
Современные нейросети стали основой почти каждой технологической сферы — от компьютерного зрения до обработки языка. Основным способом их обучения является метод обратного распространения ошибки (back-propagation). Но недавно появилось исследование, предлагающее кардинально новый подход, который не использует ни forward-, ни back-propagation. Давайте подробно разберём этот революционный метод, названный авторами NoProp, и обсудим, почему он заслуживает внимания.
🧠 Что такое NoProp и почему это важно?
NoProp — это совершенно новый алгоритм обучения нейросетей, который не использует классический подход с последовательным распространением сигналов вперёд и обратно.
Почему это интересно?
- 🕸️ Отсутствие необходимости в back-propagation:
Метод обратного распространения градиента требует хранения множества промежуточных результатов и прохождения по сети в обе стороны, что снижает скорость и увеличивает затраты ресурсов. - 📉 Отказ от forward-propagation:
Нет необходимости и в прямом прохождении сети при обучении, что ещё больше сокращает затраты на память и вычислительную мощность. - 🔗 Каждый слой обучается независимо:
NoProp позволяет тренировать каждый слой сети отдельно и независимо. Это существенно упрощает распределённое и параллельное обучение, ускоряя его.
📌 Как работает метод NoProp? Технические детали
Метод NoProp вдохновлен принципами диффузионных моделей и подходами flow matching. Вот как работает NoProp:
🔹 Фиксация целевых представлений слоёв: Каждый слой нейросети не строит своё представление на основе предыдущих слоёв. Вместо этого ему заранее задаётся зашумлённое представление целевой метки. Задача слоя — очистить (дешумировать) полученное представление, приближаясь к истинной метке.
🔹 Схема работы (технически):
- Сначала берётся случайный шум (обычно Гауссовский).
- Каждый слой сети последовательно трансформирует этот шум в более чёткое представление.
- В конце последний слой должен выдавать предсказание класса объекта.
🔹 Тренировка слоёв (без forward- и back-propagation):
- Каждый слой тренируется независимо, получая на вход зашумлённые данные.
- Слой учится очищать данные от шума, предсказывая реальную метку.
- Веса слоёв оптимизируются независимо от остальных слоёв.
Таким образом, мы получаем модель, в которой информация не обязана проходить всю сеть вперёд и назад — это экономит вычисления и позволяет эффективно распараллеливать процесс.
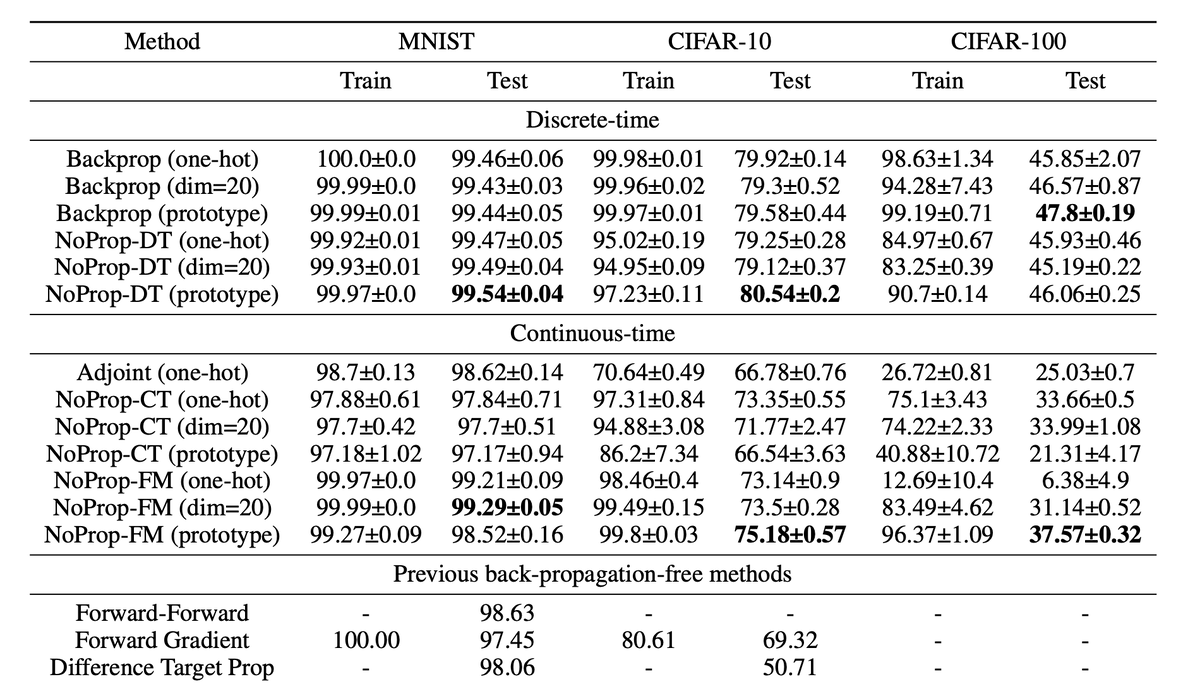
📊 Результаты экспериментов и сравнение с другими методами
Авторы исследования протестировали метод на популярных датасетах (MNIST, CIFAR-10 и CIFAR-100). Результаты впечатляющие:
- ✅ Сравнение с Backpropagation:
NoProp показал точность, сопоставимую с классическим методом, при этом существенно выигрывая по вычислительной эффективности и потреблению памяти. - ✅ Сравнение с другими альтернативными методами:
NoProp существенно превосходит другие методы обучения без back-propagation, такие как Forward-Forward, Difference Target Propagation и эволюционные стратегии. - ✅ Эффективность и простота:
Авторы демонстрируют, что NoProp не только быстрее, но и проще в реализации.
🧪 Дополнительные вариации метода
В статье авторы предлагают несколько интересных вариантов:
- 🌀 Непрерывные диффузионные модели и нейронные ODE: Позволяют плавно и непрерывно трансформировать шумовые данные к целевым меткам.
- 🌊 Flow matching: Альтернативный подход, явно задающий поток преобразования зашумлённой метки к чистой.
- 📐 Различные способы инициализации и обучения embeddings меток: Можно использовать фиксированные one-hot эмбеддинги или обучать представления меток вместе с моделью, что повышает качество обучения.
💡 Авторский взгляд: зачем и кому это нужно?
На мой взгляд, метод NoProp является крайне важным не только с точки зрения теоретических исследований, но и для практического применения в реальных проектах. В условиях постоянно растущих данных и моделей:
- 🚀 Эффективность:
Снижение затрат на память и ускорение обучения особенно актуально для больших моделей и больших объёмов данных. - 🔮 Новые подходы к параллельному и распределённому обучению:
Благодаря независимости обучения слоёв, NoProp идеально ложится на архитектуры многопроцессорных систем и распределённого обучения. - 🌟 Переосмысление представлений:
Отход от классических иерархических представлений может привести к новым открытиям в области representation learning и новых видов нейросетевых архитектур.
🎯 Выводы и перспективы
Метод NoProp — яркий пример того, как свежие идеи и нестандартные подходы способны открыть совершенно новую эру в глубоком обучении. В будущем можно ожидать новых архитектур нейросетей, построенных на таких принципах, что позволит ещё эффективнее решать сложные задачи машинного обучения.
Но самое важное — это исследование заставляет нас задуматься: а действительно ли иерархическое распространение информации необходимо? Возможно, мы стоим на пороге переосмысления самой концепции глубокого обучения.
🔗 Ссылка на источник:
✨ Читайте, вдохновляйтесь и исследуйте новое в машинном обучении!