"Это революция, мир уже никогда не будет прежним, конкурентам гибель". Может быть, но "Jamba" мало того, что ни хранит историю чатов, или ее ближайшим образом не найти, но и по теперешним меркам, иногда, во всяком случае, отвратительно пишет код. Короче Jamba, в известном смысле, рядом не стояла, пока, с 4о. И по интерфейсу пользователя, и, по сути дела. Тесты, скамейки, марки, это все хорошо может быть, тем не менее, пользовательский опыт может быть совсем иное. Но на вход действительно принимает много знаков. Впрочем, платный GPT 4 и 4о1 таким же образом довольно давно уже принимал до 128 страниц. Последняя LLAMA 4 и тем более станет до миллиона токенов. Выход мал! То есть, и эта сеть, "Jamba", не пишет книг. И видимо все остальные, все еще, не будут. Более того, развернутую статью, вряд ли напишет, без прерываний. Тем не менее, что-то в этом есть, может быть. "Jamba" в свободном доступе, в отличие от LLama, что может быть ограничена в доступе и по географическому признаку. Внимание в сетях использовалось и до GPT. В 2015 году в Германии появилась статья о нем, кроме прочего. На это "кроме прочего" есть отсылка в знаменитой статье 2017. Но разница, была в том, что "все что вам нужно", из внимания, свертывания и рекуррентной архитектуры, "это внимание" в трансформерах, много голов такого в этой архитектуре. О чем, частью, прямо и говориться в названии статьи 2017. Jamba, вновь объединяет, между тем, рекуррентные архитектуры и трансформеры. Синтезируя в синергии достоинства "Мамбы" ("Чтобы обеспечить работу с длинными последовательностями данных, в Mamba используется модель последовательностей структурированного пространства состояний (S4). [2] S4 может эффективно и результативно моделировать длительные зависимости, комбинируя непрерывно временные, рекуррентные и свёрточные модели. Это позволяет ему обрабатывать данные с нерегулярной выборкой, неограниченным контекстом и оставаться эффективным в вычислительном отношении во время обучения и вывода. [5] См. Википедия Мамба, архитектура глубокого обучения.) и преимущества трансформеров, вернее разряженных трансформеров (MoE).( MoE это вариант разряженного трансформера, что состоит из экспертных нейронных сетей, коль скоро, такие сети специализированы для выполнения особого рода задач. Плюс, включает в себя подобие маршрутизатора, управляющего входными данными и направляющего их к соответствующему "эксперту". Архитектура повышает производительность модели, разделяя выполнение решения задач между отдельными частями сети, и да, позволяет сети быть гораздо более простым и "естественным" образом мультимодальной, во всяком случае, в виду рекламы, и в виде LLama 4) Может быть, это и хорошо, отрицание отрицания. Но результат пока не во всем соответствует возможным релизам и восторгам, в виду Джамбы. Эта сеть мало мультимодальна и да, все еще, на пути к 4о. (И надо сказать, и LLama 4, даже и не сравнивается с 4о3.) Один противоположный пример говорили, и все, пиши пропало. Он есть и может быть. Впрочем, претензии к железу, мол, все перебьют. Но по опыту автора, 4о, из сети, работает без ошибок, если ни сказать на любом аппаратном обеспечении, то на том, что не старше 2015.
Это пример кода, мол, оптимизированного сетью Jamba.
Function GouacheFilter3(ByVal sourceImage As Bitmap) As Bitmap
' Создаем новый объект Bitmap с такими же размерами, как и исходное изображение
Dim resultImage As New Bitmap(sourceImage.Width, sourceImage.Height)
' Задаем параметры фильтра
Dim radius As Integer = 5 ' Радиус окрестности пикселя
Dim intensity As Double = 0.8 ' Интенсивность эффекта
Dim threshold As Double = 0.1 ' Порог разницы цветов
' Проходим по всем пикселям изображения
Parallel.For(0, sourceImage.Width, Sub(x)
Parallel.For(0, sourceImage.Height, Sub(y)
' Получаем индекс текущего пикселя
Dim index As Integer = y * sourceImage.Width + x
' Получаем цвет текущего пикселя
Dim sourceColor As Color = sourceImage.GetPixel(x, y)
' Инициализируем переменные для суммы цветов и количества пикселей в окрестности
Dim sumR As Integer = 0
Dim sumG As Integer = 0
Dim sumB As Integer = 0
Dim count As Integer = 0
' Проходим по окрестности текущего пикселя
For i As Integer = -radius To radius
For j As Integer = -radius To radius
' Проверяем, что координаты соседнего пикселя не выходят за границы изображения
If x + i >= 0 AndAlso x + i < sourceImage.Width AndAlso y + j >= 0 AndAlso y + j < sourceImage.Height Then
' Получаем цвет соседнего пикселя
Dim neighborColor As Color = sourceImage.GetPixel(x + i, y + j)
' Вычисляем разницу между цветами текущего и соседнего пикселей
Dim difference As Double = (Math.Abs(sourceColor.R - neighborColor.R) + Math.Abs(sourceColor.G - neighborColor.G) + Math.Abs(sourceColor.B - neighborColor.B)) / 255.0
' Если разница меньше порога, то добавляем цвет соседнего пикселя к сумме и увеличиваем количество пикселей в окрестности
If difference < threshold Then
sumR += neighborColor.R
sumG += neighborColor.G
sumB += neighborColor.B
count += 1
End If
End If
Next
Next
' Если количество пикселей в окрестности больше нуля, то вычисляем средний цвет окрестности
If count > 0 Then
sumR \= count
sumG \= count
sumB \= count
End If
' Вычисляем новый цвет пикселя как линейную комбинацию исходного и среднего цветов окрестности с заданной интенсивностью
Dim resultR As Integer = CInt((1 - intensity) * sourceColor.R + intensity * sumR)
Dim resultG As Integer = CInt((1 - intensity) * sourceColor.G + intensity * sumG)
Dim resultB As Integer = CInt((1 - intensity) * sourceColor.B + intensity * sumB)
' Создаем новый цвет пикселя с учетом альфа-канала
Dim resultColor As Color = Color.FromArgb(sourceColor.A, resultR, resultG, resultB)
' Устанавливаем новый цвет пикселя для результирующего изображения
resultImage.SetPixel(x, y, resultColor)
End Sub)
End Sub)
' Возвращаем результирующее изображение
Return resultImage
End Function
Строка Dim index As Integer = y * sourceImage.Width + x генерирует ошибку о том, что объект находиться, используется, где-то там еще. System.InvalidOperationException: "Object is currently in use elsewhere."
И далее по кругу, попытка сети исправить ошибку приводит к другим. И видимо те, могут привести к еще большим. То есть, локальный минимум даст себя знать в полную меру. Но даже, если это был локальный максимум, тем более, сети не выбраться. Для нее, это предел. Это старая история до времени 4о, во всяком случае, то же было и с GPT 4 в Бинг, если это был GPT 4. Да и иные сети и самая продвинутая из них, кроме Open AI, компании Antrophic, таким образом не правила ошибки, создавая их. Тем не менее, решение компаниями было найдено, количество ошибок свелось к действительному минимуму, и к минимуму значимости таких ошибок, с тем чтобы их не исправлять, или исправлять автоматически, ни долго и просто. Но машины, ближайшим образом, тогда, не правили ошибки. И когда ИИ стал исправлять код, это было своеобразной отсечкой. Модернизация 4о вдохновила в этом смысле. Теперь, и Cloud, и Gemini, большей частью исправляют их, но скорее, все же, не создавая, чем исправляя. Впрочем модели постоянно совершенствуются. Gemini 2, 5 Pro может быть хорош, даже в модернизации кодов, что были созданы с ошибками другими моделями.
Зачем писать "задайте любой вопрос", – если это не так, и любой вопрос не пройдет, просто и не просто, в виду цензуры и политики охранения ИИ? Задайте подходящий вопрос, правильный, и т.д., было бы вернее. Но нет реклама! И надо сказать пустая. В 2023 году удалось довести сеть Бинг вопросами так, что появилось сообщение дисклеймер к этой строке "задай любой вопрос". Мол вопросы следует задавать не любые, а те, что указаны в примерах, демонстрируемых на интерфейсе пользователя сервиса. И просить создать код программы генератора книг и статей, с кодом по правилам, не стоит. И да была такая сильная видимость, что это вмешался человек. Настолько формат послания отличался от потокового. С тех пор что-то произошло, верно, но что то, так и осталось тем же. Сети не пишут развернутые тексты, сопоставимые с 100-й страниц, тем более за одну минуту. Впрочем, интерфейс «Джамбы» не содержит такой глупости, вроде предложения задать любой вопрос, что не спасает сервис от нее в иных отношениях. Автоматизация счетно-вычислительных задач, многократно усиленный калькулятор, почему не сказать правду о "ИИ"?
2.
Далее, реклама, видимо торгетированная, нейронной сети "Jamba" от нейронной сети "Gemini 2,5".
«Jamba: Революционная Гибридная Языковая Модель от AI21 Labs
В динамично развивающемся мире искусственного интеллекта и больших языковых моделей (LLM) постоянно появляются новые архитектуры, стремящиеся преодолеть ограничения существующих подходов. Одной из самых заметных недавних инноваций стала Jamba, разработанная израильской компанией AI21 Labs. Jamba выделяется своим уникальным гибридным подходом, комбинируя сильные стороны проверенных временем Трансформеров (Transformers) с новейшими разработками в области моделей на основе пространства состояний (State Space Models - SSM), в частности, архитектурой Mamba, и используя технику Mixture of Experts (MoE) для повышения эффективности.
Эта статья представляет собой развернутый обзор Jamba, её ключевых особенностей, архитектуры, преимуществ, потенциальных применений и значения для будущего LLM.
1. Что такое Jamba?
Jamba — это большая языковая модель нового поколения, представленная AI21 Labs в марте 2024 года. Её главная отличительная черта — это первая в своем роде гибридная архитектура, которая интегрирует элементы Трансформеров и Mamba в единую блочную структуру. Кроме того, Jamba использует MoE для оптимизации вычислений. Модель была выпущена с открытыми весами под лицензией Apache 2.0, что способствует её доступности для исследователей и разработчиков.
2. Ключевые Особенности и Инновации:
Гибридная Архитектура (Transformer + Mamba/SSM):
Трансформеры: Основа большинства современных LLM (GPT, Llama, BERT). Отлично справляются с улавливанием сложных взаимосвязей в данных благодаря механизму внимания (self-attention), но имеют квадратичную вычислительную сложность по отношению к длине последовательности, что ограничивает размер контекстного окна и увеличивает затраты на обработку длинных текстов.
Mamba (и другие SSM): Новый класс моделей, демонстрирующий линейную или почти линейную сложность по отношению к длине последовательности. Mamba эффективна при обработке очень длинных контекстов и показывает отличные результаты в задачах, требующих запоминания информации на больших расстояниях. Однако её способность к улавливанию сложных локальных паттернов может быть иной, чем у Трансформеров.
Синергия в Jamba: Jamba чередует слои Трансформера и Mamba. Идея состоит в том, чтобы использовать лучшие качества обеих архитектур: мощь Трансформеров для глубокого понимания взаимосвязей и эффективность Mamba для обработки длинных последовательностей и снижения вычислительной нагрузки. Каждый блок Jamba может содержать один или несколько слоев Трансформера или Mamba, активируемых с помощью MoE.
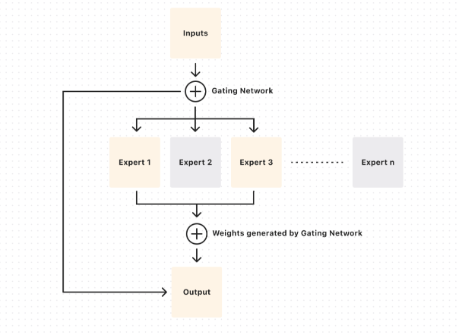
Mixture of Experts (MoE):
Эта техника позволяет модели иметь очень большое общее количество параметров, но активировать только их небольшую часть для обработки каждого входного токена.
В Jamba используется MoE как для слоев внимания и прямого распространения (feed-forward) в Трансформер-части, так и для слоев Mamba.
Модель имеет 16 "экспертов", из которых для каждого токена выбираются только 2. Это значительно снижает вычислительные затраты во время инференса (использования модели) по сравнению с плотной моделью аналогичного общего размера. Jamba имеет общее число параметров около 52 миллиардов, но активных параметров для обработки токена — около 12 миллиардов.
Огромное Контекстное Окно (256 000 токенов):
Благодаря эффективности гибридной архитектуры и Mamba, Jamba поддерживает одно из самых больших контекстных окон на момент своего выпуска — 256 тысяч токенов.
Это позволяет модели обрабатывать и анализировать очень длинные документы, книги, кодовые базы или вести продолжительные диалоги, сохраняя контекст на протяжении всего взаимодействия.
Эффективность:
Комбинация MoE и Mamba делает Jamba значительно более эффективной по сравнению с традиционными Трансформерами сопоставимого размера.
AI21 Labs заявляет, что Jamba обеспечивает высокую пропускную способность и может поместиться на одной стандартной GPU (например, с 80 ГБ видеопамяти), что делает её доступной для более широкого круга пользователей и организаций.
Открытая Модель:
Предоставление весов модели под пермиссивной лицензией Apache 2.0 позволяет сообществу свободно использовать, изучать и дорабатывать Jamba, способствуя инновациям и демократизации мощных ИИ-инструментов.
3. Технические Аспекты Архитектуры:
Архитектура Jamba строится из блоков, где каждый блок содержит либо слой Трансформера, либо слой Mamba. Решение о том, какой тип слоя использовать, может быть частью дизайна или управляться динамически. Внутри Трансформер-слоев используется механизм внимания и многослойные перцептроны (MLP), которые также могут быть реализованы как MoE-слои. В Mamba-слоях используется механизм, основанный на пространствах состояний, для эффективной обработки последовательностей. Маршрутизатор (router) в MoE-слоях определяет, какие "эксперты" (нейронные сети) будут обрабатывать данный токен.
4. Преимущества Jamba:
Баланс Производительности и Эффективности: Предлагает качество, сравнимое с большими монолитными моделями, при значительно меньших вычислительных затратах на инференс.
Обработка Длинных Контекстов: Окно в 256k токенов открывает новые возможности для анализа больших объемов информации.
Высокая Пропускная Способность: MoE и Mamba способствуют более быстрой обработке данных.
Доступность: Возможность запуска на одной GPU и открытые веса делают модель более доступной для исследований и практического применения.
Инновационность: Демонстрирует потенциал гибридных архитектур, выходя за рамки доминирования чистых Трансформеров.
5. Потенциальные Применения:
Благодаря своим характеристикам, Jamba подходит для широкого спектра задач:
Анализ и Суммаризация Длинных Документов: Отчеты, юридические тексты, научные статьи, книги.
Чат-боты и Виртуальные Ассистенты: Поддержание контекста в длительных и сложных диалогах.
Генерация и Анализ Кода: Работа с большими репозиториями и сложными проектами.
Креативное Письмо: Создание длинных повествований с сохранением сюжетной линии и деталей.
Исследования и Разработка: Изучение возможностей гибридных архитектур, тонкая настройка (fine-tuning) для специфических задач.
6. Сравнение с Другими Моделями:
Vs. Традиционные Трансформеры (GPT-4, Llama): Jamba стремится предложить сопоставимое качество при лучшей эффективности и значительно большем контекстном окне.
Vs. Другие MoE Модели (Mixtral 8x7B): Jamba отличается использованием гибридной архитектуры (Transformer + Mamba), в то время как Mixtral основан исключительно на Трансформерах.
Vs. Чистые SSM/Mamba Модели: Jamba пытается компенсировать потенциальные слабости Mamba, интегрируя проверенные возможности Трансформеров.
7. Ограничения и Вызовы:
Сложность Архитектуры: Гибридный дизайн и MoE могут усложнять обучение и тонкую настройку модели.
Новизна: Как относительно новая архитектура, она требует дальнейшего изучения и тестирования в реальных условиях для полного понимания её сильных и слабых сторон.
Общие Ограничения LLM: Как и все LLM, Jamba подвержена риску генерации неточной информации (галлюцинаций), предвзятости, унаследованной из данных обучения, и требует значительных ресурсов для обучения (хотя инференс более эффективен).
Интерпретация Бенчмарков: Хотя Jamba показывает хорошие результаты на стандартных бенчмарках, её реальная производительность в специфических задачах может варьироваться.
8. Значение и Будущее:
Jamba представляет собой важный шаг в эволюции языковых моделей. Она демонстрирует, что будущее LLM может лежать не только в масштабировании существующих архитектур, но и в инновационном комбинировании различных подходов. Успех Jamba может стимулировать дальнейшие исследования гибридных моделей, сочетающих Трансформеры, SSM, и другие перспективные архитектуры (например, рекуррентные сети, сверточные сети).
Открытость модели также играет ключевую роль, позволяя сообществу быстро проверять, адаптировать и улучшать новую технологию, ускоряя общий прогресс в области ИИ.
Заключение:
Jamba от AI21 Labs — это не просто еще одна большая языковая модель. Это смелый эксперимент и значительное достижение в области архитектуры ИИ. Сочетая Трансформеры, Mamba и MoE, Jamba предлагает уникальный баланс производительности, эффективности и способности работать с огромными объемами контекста. Её появление открывает новые горизонты для приложений ИИ и задает интригующее направление для будущих исследований в области создания более мощных и доступных языковых моделей».
Было бы неплохо, если бы сеть предоставляла в конце оценку достоверности текста, что создала. Желательно по темам и частям. И, да, благодаря, как раз, возможной экспертной составляющей. Это могло бы реально помочь пользователю в том, в каком направлении ему стоит, все еще искать информацию в сети для нахождения более детального, правдоподобного и стремящегося к правдивой истине ответа. Теперь же, ситуация может быть и анекдотической, сеть принимающая на вход миллион токенов, слов, а вернее ее создатели, словно принуждает пользователя прочитать порядка 30 книг по 300 страниц каждая, с тем, чтобы после проверить, не допустила ли сеть ошибки, – а ведь сеть может допускать их, и потому пользователю следует проверять выходные данные, по всем известному дисклеймеру, – при сокращении такого текста из 30 книг, в выжимку из трех, в лучшем случае 10 страниц.
«СТЛА»
Караваев В.Г.