В предыдущей части мы выяснили, что чтение данных из невыровненных адресов приводит к лишним операциям, но на практике, на наших уютных домашних процессорах Intel, никакой потери эффективности не происходит.
Предыдущая часть:
Есть, однако, другой случай, где выравнивание будет влиять на производительность.
Не такая уж она и быстрая
Скорость доступа к данным по мере развития технологий росла скачкообразно. Вначале это были перфокарты, затем магнитная лента, затем гибкие диски, затем жёсткие диски, наконец очень быстрые SSD, но самой быстрой всегда оставалась оперативная память. Настолько быстрой, что операции в памяти кажутся мгновенными.
На самом деле, спускаясь на аппаратный уровень, мы обнаружим, что доступ к памяти считается очень медленным и нехорошим, прямо фу-фу. Всё дело в том, что для процессора память это что-то вроде смежной организации. Чтобы получить или записать данные, процессор должен составить официальный запрос, отправить его в эту организацию и дождаться официального ответа. Один такой обмен может занимать до 200 циклов процессора. Согласитесь, очень много.
Что же делать?
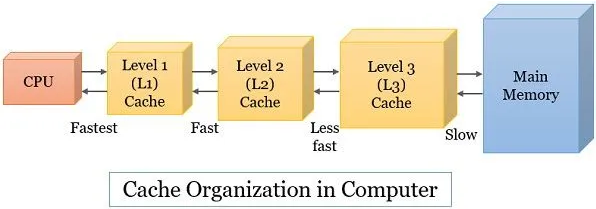
Кэш
Процессор обзавёлся своей собственной памятью с блэкджеком и, которая расположена прямо у него под боком.

Ему не требуется составлять запросы, чтобы получить из неё что-то. Поэтому обмен данными происходит практически в 100 раз быстрее.
Когда процессор получает данные из основной памяти, он сохраняет их в свою локальную память. Таким образом, если эти данные понадобятся ему ещё раз, он сразу возьмёт их, уже никого не спрашивая.
Такая память называется кэшем.
У процессора может быть три кэша разных уровней (L1, L2, L3), они иерархически связаны, но нам достаточно рассмотреть уровень L1, самый близкий к процессору.
Очевидно, что размер кэша существенно меньше размера оперативной памяти. Для L1 это может быть всего лишь 32 килобайта.
Различные аппаратные оптимизации привели к такой схеме:
Кэш L1 можно представить как таблицу, состоящую из строк длиной по 64 байта. Таким образом, 32-килобайтный кэш будет таблицей из 512 строк.
Вся память компьютера условно поделена на 64-байтные куски, и каждый такой кусок определённым образом отображается на одну из строк кеша. Это отображение фиксировано опять же из соображений оптимизации.
Когда мы запрашиваем данные из какого-либо адреса памяти, контроллер кэша определяет, в каком 64-байтном куске находится этот адрес. И загружает весь этот кусок в соответствующую строку кэша (при условии, что он ещё не был загружен, конечно).
Это эффективно потому, что память читается в специальном скоростном режиме (burst mode). Основное время тратится на подготовку чтения первого адреса, а все последующие идут как бы прицепом. Это как если бы на ваш запрос организация отправила не только требуемые данные, но и ещё дополнительные, потому что у неё есть подозрение, что вы их всё равно потом запросите.
То есть кэш всегда обновляется целыми строками. И адреса этих строк в памяти всегда кратны 64, то есть выровнены по границе 64 байт: 0, 64, 128, 192, 256 и т.д.
Когда необходимо записать данные в адрес, и этот адрес есть в кэше, то сначала запись происходит также в кэш. Пока эти данные не потребовал кто-то другой, они могут лежать в кэше, и копируются в память только при необходимости, или тогда, когда процессор простаивает. Это одна из самых распространённых политик кэша под именем write-back. В другом варианте операция записи в кэш сразу же дублируется в память. Это write-through.
Вытеснение
Так как размер кэша невелик, то невозможно загрузить туда всю память. В какой-то момент возникает ситуация, когда надо загрузить строку из памяти, но все строки уже заняты. В таком случае выбирается какая-либо строка – например, давно не используемая. Если её содержимое не менялось, оно просто выбрасывается. Если же были изменения, то строка копируется обратно в память для синхронизации. И взамен неё грузится новая строка.
Таким образом, наиболее эффективная программа должна быть устроена так, чтобы как можно больше операций с данными происходило в кэше, и чтобы строки кэша по возможности не вытеснялись и не перечитывались заново.
Для этого данные надо группировать локально. Если мы работаем с данными, расположенными по последовательным адресам, то они будут полностью в одной строке кэша, либо в нескольких, но всё равно это будет внутри кэша.
Если же работать с данными по случайным адресам, разбросанным по большому объёму памяти, то строки кэша почти всё время будут вытесняться и заменяться другими. Что сильно замедлит выполнение программы.
В этом можно убедиться с помощью теста, перебирающего 256 мегабайт памяти побайтно:
Из-за онлайна значения времени сильно плавают, поэтому привожу результаты тестов на своей машине. Последовательный доступ к элементам занимает 0.6 секунды.
Случайный доступ пропущу, перейдём сразу к STEP 64. Теперь время работы составило 2.5 секунды.
Что случилось? Шагая по 1 байту, мы используем одну строку кэша 64 раза, а шагая по 64 байта, используем одну строку кэша только по одному разу, что снижает эффективность.
Теперь сделаем STEP 1048576. И время работы стало 4.2 секунды.
Что случилось и в чём тайный смысл константы 1048576? Как говорилось выше, кэш L1 поддерживается кэшами-посредниками L2 и L3, каждый из которых больше и медленнее. Строки из L1 вытесняются в L2, а из L2 в L3. Чтобы добиться сильного замедления, нужно вытеснить строки из L3.
Размер L3 обычно равен 12 мегабайт, это 196608 строк. Но нам не надо вытеснять все строки. Как говорилось выше, каждая строка в памяти отображается на какую-то строку кеша, и это отображение имеет свои физические рамки. Определённые адреса памяти всегда попадают на один и тот же участок кэша, называемый группой. Размер группы называется ассоциативностью кеша. У L3 в нашем случае ассоциативность 12. То есть он содержит 16384 группы по 12 строк.
Чтобы сделать отображение адреса на группу, сначала переведём адрес в индекс строки, разделив на 64, затем возьмём младшие 14 бит. Это значения от 0 до 16383. Таким образом, строка 0 отображается на группу 0, строка 1 на группу 1 и т.д. до группы 16383.
А вот группы 16384 в кэше уже нет, поэтому строка 16384 снова отобразится на группу 0, строка 16385 на группу 1, и т.д.
Значит, меняя адреса с шагом 16384 * 64, мы будем постоянно попадать на группу 0, и в этой группе будет происходить повышенное количество вытеснений. Другие группы остаются свободны, но кэш не может их задействовать из-за жёстко заданного соответствия адресов и групп.
16384 * 64 = 1048576. Это и есть наша магическая константа.
Выводы
Дописать до конца не удалось, получилось слишком много материала. Продолжим в следующем выпуске. А пока выводы такие:
В общем и целом, без разницы, как выровнены ваши данные, если они полностью умещаются в кэш. Выравнивание данных по определённым границам адресов, таким как 64 байта или 1048576 байт, может привести к ухудшению производительности либо из-за неэффективного использования строк кэша, либо из-за перегрузки одной группы кэша.