Занимаясь программированием, вы можете никогда не встретить понятие "адрес". Если речь о языках высокого уровня типа Java или Python, то там достаточно только имён переменных. У каждой переменной есть свой адрес в памяти, но эта информация нас совершенно не волнует.
Программируя на более низкоуровневом языке C, можно также обойтись без знаний об адресах. Однако в некоторых случаях эти знания оказываются нужными и важными.
Архитектура вычислительного комплекса
Мы знаем, что процессоры могут быть 8-битными, 16-битными, 32-битными и т.д. На деле это относится не столько к процессору, сколько ко всему вычислительному комплексу, который состоит из банков памяти, шины данных, различных кешей и т.п. Разрядность шины данных определяет, какими порциями данных все эти части комплекса могут обмениваться между собой. В случае 32 бит обмен идёт кусками по 32 бита. Такой кусок называется машинным словом.
Хорошо, но может ли процессор прочитать не 32 бита, а например 8 бит? Да, может, но так как ширина шины данных равна 32 бита, то столько он и прочитает, а затем отбросит ненужное. Это происходит фактически бесплатно, так как данный механизм встроен непосредственно в аппаратную часть.
Накладывается ограничение и на то, к каким адресам может обращаться процессор. Например, расположим в памяти последовательно два машинных слова по 32 бита. Первое будет располагаться по адресу 0, а второе по адресу 4.
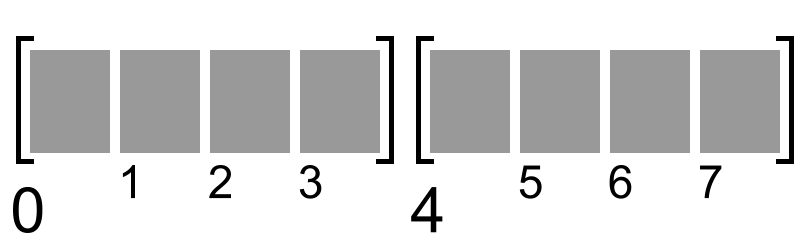
Процессоры некоторых архитектур (в основном это не братья Intel) физически неспособны обратиться к адресам 1, 2 или 3, а только к 0, 4, 8, и т.д.
Процессоры Intel позволяют обратиться к любому адресу. Но это будет не бесплатно. Посмотрим, что произойдёт:
Если мы читаем 32 бита начиная с адреса 0 или адреса 4, то все эти биты умещаются в одно машинное слово. Если же читаем начиная с адреса 1, то вот что нам пришлось бы сделать.
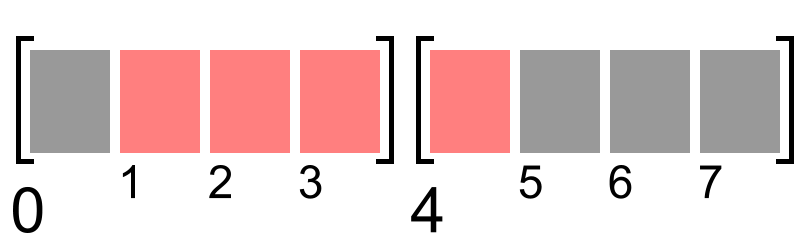
В нашем примере байты расположены в памяти от младшего к старшему. А биты внутри машинного слова записываются от старшего к младшему, то есть в обратном порядке.
Пусть это вас не путает. Это только стандарт записи, а не физическое расположение. Таким образом, сдвиг вправо в битовой записи означает движение в сторону младшего байта.
Нужно взять слово из адреса 0 и сдвинуть его вправо на 8 бит:
Далее нужно взять слово из адреса 4 и сдвинуть его влево на 24 бита:
Далее нужно сложить два значения, чтобы получить финальное:
Всё это и делает процессор, полностью автоматически и поэтому незаметно для пользователя. Но вместо чтения одного машинного слова процессор читает два, чтобы слепить из них результат. А это несомненно повлияет на скорость выполнения программы.
Выравнивание адресов
Под выравниванием мы понимаем расположение переменных по таким адресам, чтобы они считывались за один раз. Эти адреса должны быть кратны размеру машинного слова. В случае 32 бит это 4 байта.
Рассмотрим сначала такой условный пример:
char a, b, c, d;
Здесь у нас 4 переменные по 1 байту, и в памяти они могут быть размещены друг за другом побайтово:
[abcd]
При этом, когда мы обращаемся к переменной a, 32-битный процессор читает все 4 байта, но отбрасывает лишнее, оставляя только младший байт (он же первый по порядку в памяти).
[a---]
Когда мы обращаемся к переменным b, c или d, всё уже не так просто: процессор должен не только отбросить лишнее, но и переместить биты в младший байт с помощью сдвига:
[-b--]
Однако же и это пока не очень страшно, так как операция чтения из памяти всё равно только одна.
Теперь рассмотрим такой случай:
char a;
int b;
При условии, что эти переменные расположены в памяти друг за другом, часть переменной b будет находиться в одном машинном слове, а часть в другом, и значит доступ к ней потребует дополнительной работы, как было описано выше.
Что делает компилятор?
Компилятор, естественно, понимает эти нюансы, и поэтому может нам помочь. Во-первых, он может поменять порядок расположения переменных в памяти:
int b;
char a;
В этом случае и a, и b будут расположены каждая в своём машинном слове.
Другое, что он может сделать, это добавить выравнивание к переменной a. Несмотря на то, что размер a равен одному байту, она будет занимать 4 байта, то есть целое машинное слово. Остальные 3 байта пропадут зря, но в наше время эти потери несущественны.
Мы не держим в программе миллионы 1-байтовых переменных, и тем более нет необходимости выравнивать каждую (только если мы специально захотим испортить себе жизнь).
Действительно ли нужно выравнивание?
Несмотря на всё изложенное и многократно подкреплённое материалами из сети, на современных процессорах Intel отсутствие выравнивания НИКАК не влияет на скорость. Да, это подтверждено тестами, в том числе моими.
Почему тогда надо обращать на это внимание? Дело тут, в первую очередь, в переносимости. Если вы хотите, чтобы ваша программа компилировалась и работала без проблем на разных процессорах, необходимо закладываться на возможность того, что эти процессоры будут поддерживать только выровненные адреса, либо будут работать быстрее с выровненными адресами.
Других причин на данный момент в общем-то нет. Извините, если разочаровал :)
Однако есть определённые ситуации, где выравнивание поможет, но для этого надо выполнить ряд условий. Мы рассмотрим их потом.
Работа со структурами
Итак, мы поняли, для чего (не) нужно выравнивание адресов, и также поняли, что компилятор позаботится об этом за нас. Так что волноваться не о чем.
Есть лишь один момент, где нужно поступать особенно осмотрительно. Это работа со структурами в языке C.
Объявив подобную структуру:
struct { char foo; int bar; }
можно сделать три предположения, которые могут оказаться как верными, так и неверными.
Предположение первое: размер структуры равен 5 байт (на 32-битной архитектуре). Он считается так: 1 байт на поле foo и 4 байта на поле bar.
Предположение второе: адрес поля bar внутри структуры не выровнен по границе машинного слова (из-за того, что перед ним один байт занимает foo) и следовательно доставит нам проблем.
Предположение третье: поле foo находится в памяти перед полем bar.
Что может быть на самом деле?
Во-первых, компилятор может переставить поля структуры местами, поставив foo после bar. (Примечание из комментариев: стандарт языка C не подразумевает перестановки полей структуры, но я оставляю это здесь как более общий пример.)
Во-вторых, компилятор может выровнять адрес bar по границе машинного слова, добавив лишние байты после foo.
Соответственно, размер структуры может стать не 5 байт, а 8 байт.
Как уменьшить неопределённость в этом вопросе?
Во-первых, чтобы точно узнать размер структуры, мы должны не просто складывать размеры полей, а запрашивать его через sizeof().
Во-вторых, мы можем самостоятельно отсортировать поля структуры так, чтобы самое длинное шло впереди, а более мелкие были сгруппированы вместе, чтобы занимать целое машинное слово:
struct { int a; char x, y, z, w; }
Компилятор не будет менять их местами, так как они и так уже сгруппированы оптимально. Но это не всегда приемлемо с точки зрения логики, то есть человеку было бы удобнее видеть эти поля в другом, неоптимальном порядке. В этом случае нужно указать их так, как надо, и отдать остальное на откуп компилятору, который добавит выравнивание или неявно поменяет поля местами.
Соответственно, если мы не уверены на 100%, что одно поле идёт впереди другого, то предполагать этого не должны. Однако мы можем схитрить. Например, если всю структуру сделать только из полей типа char или типа int, то их порядок никто и никогда не поменяет. Они все одинакового размера, так что переставлять их бессмысленно.
Также, когда вы рассуждаете в духе "этот цикл будет выполняться всего 100 раз, заведу для него переменную типа char, больше ведь не надо", вспомните о том, что для обработки char 32-битному или 64-битному процессору нужно на самом деле совершить больше работы (пусть и незаметной). И прекратите экономить на спичках :)
Читайте дальше: