгоритм совмещает две модели: первая — отличается «глубинной» обучения, благодаря чему лучше распознает взаимосвязь между словами, а вторая — «оценочным» отношением к каждому слову или фразе в поисковом запросе. Их сочетание должно улучшить распознавание пользовательских запросов, что впоследствии повлияет на качество выдачи.
Заметьте, что TW-BERT будет определять не только важность каждого отдельного слова, но и взаимосвязь между ними. Работает это так — алгоритм определяет как слова связаны друг с другом, что позволяет углубиться в сам контекст запроса, что и является ключом к наиболее релевантной выдаче, то есть алгоритм определяет контекст использования слов, а не просто проводит поиск по словам или совокупности слов.
Для определения контекста алгоритм будет учитывать:
- Частоту употребления слова/слов в конкретном поисковом запросе.
- Частоту употребления слова/слов среди всех поисковых запросов, чтобы понять насколько эти слова важны или второстепенны (например, это может быть какой-то союз, следовательно, алгоритм это запомнит и не будет придавать ему весомого значения).
- Контекст слов, алгоритм будет обучаться, чтобы понять, что именно имеется ввиду в том или ином случае при употреблении связки слов.
- Взаимосвязь слов, алгоритм будет определять, насколько слова связаны между собой и насколько они связаны с запросом.
Особенности TW-BERT
Особенность алгоритма во «взвешивании слов» (TW-BERT оценивает каждое отдельное слово, придавая ему «вес»), благодаря чему Google начнет понимать какому слову необходимо отдавать приоритет в первую очередь, а какие слова в запросе вспомогательные и не так важны — все это в совокупности повлияет на релевантность выдачи. Важно заметить, что такой подход должен повысить качество поисковых запросов по всем направлениям, включая расширенные запросы.
В исследовательской статье Google рассказывает о работе алгоритма на примере поискового запроса в Google «Nike беговые кроссовки», где всего 3 слова. Наибольший вес алгоритм придает слову Nike, так как он понимает, что человека интересуют в первую очередь кроссовки этой компании, поэтому показывать ему просто кроссовки или беговые кроссовки — не совсем релевантно. Помимо этого алгоритм взвешивает разные вариации слов, обращает внимание как слова связаны друг с другом, как до, так и после определенного слова, что позволяет ему понять весь смысл фразы, которую ему необходимо проанализировать.
Поисковая выдача по запросу «Nike running shoes»
На следующем этапе алгоритм решает проблему контекста, ведь ему необходимо понять, что хотел пользователь употребив слова «беговые» и «кроссовки». Именно глубина обучения дает алгоритму понять, что нужно придавать вес не каждому отдельному слову, а нескольким словам вместе, собрав их во фразу «беговые кроссовки». TW-BERT придает словосочетанию «беговые кроссовки» больше веса, чем каждому отдельному слову «беговые» и «кроссовки».
Чтобы алгоритм мог разобраться, где используются термины, словосочетания, а где отдельные слова — используются нейронные подходы, которые также дают «весовую» оценку терминам, при чем модели запоминают частоту использования терминов, чтобы обучаться. Отмечается, что TW-BERT будет обучаться все время, основываясь на данных, которые он накапливает.
Весь этот процесс можно сравнить с библиотекарем, который помогает пользователю найти необходимую книгу. Если раньше наш «библиотекарь-Google» опирался на какие-то конкретные слова и пытался по ним найти книгу, то теперь библиотекарь не просто «цепляется» за слова, а понимает их смысл и контекст, что помогает ему найти идеальную книгу. Иными словами, благодаря TW-BERT Google начнет понимать не только отдельные слова, но и взаимосвязь между ними.
Нововведения алгоритма
Исследователи Google заявляют, что «TW-BERT полностью оптимизирован и обеспечивает согласованность между обучением и поиском». Происходит это благодаря оценке слов, которая повышает конечную релевантность выдачи. В целом работа TW-BERT похожа на гибридный подход.
В исследовании Google специально рассматривается 2 вариации функционирования поисковой выдачи, в первом случае (слева) используется стандартный алгоритм Google, который используется и на данный момент, а во втором случае (справа) TW-BERT, где можно проследить на каких этапах добавляется взвешивание слов.
Добавочные элементы алгоритма TW-BERT, которые легко встраиваются в уже существующий алгоритм Google
Преимущество алгоритма в том, что он легко внедряется (так как просто добавляется готовый компонент в процесс ранжирования), но помимо этого алгоритм будет поддерживать и дальнейшие обновления и нововведения. Как пишут исследователи «Алгоритм отличается от предыдущих методов взвешивания, которые нуждались в дополнительной настройке, так как они оптимизировали вес слов с помощью эвристики, вместо сквозной аналитики».
Стоит заметить, что для внедрения TW-BERT в процесс ранжирования не требуется специализированного ПО или обновления аппаратного обеспечения. То есть Гуглу нет необходимости проводить масштабные обновления уже работающего алгоритма, так как TW-BERT можно просто добавить в уже существующий алгоритм, как «дополнительную деталь», которая улучшит работу.
Будет ли внедрен TW-BERT?
Первым пунктом, указывающим на возможность внедрения алгоритма является простота его добавления. Вторым критерием выступает его эффективность, а именно насколько он улучшит состояние поиска. В текстах TW-BERT показал, что он способен улучшить производительность поисковой выдачи, что однозначно подтолкнет компанию Google к мыслям о его эксплуатации в мировом масштабе.
В сентябре 2023 года TW-BERT начал тестироваться в США, сколько времени займут тесты и решится ли все таки компания Google на его внедрение — информации пока нет.
Как новый алгоритм может повлиять на владельцев сайтов
Благодаря повышению точности поисковой выдачи, которую должен обеспечить TW-BERT, администраторы сайтов могут рассчитывать на повышение качества трафика с Google, а возможно, даже и на увеличение количества трафика, ведь сама система ранжирования будет работать чуть иначе.
В связи с этим админам рекомендуется сфокусироваться над улучшением качества контента, что впоследствии может сыграть им на руку.
SEO-показатели на которые может повилять новый алгоритм:
- Позиции в поисковой выдаче. TW-BERT будет больше ценить качественный контент.
- Релевантность. Так как алгоритм будет опираться не только на слова, но и на контекст (взаимосвязь и полноценную картину их использования), то и контент сайта должен соответствовать определенному запросу.
- Качество трафика. Глубокая и оценочная модель повысят релевантность контента, то есть повысится % пользователей, которые найдут именно то, что хотят. У юзеров, которые продают какие-то услуги — это повысит конверт, ведь они будут получать «более горячих» юзеров.
Заключение
По итогу, можно сказать, что TW-BERT выглядит как совершенно логичное улучшение уже существующей поисковой системы Google. Заметьте, что алгоритм предусматривает «плавную» интеграцию в поисковые системы Google, поэтому пользователи могут не заметить значительных скачков и грандиозных улучшений. TW-BERT подобен дополнительной детали, которая повысит эффективность уже итак работающей системы. Тем не менее владельцам сайтов рекомендуется обращать больше внимания на качество своего контента, так как это всегда сыграет им на руку в долгосрочной перспективе.