Сначала хочу поздравить всех с Днём космонавтики! Напомню, что СССР был первым в космосе. Первым запустил спутник, первым вывел в космос человека.
Сегодня мир вступил в борьбу за другой «космос» — за искусственный интеллект, и нам важно не отстать в этом новом перспективнейшем направлении. И есть симптомы, что не отстаём.
26 ноября 2024 года была опубликована любопытная научная статья «Расширение границ квантования больших языковых моделей с помощью теоремы линейности» за авторством Владимира Малиновского (Яндекс, НИУ ВШЭ), Андрея Панферова (австрийский институт науки и технологий ISTA), Ивана Ильина и Петера Рихтарика (саудовский Научно-технологический университет имени короля Абдаллы KAUST), Хана Го (массачусетский технологический институт MIT) и Дана Алистарха (австрийский институт науки и технологий ISTA, компания Neural Magic) о более эффективном методе квантизации ИИ-моделей.
Квантизация — уменьшении точности, например, весов нейронной сети для оптимизации размера модели и ускорения её работы.
Представьте, что вы сжимаете фотографию из RAW в JPEG. Качество немного падает, но файл становится в разы, а то и на порядки меньше и быстрее загружается. Так и квантизация «сжимает» модель, жертвуя небольшой точностью ради эффективности.
Ранее для запуска языковой модели на смартфоне или ноутбуке требовалось провести ее качественную квантизацию на дорогостоящем сервере, что занимало от нескольких часов до несколько недель.
Теперь квантизацию можно выполнить даже на телефоне или ноутбуке за считанные минуты. Фактически, разработан метод быстрого сжатия больших языковых моделей, причём без существенной потери их качества.
С помощью нового метода можно сжимать даже такие большие модели, как DeepSeek-R1 на 671 млрд параметров и Llama 4 Maverick на 400 млрд параметров, которые до сих пор удавалось квантизировать только самыми простыми методами со значительной потерей в качестве.
Метод, получивший название HIGGS (от англ. Hadamard Incoherence with Gaussian MSE-optimal GridS), позволяет быстро тестировать и внедрять новые решения на основе нейросетей, экономить время и деньги на разработку.
Это делает большие языковые модели (LLM) доступнее не только для крупных, но и для небольших компаний, некоммерческих лабораторий и институтов, индивидуальных разработчиков и исследователей.
Чуть подробнее
В упоминаемой работе представлена «теорема линейности», устанавливающая прямую связь между ошибкой реконструкции слоя (ℓ²) и ростом перплексии модели из-за квантизации.
Это открытие позволяет предложить бескалибровочный метод квантизации HIGGS (преобразования Адамара + оптимальные сетки по MSE), превосходящий популярные форматы вроде NF4 и оптимально распределять биты между слоями с помощью динамического программирования.
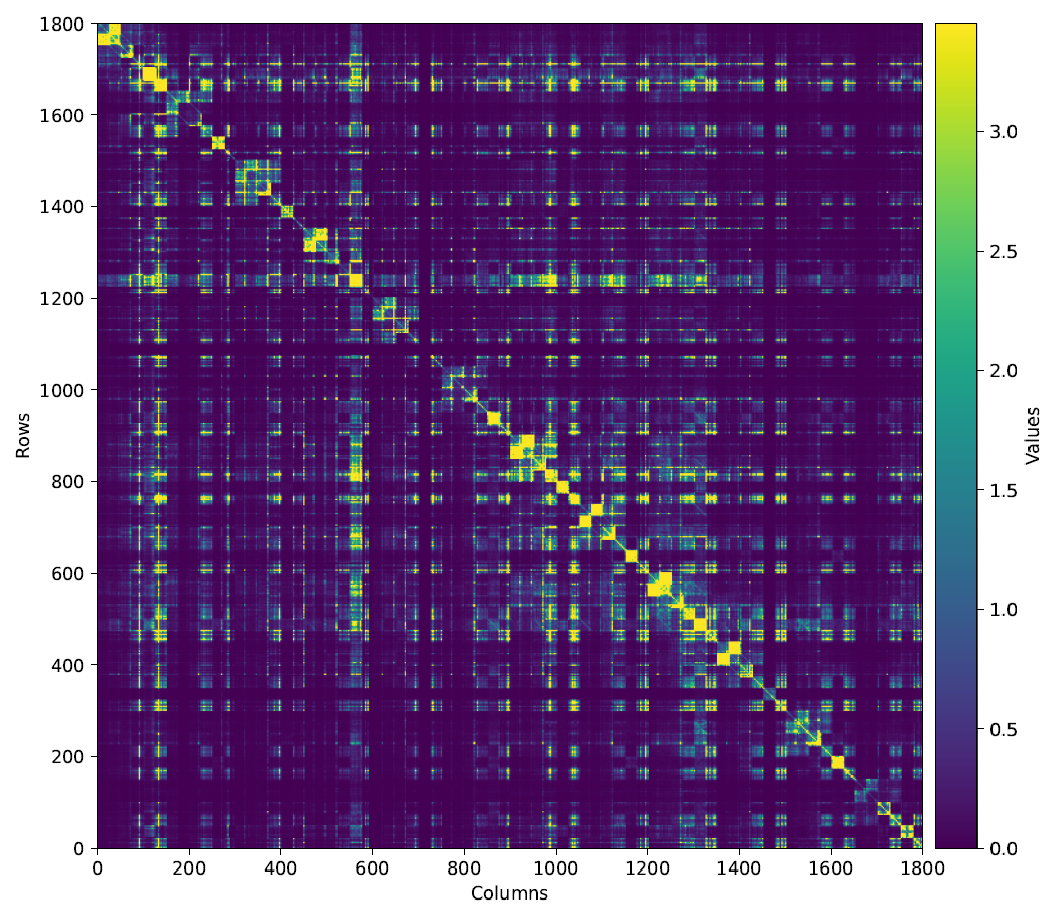
Эксперименты на моделях Llama-3.1, Llama-3.2 и Qwen демонстрируют улучшенный баланс точности и сжатия. Метод эффективно реализуется на GPU с ускорением в 2–3× относительно FP16.
Это лучший способ квантизации по соотношению качества к размеру модели среди всех существующих методов квантизации без использования данных, в том числе NF4 (4-bit NormalFloat) и HQQ (Half-Quadratic Quantization).
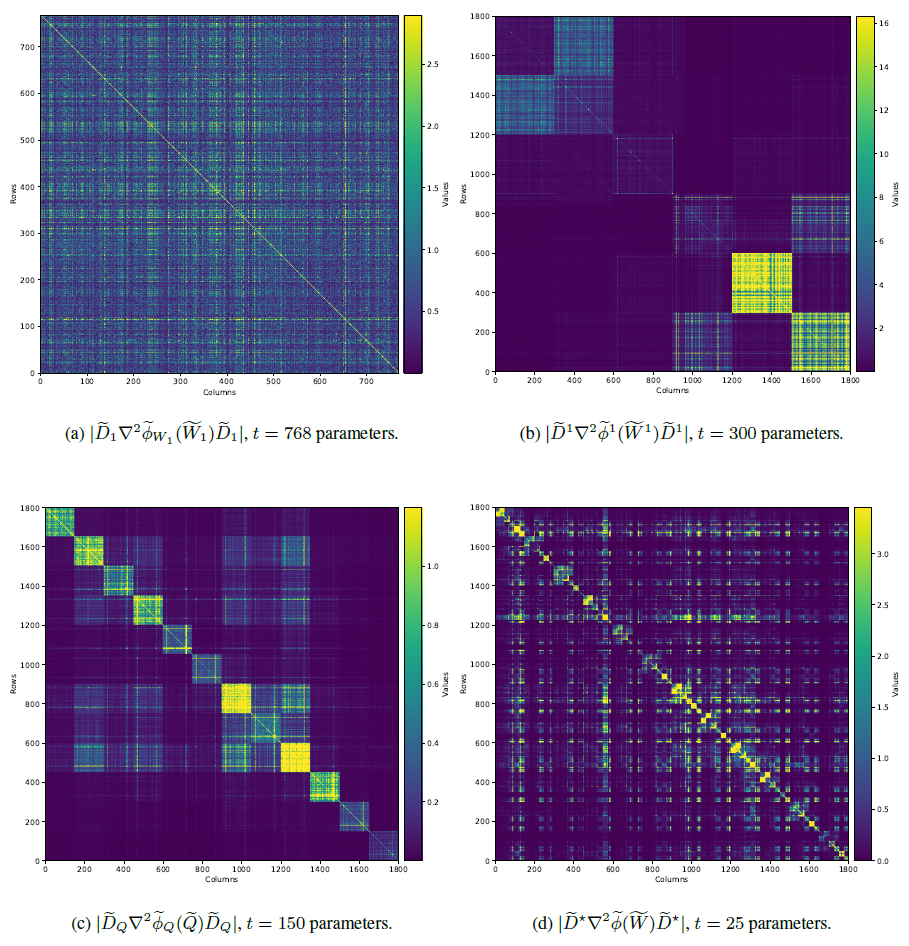
Преобразование Адамара делает веса гауссовыми. Векторная квантизация использует оптимальные сетки (CLVQ). В результате HIGGS (p=2) снижает перплексию на WikiText-2 на 15% относительно NF4.
Ограничения:
- Размер сетки ограничен памятью GPU (до 1024 точек).
- Для высоких бит (8 бит) используется равномерная квантизация (CH8).
Метод HIGGS уже доступен разработчикам и исследователям на Hugging Face и GitHub.
Заключение
Вышеописанную научную статью с описанием нового метода уже приняли на одну из крупнейших в мире ИИ-конференций The North American Chapter of the Association for Computation Linguistics (NAACL), которая пройдёт с 29 апреля по 4 мая в Альбукерке (штат Нью-Мексико, США).
Научную статью также цитировали американская компания Red Hat AI, Пекинский университет, Гонконгский университет науки и технологий и др.
Практическая демонстрация результата научной работы и наличие открытого исходного кода проекта говорит нам о том, что её скоро будут применять на практике, причём довольно широко, а её авторство свидетельствует о том, что математической базой искусственного интеллекта, его фундаментом, всё же занимаются сообща «всем миром».
Ранее я думал, что такие вещи растаскиваются по «полюсам», по зонам влияния, а научные разработки такого уровня не публикуются. Но, видимо, искусственный интеллект всё же будет общим, а различия будут только в подборе материала для его обучения.
На сегодня всё. Ставьте нравлики, делитесь своими мыслями в комментариях и подписывайтесь на мой канал! Удачи! :-)
Кстати, канал можно (и нужно! :-)) поддерживать донатами!